Source: MachineLearningMastery.com
A few years ago, training AI models required massive amounts of labeled data. Manually collecting and labeling this data was both time-consuming and expensive. But thankfully, we’ve come a long way since then, and now we have much more powerful tools and techniques to help us automate this labeling process. One of the most effective ways? Active Learning.
In this article, we’ll walk through the concept of active learning, how it works, and share a step-by-step implementation of how to automate dataset labeling for a text classification task using this method.
What is Active Learning and How Does it Work?
What happens in a typical supervised learning setup? You have a fully labeled dataset, you train a model where every data point has a known outcome. Right? But unfortunately, in many real-world scenarios, getting all those labels can be really hard. That’s where active learning comes in.
It’s a form of semi-supervised learning where the algorithm can actually ask for help—querying a human annotator or oracle to label specific data points. But here’s the twist: instead of picking data points at random, active learning selects the ones that are most useful for improving the model. These are usually the samples the model is least confident about. Once those uncertain data points are labeled (usually by humans), they’re fed back into the model to retrain it. This cycle repeats—each time making the model better with minimal human input.
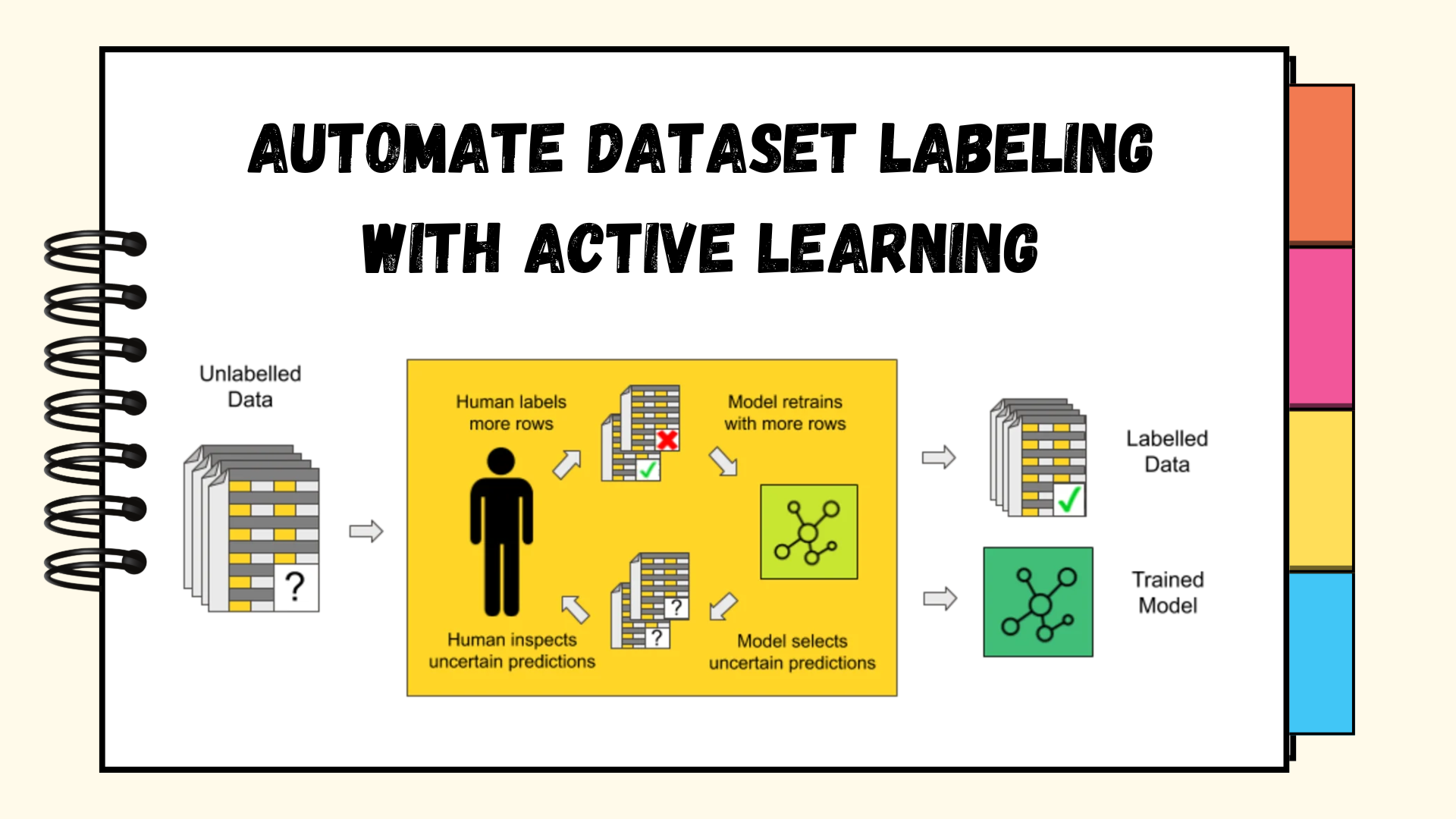
Here’s a visual from the KNIME Blog that sums up how it works:

KNIME Blog – Active Learning Working
Key Concepts in Active Learning
Let’s quickly go over some of the key concepts and terminology—just so you don’t get confused when I start using them later on in the implementation phase.
- Unlabeled Pool: The pool of data points that the model has not seen yet
- Labeled Data: The dataset that the model has learned from, which has labels provided by humans
- Labeling Oracle: The external source or human expert who provides labels for the selected data points.
- Query Strategy: The method by which the model selects data points to be labeled. Common strategies include:
- Uncertainty Sampling: Selects the instances where the model is most uncertain (i.e., where the model has predictions with high entropy)
- Random Sampling: Randomly selects data points for labeling
- Diversity Sampling: Chooses samples that are diverse from the existing labeled data to improve coverage of the feature space
- Query-by-Committee: Uses multiple models to vote on samples where disagreement is highest
- Expected Model Change: Identifies samples that would cause the greatest change to the current model parameters if labeled
- Expected Error Reduction: Selects samples that would minimize expected error on the unlabeled pool
Practical Implementation of Active Learning with a Text Classification Task
To better understand how Active Learning works in practice, let’s walk through an example where we use it to improve a text classification model using a dataset of news articles. The dataset contains two categories of news: atheism and Christianity, which will be used for binary classification. Our goal is to train a classifier to predict these two categories, but we will only label a small portion of the data initially, with the remaining data being queried for labeling based on uncertainty or randomness. You can choose any based on the nature of the dataset and your goals.
Step 1: Setup and Initial Data Preparation
We’ll start by installing the necessary libraries and loading the dataset. For this, we’ll use a subset of the 20 newsgroups dataset and split the data into a training pool and a test set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
# Install required packages pip install scikit–learn numpy pandas matplotlib import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score import matplotlib.pyplot as plt import random from sklearn.datasets import fetch_20newsgroups # For reproducibility random.seed(42) np.random.seed(42) # Load a subset of the 20 newsgroups dataset (binary classification) categories = [‘alt.atheism’, ‘soc.religion.christian’] newsgroups = fetch_20newsgroups(subset=‘train’, categories=categories, remove=(‘headers’, ‘footers’, ‘quotes’)) # Create features and labels X = newsgroups.data y = newsgroups.target # Split into training and test sets from sklearn.model_selection import train_test_split X_pool, X_test, y_pool, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Initialize the vectorizer vectorizer = TfidfVectorizer(max_features=5000) # Convert test data to TF-IDF features X_test_tfidf = vectorizer.fit_transform(X_test) |
Step 2: Implement Active Learning Functions
Now, we define the key functions used in the active learning loop. These include uncertainty sampling, random sampling, and evaluation functions to track the performance of the model.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
def uncertainty_sampling(model, X_unlabeled, n_samples=10): “”“Select samples with highest uncertainty.”“” # Get probability predictions probas = model.predict_proba(X_unlabeled) # Calculate uncertainty (proximity to 0.5 probability) uncertainty = np.abs(probas[:, 0] – 0.5) # Get indices of most uncertain samples uncertain_indices = np.argsort(uncertainty)[:n_samples] return uncertain_indices def random_sampling(X_unlabeled, n_samples=10): “”“Select samples randomly.”“” return np.random.choice(len(X_unlabeled), n_samples, replace=False) def evaluate_model(model, X_test, y_test): “”“Evaluate model on test data.”“” y_pred = model.predict(X_test) return accuracy_score(y_test, y_pred) |
Step 3: Implement the Active Learning Loop
Now, let’s implement the active learning loop for a specified number of iterations, where the model selects samples, gets them labeled, and then retrains the model. We’ll compare uncertainty sampling and random sampling to see which strategy performs better on the test set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
def run_experiment(sampling_strategy, X_pool, y_pool, X_test, y_test, initial_samples=20, batch_size=10, iterations=10): “”“Run active learning experiment with specified sampling strategy.”“” # Copy the pool data to avoid modifying the original X_pool_copy = X_pool.copy() y_pool_copy = y_pool.copy() # Vectorize initial pool data X_pool_tfidf = vectorizer.transform(X_pool_copy) # Randomly select initial samples initial_indices = np.random.choice(len(X_pool_copy), initial_samples, replace=False) # Create initial labeled dataset X_labeled = X_pool_tfidf[initial_indices] y_labeled = np.array(y_pool_copy)[initial_indices] # Create mask for unlabeled data labeled_mask = np.zeros(len(X_pool_copy), dtype=bool) labeled_mask[initial_indices] = True # Initialize model model = LogisticRegression(random_state=42) # Initialize results tracking accuracies = [] num_labeled = [] # Train initial model model.fit(X_labeled, y_labeled) accuracies.append(evaluate_model(model, X_test_tfidf, y_test)) num_labeled.append(initial_samples) # Active learning loop for i in range(iterations): # Get unlabeled data X_unlabeled = X_pool_tfidf[~labeled_mask] # Select samples to label if sampling_strategy == ‘uncertainty’: # For uncertainty sampling, we need the current model indices_to_label_relative = uncertainty_sampling(model, X_unlabeled, batch_size) # Convert to absolute indices unlabeled_indices = np.where(~labeled_mask)[0] indices_to_label = unlabeled_indices[indices_to_label_relative] else: # random sampling unlabeled_indices = np.where(~labeled_mask)[0] indices_to_label = np.random.choice(unlabeled_indices, batch_size, replace=False) # Update labeled mask labeled_mask[indices_to_label] = True # Update labeled dataset X_labeled = X_pool_tfidf[labeled_mask] y_labeled = np.array(y_pool_copy)[labeled_mask] # Retrain model model.fit(X_labeled, y_labeled) # Evaluate and track results accuracy = evaluate_model(model, X_test_tfidf, y_test) accuracies.append(accuracy) num_labeled.append(np.sum(labeled_mask)) return num_labeled, accuracies |
Step 4: Run the Experiment and Visualize Results
Finally, we run our experiments with both uncertainty and random sampling strategies and visualize the accuracy results over time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Run experiments random_results = run_experiment(‘random’, X_pool, y_pool, X_test_tfidf, y_test) uncertainty_results = run_experiment(‘uncertainty’, X_pool, y_pool, X_test_tfidf, y_test) # Plot results plt.figure(figsize=(10, 6)) plt.plot(random_results[0], random_results[1], ‘b-‘, marker=‘o’, label=‘Random Sampling’) plt.plot(uncertainty_results[0], uncertainty_results[1], ‘r-‘, marker=‘*’, label=‘Uncertainty Sampling’) plt.xlabel(‘Number of Labeled Samples’) plt.ylabel(‘Accuracy’) plt.title(‘Active Learning vs Random Sampling’) plt.legend() plt.grid(True) plt.tight_layout() plt.show() # Print final results print(f“Final accuracy with Random Sampling: {random_results[1][-1]:.4f}”) print(f“Final accuracy with Uncertainty Sampling: {uncertainty_results[1][-1]:.4f}”) print(f“Improvement: {(uncertainty_results[1][-1] – random_results[1][-1]) * 100:.2f}%”) |
Output:
|
Final accuracy with Random Sampling: 0.6343 Final accuracy with Uncertainty Sampling: 0.7546 Improvement: 12.04% |

Output – Screenshot
Conclusion
We’ve just walked through Active Learning and used it to improve a text classification model. The idea is simple but powerful: instead of labeling everything, you focus only on the examples your model is most unsure about. That way, you’re not wasting time labeling data the model already understands — you’re targeting its blind spots. In real projects, that can save you a lot of hours and effort, especially when working with large datasets. Let me know what you think of this approach in the comments below!