
Source: MachineLearningMastery.com

A Gentle Introduction to Learning Rate Schedulers
Image by Author | ChatGPT
Ever wondered why your neural network seems to get stuck during training, or why it starts strong but fails to reach its full potential? The culprit might be your learning rate – arguably one of the most important hyperparameters in machine learning. While a fixed learning rate can work, it often leads to suboptimal results. Learning rate schedulers offer a more dynamic approach by automatically adjusting the learning rate during training.
In this article, you’ll discover five popular learning rate schedulers through clear visualizations and hands-on examples. You’ll learn when to use each scheduler, see their behavior patterns, and understand how they can improve your model’s performance. We’ll start with the basics, explore sklearn’s approach versus deep learning requirements, then move to practical implementation using the MNIST dataset.
By the end, you’ll have both the theoretical understanding and practical code to start using learning rate schedulers in your own projects.
Learning Rate Basics
Imagine you’re hiking down a mountain in thick fog, trying to reach the valley. The learning rate is like your step size – take steps too large, and you might overshoot the valley or bounce between mountainsides. Take steps too small, and you’ll move painfully slowly, possibly getting stuck on a ledge before reaching the bottom.
In machine learning, the learning rate controls how much we adjust our model’s weights after each training step. It determines the size of the updates we make when trying to minimize the loss function.
If you’ve worked with sklearn before, you’ve encountered learning rates in algorithms like GradientBoostingClassifier or SGDClassifier. These typically use fixed learning rates throughout training. This approach works reasonably well for simpler models because their optimization surfaces are generally less complex.
However, deep neural networks present more challenging optimization problems with multiple local minima and saddle points, different optimal learning rates at different training stages, and the need for fine-tuning as the model approaches convergence.
Fixed learning rates create several problems:
- Learning rate too high: The model oscillates around the optimal point, unable to settle into the minimum
- Learning rate too low: Training progresses extremely slowly, wasting computational resources and potentially getting trapped in poor local minima
- No adaptation: Cannot adjust to different phases of training
Learning rate schedulers address these issues by dynamically adjusting the learning rate based on training progress or performance metrics.
What Are Learning Rate Schedulers?
Learning rate schedulers are algorithms that automatically adjust your model’s learning rate during training. Instead of using the same learning rate from start to finish, these schedulers change it based on predefined rules or training performance.
The beauty of schedulers lies in their ability to optimize different phases of training. Early in training, when weights are far from optimal, a higher learning rate helps make rapid progress. As the model approaches convergence, a lower learning rate allows for fine-tuning and prevents overshooting the minimum.
This adaptive approach often leads to better final performance, faster convergence, and more stable training compared to fixed learning rates.
Five Essential Learning Rate Schedulers
StepLR – Step Decay
StepLR reduces the learning rate by a fixed factor at regular intervals. In our visualization, it starts at 0.1 and cuts the rate in half every 20 epochs, creating the distinctive step pattern you see.

This scheduler works well when you have knowledge about your training process and can anticipate when the model should focus on fine-tuning. It’s particularly useful for image classification tasks where you might want to reduce the learning rate after the model has learned basic features.
The main advantage is its simplicity and predictability. However, the timing of reductions is fixed regardless of actual training progress, which might not always be optimal.
ExponentialLR – Exponential Decay
ExponentialLR smoothly reduces the learning rate by multiplying it by a decay factor each epoch. Our example uses a 0.95 multiplier, creating the smooth red curve that starts at 0.1 and gradually approaches zero.
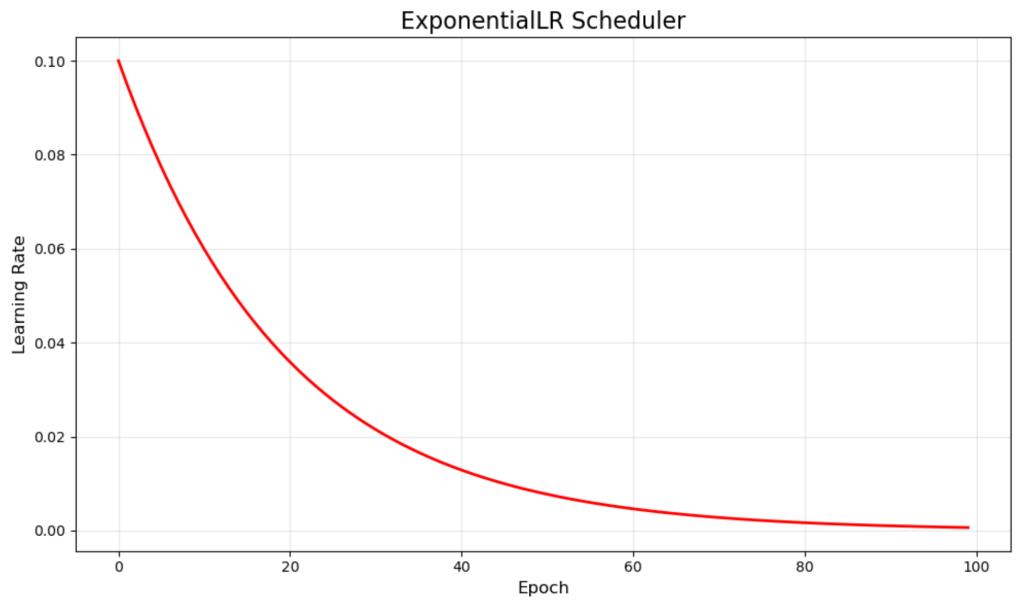
This continuous decay ensures the model consistently makes smaller and smaller updates as training progresses. It’s particularly effective for problems where you want gradual refinement without sharp transitions that might disrupt training momentum.
The smooth nature of exponential decay often leads to stable convergence, but requires careful tuning of the decay rate to avoid reducing the learning rate too quickly or too slowly.
CosineAnnealingLR – Cosine Annealing
CosineAnnealingLR follows a cosine curve, starting high and smoothly decreasing to a minimum value. The green curve shows this elegant mathematical progression, which naturally slows the rate of change as it approaches the minimum.

This scheduler is inspired by simulated annealing and has gained popularity in modern deep learning. The cosine shape provides more training time at higher learning rates early on, then gradually transitions to fine-tuning phases.
Research suggests cosine annealing can help models escape local minima and often achieves better final performance than linear decay schedules, especially in complex optimization landscapes.
ReduceLROnPlateau – Adaptive Plateau Reduction
ReduceLROnPlateau takes a different approach by monitoring validation metrics and reducing the learning rate only when improvement stagnates. The purple visualization shows typical behavior with reductions occurring around epochs 25, 50, and 75.
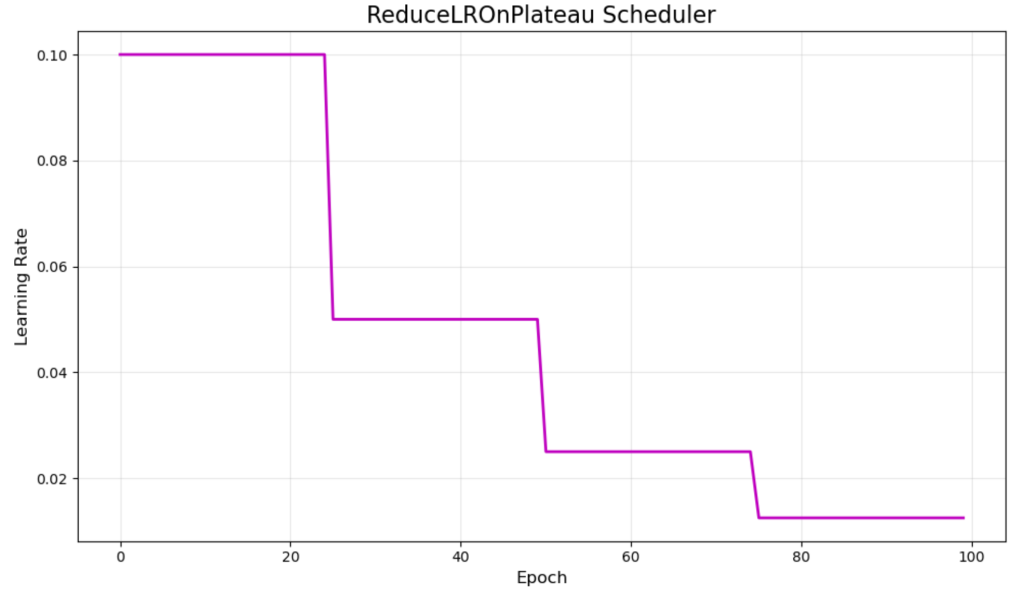
This adaptive scheduler responds to actual training progress rather than following a predetermined schedule. It reduces the learning rate when validation loss stops improving for a specified number of epochs (patience parameter).
The main strength is its responsiveness to training dynamics, making it excellent for cases where you’re unsure about optimal scheduling. However, it requires monitoring validation metrics and may react slowly to needed adjustments.
CyclicalLR – Cyclical Learning Rates
CyclicalLR oscillates between minimum and maximum learning rates in a triangular pattern. Our orange visualization shows these cycles, with the rate climbing from 0.001 to 0.1 and back down over 40-epoch periods.

This approach, pioneered by Leslie Smith, challenges the conventional wisdom of only decreasing learning rates. The theory suggests that periodic increases help the model escape poor local minima and explore the loss surface more effectively.
While cyclical learning rates can achieve impressive results and often train faster than traditional methods, they require careful tuning of the minimum, maximum, and cycle length parameters to work effectively.
Practical Implementation: MNIST Example
Now let’s see how these schedulers perform. We’ll train a simple neural network on the MNIST digit classification dataset to compare how different schedulers affect training performance.
Setup and Data Preparation
We start by importing the necessary libraries and preparing our data. The MNIST dataset contains handwritten digits (0-9) that we’ll classify using a basic two-layer neural network.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# Learning Rate Schedulers – Concise MNIST Demo import numpy as np import matplotlib.pyplot as plt import tensorflow as tf from tensorflow.keras import layers, callbacks from tensorflow.keras.optimizers import Adam import warnings warnings.filterwarnings(‘ignore’) # Data preparation (x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 x_train = x_train.reshape(–1, 784)[:10000] y_train = tf.keras.utils.to_categorical(y_train, 10)[:10000] # Simple model def create_model(): return tf.keras.Sequential([ layers.Dense(128, activation=‘relu’, input_shape=(784,)), layers.Dense(10, activation=‘softmax’) ]) |
Our model is intentionally simple – a single hidden layer with 128 neurons. We use only 10,000 training samples to speed up the experiment while still demonstrating the schedulers’ behaviors.
Scheduler Implementations
Next, we implement each scheduler. Most schedulers can be implemented as simple functions that take the current epoch and learning rate, then return the new learning rate. However, ReduceLROnPlateau works differently since it needs to monitor validation metrics, so we’ll handle it separately in the training section.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# Learning rate schedules (matching visualization parameters) def step_lr(epoch, lr): # StepLR: step_size=20, gamma=0.5 (from visualization) return lr * 0.5 if epoch % 20 == 0 and epoch > 0 else lr def exp_lr(epoch, lr): # ExponentialLR: gamma=0.95 (from visualization) return lr * 0.95 def cosine_lr(epoch, lr): # CosineAnnealingLR: lr_min=0.001, lr_max=0.1, max_epochs=100 (from visualization) lr_min, lr_max = 0.001, 0.1 max_epochs = 100 return lr_min + 0.5 * (lr_max – lr_min) * (1 + np.cos(epoch * np.pi / max_epochs)) def cyclical_lr(epoch, lr): # CyclicalLR: base_lr=0.001, max_lr=0.1, step_size=20 (from visualization) base_lr = 0.001 max_lr = 0.1 step_size = 20 cycle = np.floor(1 + epoch / (2 * step_size)) x = np.abs(epoch / step_size – 2 * cycle + 1) return base_lr + (max_lr – base_lr) * max(0, (1 – x)) |
Notice how each function implements the exact same behavior shown in our earlier visualizations. The parameters are carefully chosen to match those patterns. ReduceLROnPlateau requires special handling since it monitors validation loss during training, which you’ll see in the next section where we set it up as a callback.
Training and Comparison
We then create a training function that can use any of these schedulers and run experiments with each one:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
# Training function def train_scheduler(schedule_name, schedule_fn=None, callback=None): model = create_model() model.compile(optimizer=Adam(0.1), loss=‘categorical_crossentropy’, metrics=[‘accuracy’]) # Start with 0.1 to match visualizations if schedule_fn: callback = callbacks.LearningRateScheduler(schedule_fn) elif callback is None: callback = [] history = model.fit(x_train, y_train, epochs=100, validation_split=0.2, callbacks=[callback] if callback else [], verbose=0) return history # Run experiments results = {} schedulers = { ‘StepLR’: (step_lr, None), ‘ExponentialLR’: (exp_lr, None), ‘CosineAnnealingLR’: (cosine_lr, None), ‘ReduceLROnPlateau’: (None, callbacks.ReduceLROnPlateau(factor=0.5, patience=3)), ‘CyclicalLR’: (cyclical_lr, None) } for name, (schedule, callback) in schedulers.items(): results[name] = train_scheduler(name, schedule, callback) |
Visualizing Training Progress
The training loss curves reveal interesting patterns:
|
# Simple visualization – Training Loss only plt.figure(figsize=(10, 6)) plt.title(‘Training Loss’) for name, history in results.items(): plt.plot(history.history[‘loss’], label=name, linewidth=2) plt.xlabel(‘Epoch’) plt.ylabel(‘Loss’) plt.legend() plt.grid(True, alpha=0.3) plt.tight_layout() plt.show() |

The visualization shows distinct behaviors. StepLR and ReduceLROnPlateau achieve smooth, steady convergence. ExponentialLR maintains consistent progress throughout training. CosineAnnealingLR shows periods of fluctuation followed by improvement. CyclicalLR exhibits the most volatile behavior, with dramatic spikes corresponding to its learning rate increases.
Performance Comparison
The final results reveal which schedulers performed best on this task:
|
# Final results print(“nFinal Results:”) print(“-“ * 50) for name, history in results.items(): val_acc = history.history[‘val_accuracy’][–1] val_loss = history.history[‘val_loss’][–1] print(f“{name:<18} | Val Acc: {val_acc:.3f} | Val Loss: {val_loss:.3f}") |
Results:
|
Final Results: ————————————————————————— StepLR | Val Acc: 0.889 | Val Loss: 235.125 ExponentialLR | Val Acc: 0.883 | Val Loss: 71.269 CosineAnnealingLR | Val Acc: 0.883 | Val Loss: 445.005 ReduceLROnPlateau | Val Acc: 0.890 | Val Loss: 31.791 CyclicalLR | Val Acc: 0.859 | Val Loss: 2304.819 |
ReduceLROnPlateau achieved the best performance with 89.0% validation accuracy and the lowest loss. StepLR came very close with 88.9% accuracy. CyclicalLR struggled in this experiment, likely due to the learning rate range being too aggressive for this simple problem.
These results demonstrate that the choice of scheduler can significantly impact your model’s performance, and different schedulers work better for different problems. The adaptive nature of ReduceLROnPlateau made it particularly effective here, as it could respond to the training dynamics rather than following a predetermined schedule.
Choosing the Right Scheduler
Selecting the appropriate scheduler depends on your problem characteristics and training requirements. Here’s a practical decision framework:
When you know your training phases → StepLR
If you understand when your model should transition from exploration to fine-tuning, StepLR gives you explicit control over these phases.
When you want smooth, predictable decay → ExponentialLR
For stable, continuous reduction without sudden changes that might disrupt training momentum.
When you want to escape local minima → CosineAnnealingLR
The cosine pattern provides natural exploration phases that can help the model find better solutions.
When you’re uncertain about scheduling → ReduceLROnPlateau
This adaptive approach responds to actual training progress, making it excellent when you’re unsure about optimal timing.
For advanced optimization techniques → CyclicalLR
When you want to experiment with more sophisticated approaches that challenge traditional learning rate assumptions.
Start with ReduceLROnPlateau for most problems, then experiment with others based on your specific needs.
Beyond the Basics
The learning rate scheduling landscape extends far beyond these five schedulers. Modern variants include MultiStepLR for multiple reduction points, OneCycleLR for super-convergence, PolynomialLR for custom decay curves, LambdaLR for arbitrary functions, and LinearLR for simple linear changes.
Current research explores warm-up schedules, learning rate range tests, and specialized schedulers for different architectures. For deeper exploration, consult the TensorFlow and PyTorch documentation, recent papers on optimization methods, and practical guides from practitioners.
Conclusion & Next Steps
Learning rate schedulers can significantly improve your model’s training efficiency and final performance. The choice of scheduler often matters as much as the model architecture itself.
Start experimenting with these schedulers in your own projects. Begin with ReduceLROnPlateau for its adaptiveness, then explore others based on your specific needs. The key is to monitor training closely and adjust based on what you observe.
Your models will thank you for the attention to this often-overlooked but vital aspect of training.