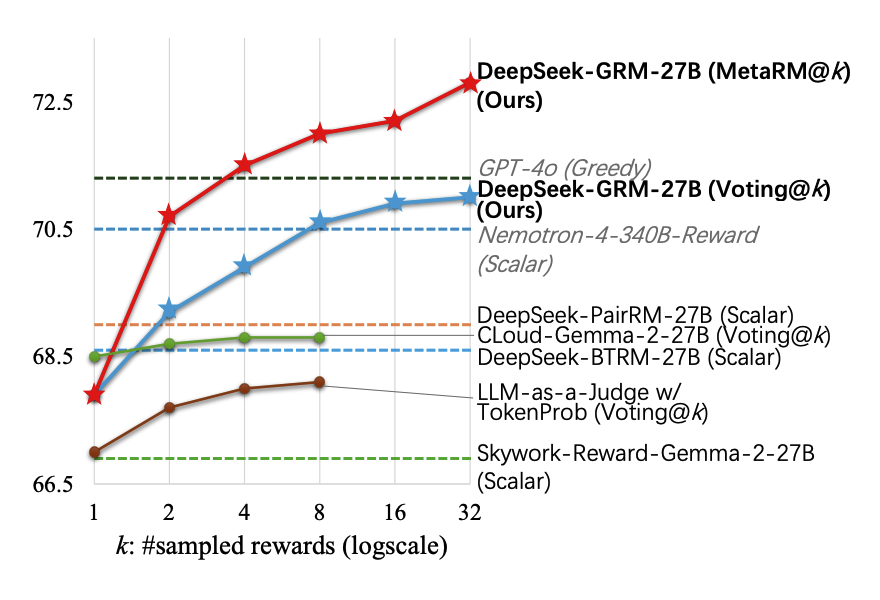
Scalable and Principled Reward Modeling for LLMs: Enhancing Generalist Reward Models RMs with SPCT and Inference-Time Optimization
Source: MarkTechPost Reinforcement Learning RL has become a widely used post-training method for LLMs, enhancing capabilities like human...