
AMD Releases Instella-MoE-16B-A3B: A Fully Open Mixture-of-Experts LLM With 2.8B Active Parameters Trained On Instinct GPUs
Source: MarkTechPost AMD released Instella-MoE-16B-A3B, a fully open Mixture-of-Experts language model trained from scratch on Instinct MI300X and...

Accelerating Transformer Training with NVIDIA Transformer Engine, Fused Kernels, BF16, FP8, and GPU Benchmarking
Source: MarkTechPost In this tutorial, we explore how NVIDIA Transformer Engine accelerates transformer workloads by combining fused GPU...

Supabase Releases Evals: an Open Source Benchmark That Scores Claude Code, Codex and OpenCode on Real Supabase Tasks
Source: MarkTechPost Supabase has open sourced Supabase Evals, its benchmark and framework for testing how well AI agents...

MiniMax Releases MiniMax H3: An Omni-Modal Video Model That Generates 15-Second 2K Clips With Native Stereo Audio
Source: MarkTechPost MiniMax releases MiniMax H3, a general-purpose multimodal generation model. MiniMax H3 is not a text-to-video model...

DeepSeek Upgrades DeepSeek-V4-Flash-0731 with Major Agentic and Coding Gains
Source: MarkTechPost DeepSeek published DeepSeek-V4-Flash-0731 on Hugging Face and moved the official V4-Flash API into public beta on...
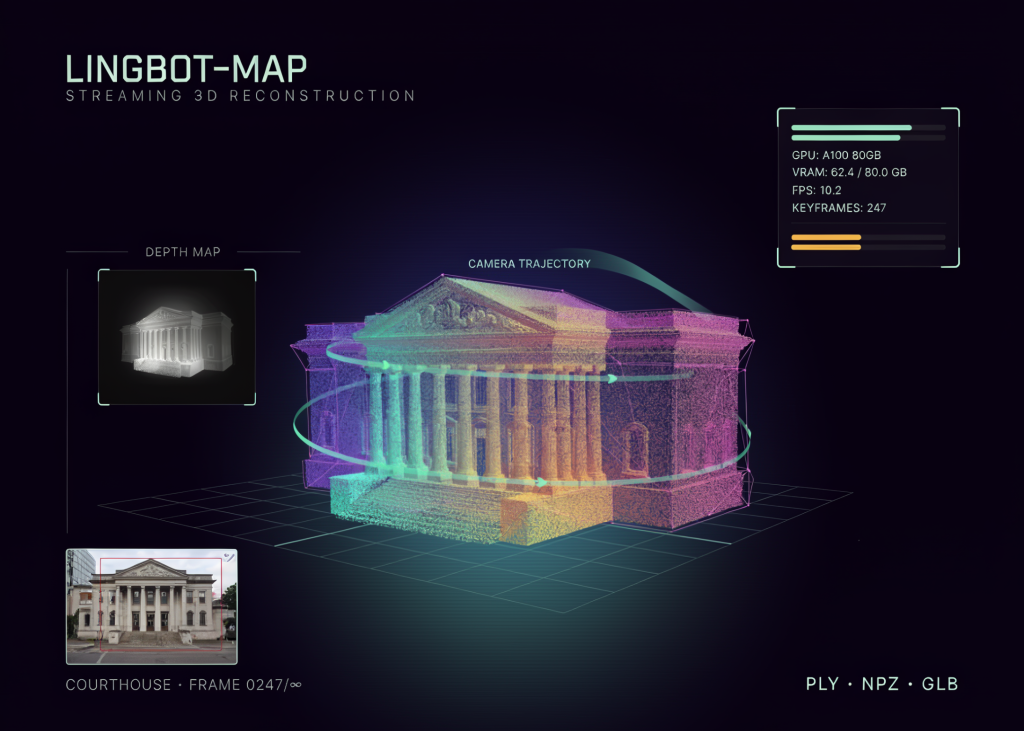
LingBot-Map Tutorial: GPU-Aware Inference and Point Cloud Export
Source: MarkTechPost In this tutorial, we implement an end-to-end streaming 3D reconstruction pipeline with LingBot-Map. We begin by...
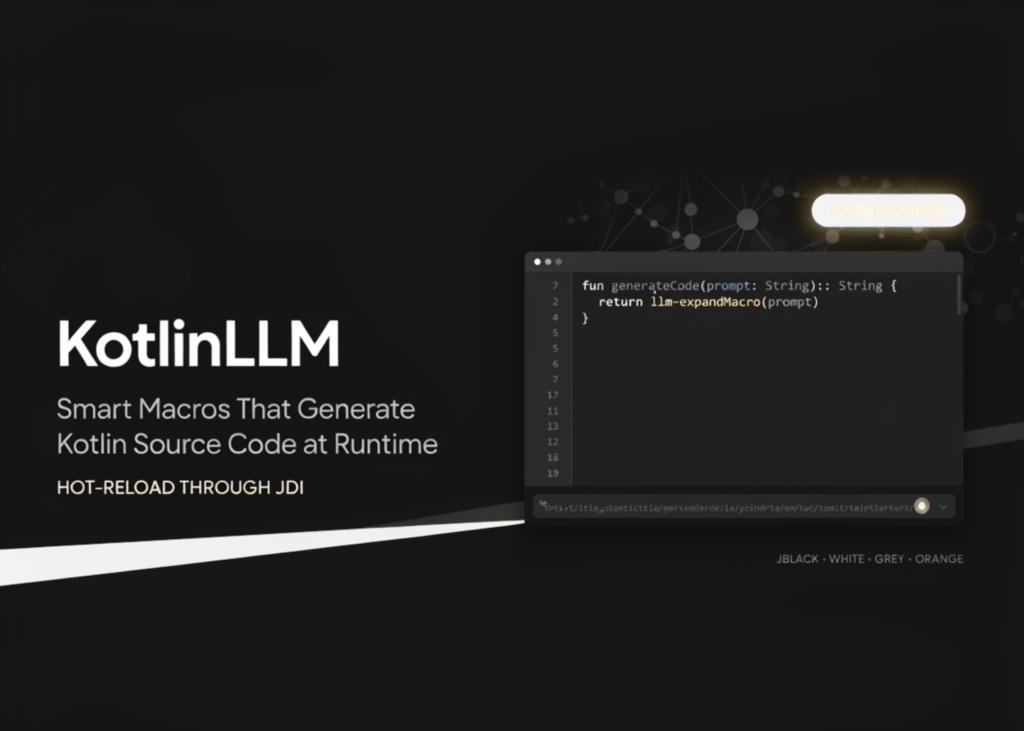
JetBrains Open-Sources KotlinLLM: Smart Macros That Generate Kotlin Source Code at Runtime and Hot-Reload It Through JDI
Source: MarkTechPost JetBrains Research Open-Sources KotlinLLM. KotlinLLM is an IntelliJ IDEA plugin for Kotlin/JVM projects that adds a...

PolyAI Releases Dialog-RSN-1: An Audio-Native Dialog Model That Fuses Turn-Taking, Speech Recognition, Function Calling, And Response
Source: MarkTechPost PolyAI has introduced Dialog-RSN-1, a dialog model that perceives the caller’s audio directly instead of reading...

Building a Policy-Governed Multi-Agent Financial Research Workflow with Omnigent
Source: MarkTechPost In this tutorial, we build and execute a multi-agent workflow with Omnigent using a reliable, isolated...

Daniela Rus receives Bavarian Minister-President’s High-Tech Prize
Source: MIT News – Artificial intelligence Daniela Rus, director of MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL)...