
Bito Raises $5.7M to Supercharge Agentic AI Code Reviews and Accelerate Enterprise Dev Velocity
Source: Unite.AI In a funding round that signals a significant leap forward for AI-assisted software development, Bito has...

Hollywood Looks Over Its Shoulder as Veo 3 Enters the Picture
Source: Unite.AI Google’s newly unveiled Veo 3 model is seriously redefining what AI-generated video can do. Announced at...

MIT announces the Initiative for New Manufacturing
Source: MIT News – Artificial intelligence MIT today launched its Initiative for New Manufacturing (INM), an Institute-wide effort...

How Phi-4-Reasoning Redefines AI Reasoning by Challenging “Bigger is Better” Myth
Source: Unite.AI Microsoft’s recent release of Phi-4-reasoning challenges a key assumption in building artificial intelligence systems capable of...
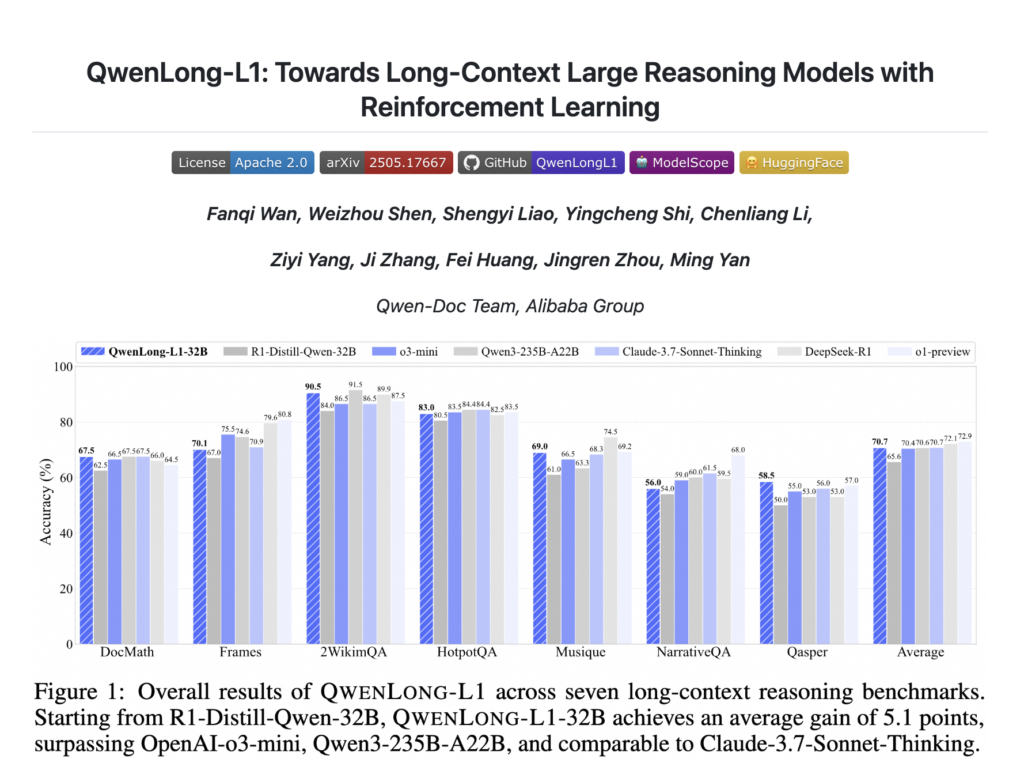
Qwen Researchers Proposes QwenLong-L1: A Reinforcement Learning Framework for Long-Context Reasoning in Large Language Models
Source: MarkTechPost While large reasoning models (LRMs) have shown impressive capabilities in short-context reasoning through reinforcement learning (RL),...

Researchers at UT Austin Introduce Panda: A Foundation Model for Nonlinear Dynamics Pretrained on 20,000 Chaotic ODE Discovered via Evolutionary Search
Source: MarkTechPost Chaotic systems, such as fluid dynamics or brain activity, are highly sensitive to initial conditions, making...

This AI Paper Introduces Differentiable MCMC Layers: A New AI Framework for Learning with Inexact Combinatorial Solvers in Neural Networks
Source: MarkTechPost Neural networks have long been powerful tools for handling complex data-driven tasks. Still, they often struggle...

Simon Poghosyan, Founder and CEO of GSpeech – Interview Series
Source: Unite.AI Simon Poghosyan is the founder and CEO of GSpeech, a web-based AI platform that helps make...

The AI Arms Race and Its Potential Impact on Businesses
Source: Unite.AI The AI arms race is no longer a distant theoretical concern; it’s a present-day sprint between...

Can LLMs Really Judge with Reasoning? Microsoft and Tsinghua Researchers Introduce Reward Reasoning Models to Dynamically Scale Test-Time Compute for Better Alignment
Source: MarkTechPost Reinforcement learning (RL) has emerged as a fundamental approach in LLM post-training, utilizing supervision signals from...