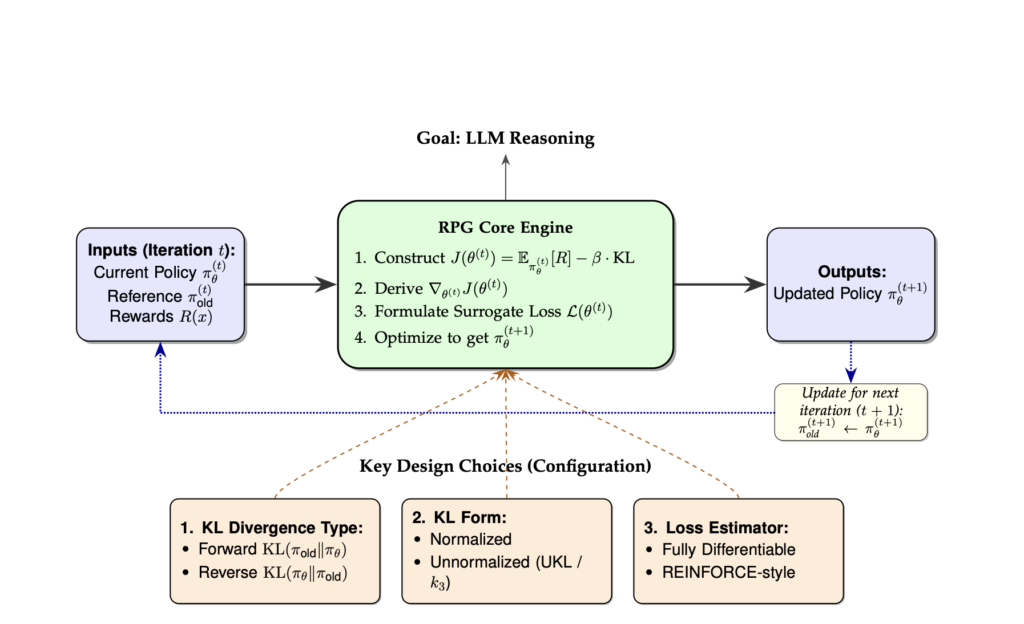
Off-Policy Reinforcement Learning RL with KL Divergence Yields Superior Reasoning in Large Language Models
Source: MarkTechPost Policy gradient methods have significantly advanced the reasoning capabilities of LLMs, particularly through RL. A key...