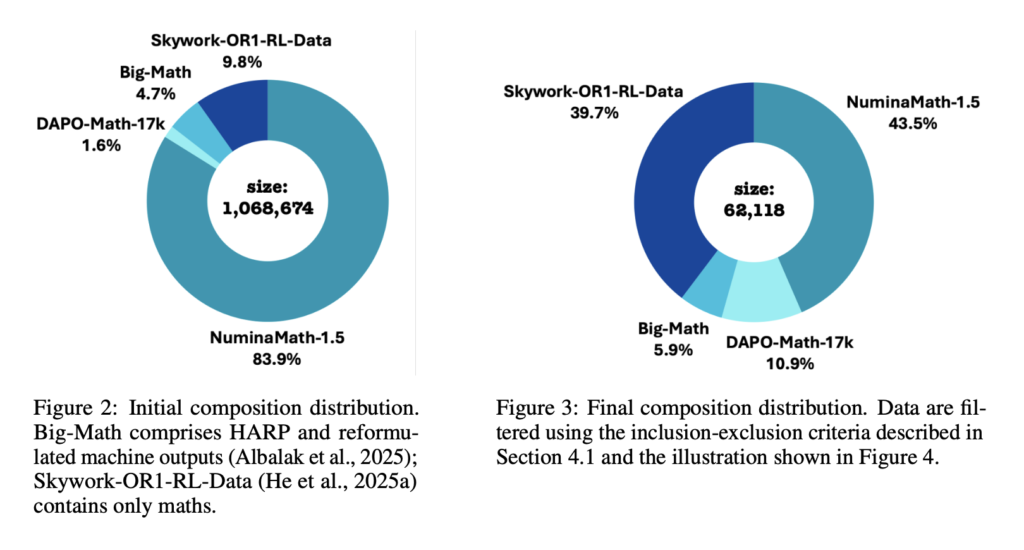
MiroMind-M1: Advancing Open-Source Mathematical Reasoning via Context-Aware Multi-Stage Reinforcement Learning
Source: MarkTechPost Large language models (LLMs) have recently demonstrated remarkable progress in multi-step reasoning, establishing mathematical problem-solving as...
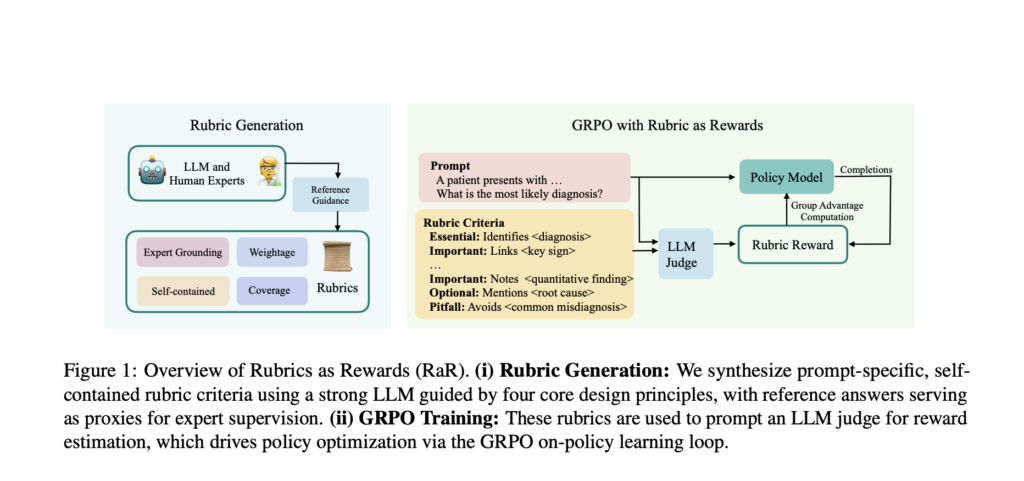
Rubrics as Rewards (RaR): A Reinforcement Learning Framework for Training Language Models with Structured, Multi-Criteria Evaluation Signals
Source: MarkTechPost Reinforcement Learning with Verifiable Rewards (RLVR) allows LLMs to perform complex reasoning on tasks with clear,...
New algorithms enable efficient machine learning with symmetric data
Source: MIT News – Artificial intelligence If you rotate an image of a molecular structure, a human can...