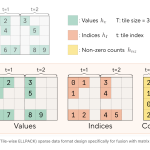
Sakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMs
Source: MarkTechPost Scaling large language models (LLMs) is expensive. Every token processed during inference and every gradient computed...

A Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM Applications
Source: MarkTechPost In this tutorial, we implement how Memori serves as an agent-native memory infrastructure layer for building...