Source: MarkTechPost
Understanding the Importance of Benchmarking in Tabular ML
Machine learning on tabular data focuses on building models that learn patterns from structured datasets, typically composed of rows and columns similar to those found in spreadsheets. These datasets are used in industries ranging from healthcare to finance, where accuracy and interpretability are essential. Techniques such as gradient-boosted trees and neural networks are commonly used, and recent advances have introduced foundation models designed to handle tabular data structures. Ensuring fair and effective comparisons between these methods has become increasingly important as new models continue to emerge.
Challenges with Existing Benchmarks
One challenge in this domain is that benchmarks for evaluating models on tabular data are often outdated or flawed. Many benchmarks continue to utilize obsolete datasets with licensing issues or those that do not accurately reflect real-world tabular use cases. Furthermore, some benchmarks include data leaks or synthetic tasks, which distort model evaluation. Without active maintenance or updates, these benchmarks fail to keep pace with advances in modeling, leaving researchers and practitioners with tools that cannot reliably measure current model performance.
Limitations of Current Benchmarking Tools
Several tools have attempted to benchmark models, but they typically rely on automatic dataset selection and minimal human oversight. This introduces inconsistencies in performance evaluation due to unverified data quality, duplication, or preprocessing errors. Furthermore, many of these benchmarks utilize only default model settings and avoid extensive hyperparameter tuning or ensemble techniques. The result is a lack of reproducibility and a limited understanding of how models perform under real-world conditions. Even widely cited benchmarks often fail to specify essential implementation details or restrict their evaluations to narrow validation protocols.
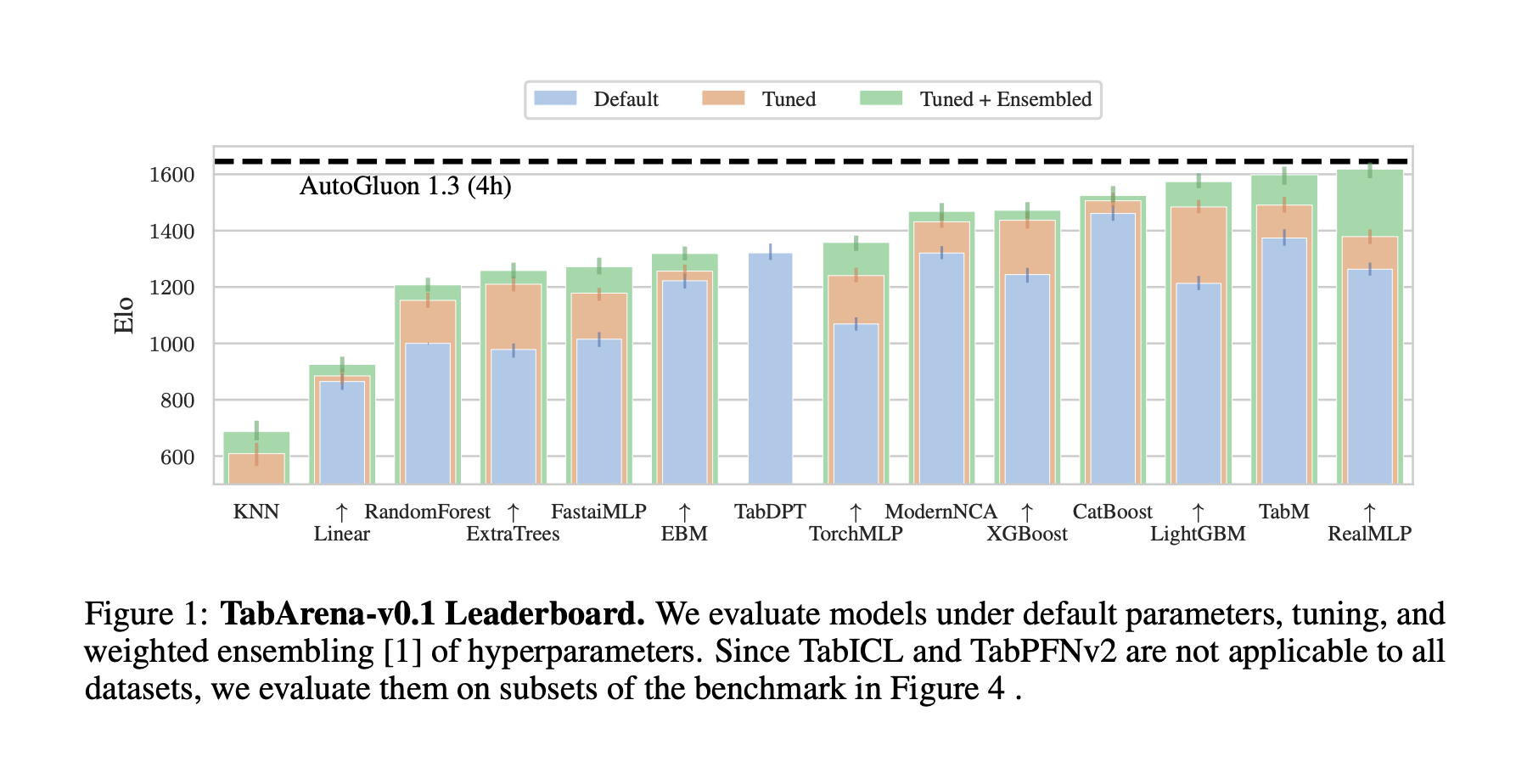
Introducing TabArena: A Living Benchmarking Platform
Researchers from Amazon Web Services, University of Freiburg, INRIA Paris, Ecole Normale Supérieure, PSL Research University, PriorLabs, and the ELLIS Institute Tübingen have introduced TabArena—a continuously maintained benchmark system designed for tabular machine learning. The research introduced TabArena to function as a dynamic and evolving platform. Unlike previous benchmarks that are static and outdated soon after release, TabArena is maintained like software: versioned, community-driven, and updated based on new findings and user contributions. The system was launched with 51 carefully curated datasets and 16 well-implemented machine-learning models.
Three Pillars of TabArena’s Design
The research team constructed TabArena on three main pillars: robust model implementation, detailed hyperparameter optimization, and rigorous evaluation. All models are built using AutoGluon and adhere to a unified framework that supports preprocessing, cross-validation, metric tracking, and ensembling. Hyperparameter tuning involves evaluating up to 200 different configurations for most models, except TabICL and TabDPT, which were tested for in-context learning only. For validation, the team uses 8-fold cross-validation and applies ensembling across different runs of the same model. Foundation models, due to their complexity, are trained on merged training-validation splits as recommended by their original developers. Each benchmarking configuration is evaluated with a one-hour time limit on standard computing resources.
Performance Insights from 25 Million Model Evaluations
Performance results from TabArena are based on an extensive evaluation involving approximately 25 million model instances. The analysis showed that ensemble strategies significantly improve performance across all model types. Gradient-boosted decision trees still perform strongly, but deep-learning models with tuning and ensembling are on par with, or even better than, them. For instance, AutoGluon 1.3 achieved marked results under a 4-hour training budget. Foundation models, particularly TabPFNv2 and TabICL, demonstrated strong performance on smaller datasets thanks to their effective in-context learning capabilities, even without tuning. Ensembles combining different types of models achieved state-of-the-art performance, although not all individual models contributed equally to the final results. These findings highlight the importance of both model diversity and the effectiveness of ensemble methods.
The article identifies a clear gap in reliable, current benchmarking for tabular machine learning and offers a well-structured solution. By creating TabArena, the researchers have introduced a platform that addresses critical issues of reproducibility, data curation, and performance evaluation. The method relies on detailed curation and practical validation strategies, making it a significant contribution for anyone developing or evaluating models on tabular data.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Nikhil
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
