Source: MarkTechPost
Understanding the Role of Chain-of-Thought in LLMs
Large language models are increasingly being used to solve complex tasks such as mathematics and scientific reasoning through structured chain-of-thought approaches. These models do not just jump to answers—they reason through intermediate steps that simulate logical thought processes. This technique allows for improved reasoning accuracy and clearer error tracing. As models become more sophisticated, it has become essential to evaluate not just final responses but also the reasoning steps that lead to them.
Limitations of Traditional PRMs in Reasoning Evaluation
One pressing issue is that most current reward models only assess final answers, ignoring how those conclusions were reached. However, frontier models like Deepseek-R1 now output extensive reasoning paths before delivering final responses. These trajectory-response pairs are being reused to train smaller models. The problem is that current Process Reward Models (PRMs) are not built to evaluate these full trajectories. This mismatch leads to unreliable supervision, which can degrade the performance of smaller models trained on trajectory-response data.
Challenges in Handling Disorganized Reasoning Chains
Traditional PRMs are primarily calibrated for structured, clean outputs rather than the lengthy and sometimes disorganized reasoning chains generated by advanced LLMs. Even advanced PRMs, such as Qwen2.5-Math-PRM-72B, show a limited ability to distinguish between high- and low-quality intermediate reasoning. When applied to trajectory-response outputs from Gemini or Deepseek-R1, these models often produce overlapping reward scores, indicating weak discrimination. Their limited sensitivity leads to poor data selection for downstream fine-tuning, and experiments confirm that models trained on PRM-selected data perform worse than those trained on human-curated datasets.
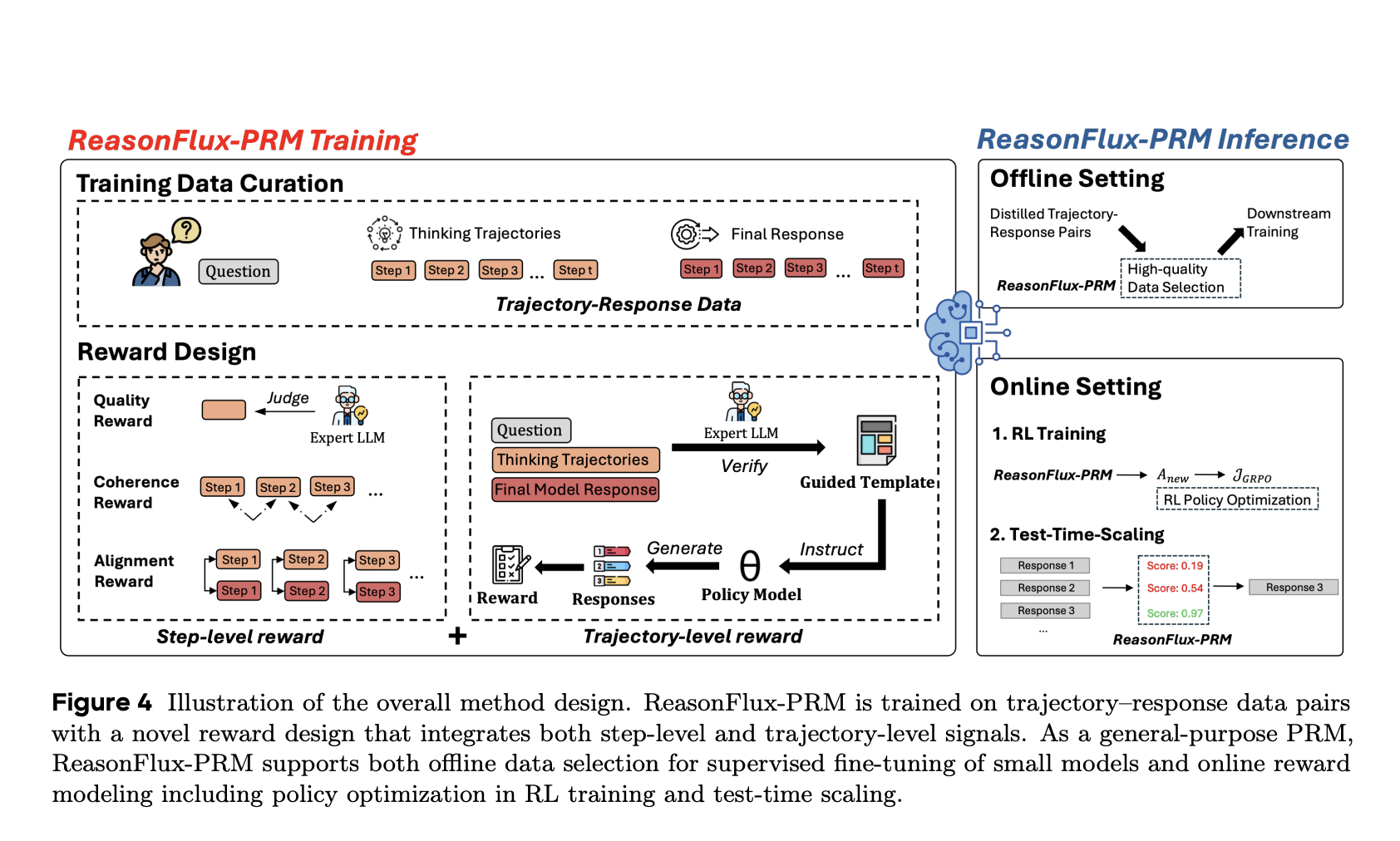
Introducing ReasonFlux-PRM for Trajectory-Level Supervision
Researchers from the University of Illinois Urbana-Champaign (UIUC), Princeton University, Cornell University, and ByteDance Seed introduced ReasonFlux-PRM. The research introduced ReasonFlux-PRM as a trajectory-aware model that evaluates both intermediate reasoning steps and final answers. It integrates step-level and trajectory-level scoring, enabling a more nuanced understanding of reasoning quality. ReasonFlux-PRM is trained on a 10,000-sample dataset of carefully curated math and science problems explicitly designed to mirror real-world trajectory-response formats.
Technical Framework of ReasonFlux-PRM
Technically, ReasonFlux-PRM operates by scoring each intermediate step in a trajectory concerning its contribution to the final answer. It uses a reference reward function that considers the prompt, prior reasoning steps, and final output to assign step-level scores. These are then aggregated to produce a total trajectory reward. The model supports multiple applications, including offline filtering of high-quality training data, dense reward provision during reinforcement learning using GRPO-based policy optimization, and Best-of-N test-time response selection to enhance inference quality. These capabilities make ReasonFlux-PRM more flexible and comprehensive than prior PRMs.
Empirical Results on Reasoning Benchmarks
In performance evaluations across tasks like AIME, MATH500, and GPQA-Diamond, ReasonFlux-PRM-7B outperformed Qwen2.5-Math-PRM-72B and human-curated data in several key metrics. Specifically, it achieved a 12.1% accuracy gain in supervised fine-tuning, a 4.5% improvement during reinforcement learning, and a 6.3% increase during test-time scaling. These gains are particularly considerable given that ReasonFlux-PRM is smaller in model size. Table 1 shows that the Qwen2.5-14B-Instruct model, when trained on data selected by ReasonFlux-PRM, achieved performance levels close to or exceeding human-curated baselines. In contrast, other PRMs resulted in significant drops of up to 26.6% in certain benchmarks.
Impact and Future Direction of ReasonFlux-PRM
This research addresses a crucial limitation in the training and evaluation of modern reasoning models. By enabling supervision over both thinking trajectories and final answers, ReasonFlux-PRM enhances the quality of training data and the reliability of model responses. It sets a new direction for systematically evaluating and improving reasoning processes in large models.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Nikhil
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
