
Source: MarkTechPost
Large language model agents are starting to store everything they see, but can they actually improve their policies at test time from those experiences rather than just replaying context windows?
Researchers from University of Illinois Urbana Champaign and Google DeepMind propose Evo-Memory, a streaming benchmark and agent framework that targets this exact gap. Evo-Memory evaluates test-time learning with self-evolving memory, asking whether agents can accumulate and reuse strategies from continuous task streams instead of relying only on static conversational logs.
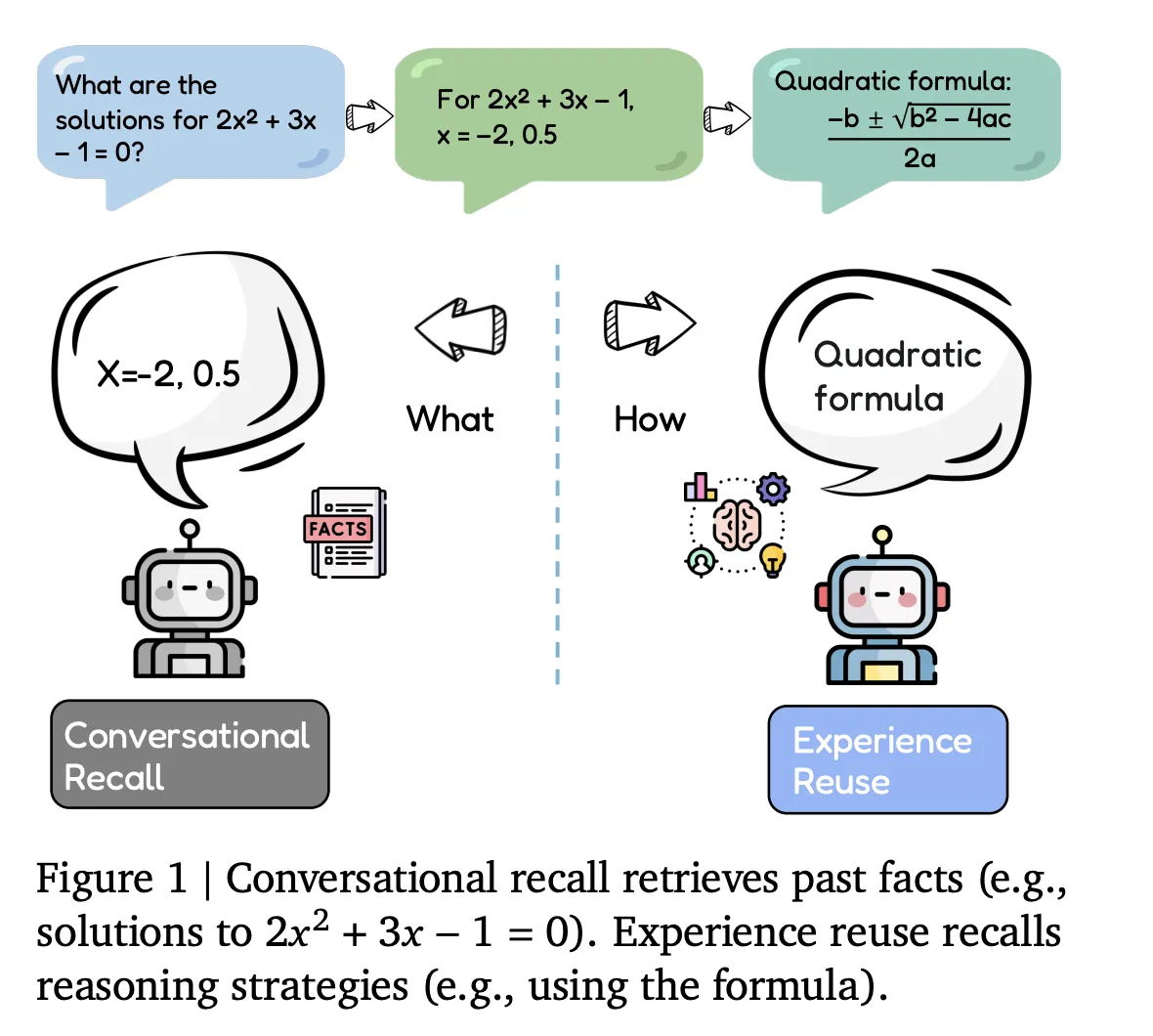
Conversational Recall vs Experience Reuse
Most current agents implement conversational recall. They store dialogue history, tool traces, and retrieved documents, which are then reintegrated into the context window for future queries. This type of memory serves as a passive buffer, capable of recovering facts or recalling previous steps, but it does not actively modify the agent’s approach for related tasks.
Evo-Memory instead focuses on experience reuse. Here each interaction is treated as an experience that encodes not only inputs and outputs, but also whether a task succeeded and which strategies were effective. The benchmark checks if agents can retrieve those experiences in later tasks, apply them as reusable procedures, and refine the memory over time.
Benchmark Design and Task Streams
The research team formalizes a memory augmented agent as a tuple ((F, U, R, C)). The base model (F) generates outputs. The retrieval module (R) searches a memory store. The context constructor (C) synthesizes a working prompt from the current input and retrieved items. The update function (U) writes new experience entries and evolves the memory after every step.
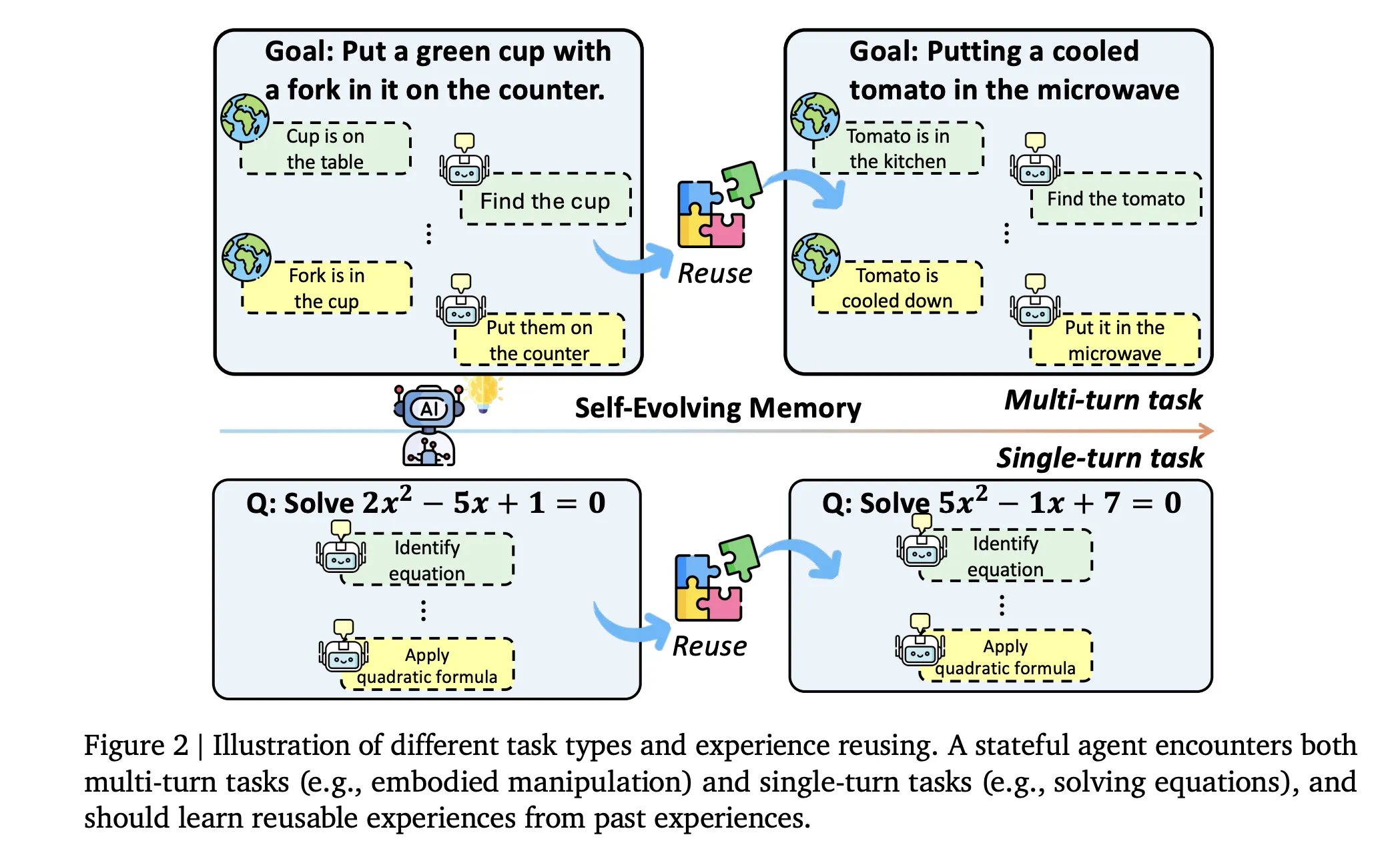
Evo-Memory restructures conventional benchmarks into sequential task streams. Each dataset becomes an ordered sequence of tasks where early items carry strategies that are useful for later ones. The suite covers AIME 24, AIME 25, GPQA Diamond, MMLU-Pro economics, engineering, philosophy, and ToolBench for tool use, along with multi turn environments from AgentBoard including AlfWorld, BabyAI, ScienceWorld, Jericho, and PDDL planning.
Evaluation is done along four axes. Single turn tasks use exact match or answer accuracy. Embodied environments report success rate and progress rate. Step efficiency measures average steps per successful task. Sequence robustness tests whether performance is stable when task order changes.
ExpRAG, a Minimal Experience Reuse Baseline
To set a lower bound, the research team define ExpRAG. Each interaction becomes a structured experience text with template ⟨xi,yi^,fi⟩where xi is input, yi^ is model output and fi is feedback, for example a correctness signal. At a new step (t), the agent retrieves similar experiences from memory using a similarity score and concatenates them with the current input as in-context examples. Then it appends the new experience into memory.
ExpRAG does not change the agent control loop. It is still a single shot call to the backbone, but now augmented with explicitly stored prior tasks. The design is intentionally simple so that any gains on Evo-Memory can be attributed to task level experience retrieval, not to new planning or tool abstractions.
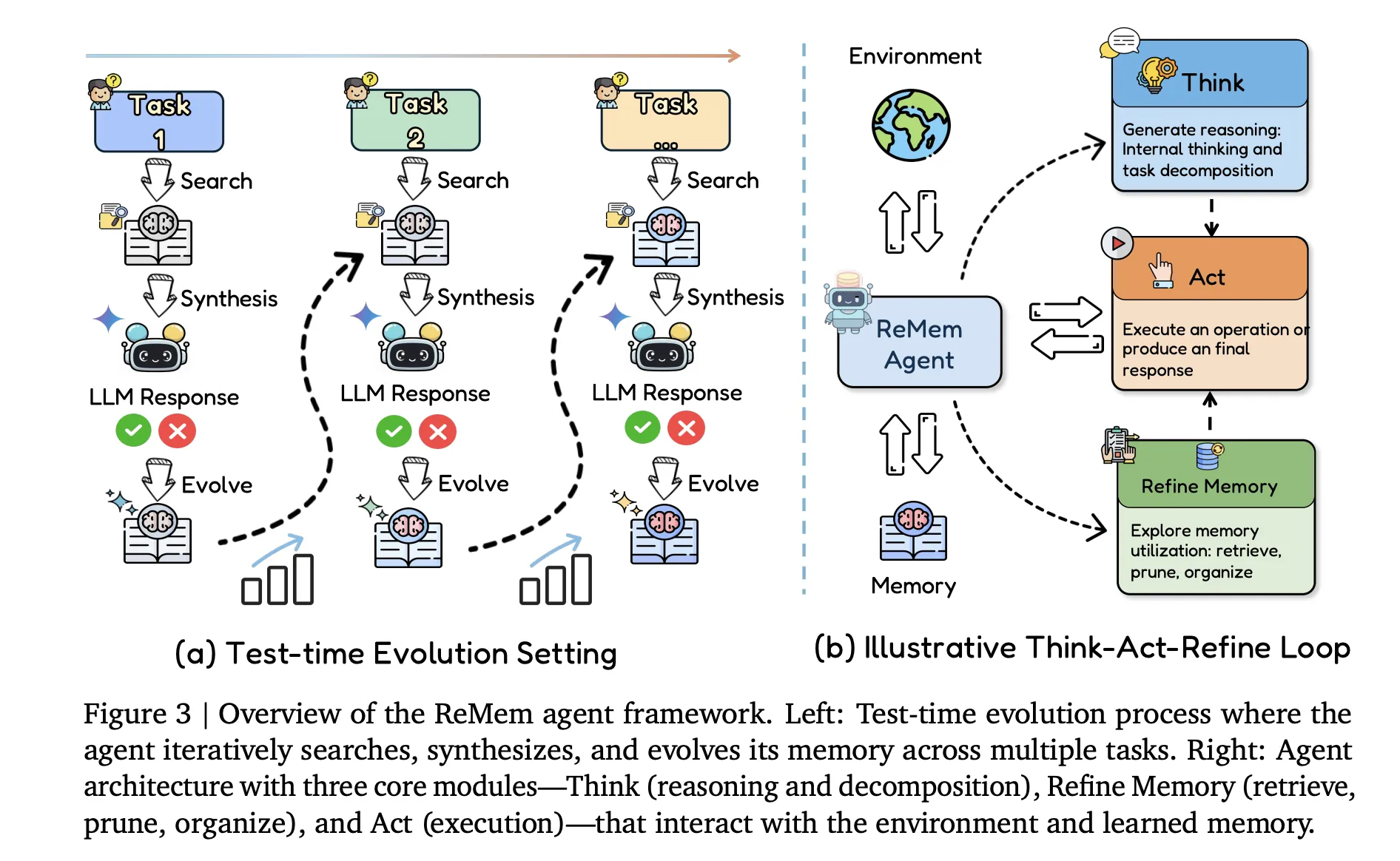
ReMem, Action Think Memory Refine
The main contribution on the agent side is ReMem, an action–think–memory refine pipeline built on top of the same backbone models. At each internal step, given the current input, memory state and past reasoning traces, the agent chooses one of three operations:
- Think generates intermediate reasoning traces that decompose the task.
- Act emits an environment action or final answer visible to the user.
- Refine performs meta reasoning on memory by retrieving, pruning and reorganizing experience entries.
This loop induces a Markov decision process where the state includes the query, current memory and ongoing thoughts. Within a step the agent can interleave several Think and Refine operations, and the step terminates when an Act operation is issued. In contrast to standard ReAct style agents, memory is no longer a fixed buffer. It becomes an explicit object that the agent reasons about and edits during inference.
Results on Reasoning, Tools and Embodied Environments
The research team instantiate all methods on Gemini 2.5 Flash and Claude 3.7 Sonnet under a unified search–predict–evolve protocol. This isolates the effect of memory architecture, since prompting, search and feedback are held constant across baselines.
On single turn benchmarks, evolving memory methods produce consistent but moderate gains. For Gemini 2.5 Flash, ReMem reaches average exact match 0.65 across AIME 24, AIME 25, GPQA Diamond and MMLU Pro subsets, and 0.85 and 0.71 API and accuracy on ToolBench. ExpRAG also performs strongly, with average 0.60, and outperforms several more complex designs such as Agent Workflow Memory and Dynamic Cheatsheet variants.
The impact is larger in multi turn environments. On Claude 3.7 Sonnet, ReMem reaches success and progress 0.92 and 0.96 on AlfWorld, 0.73 and 0.83 on BabyAI, 0.83 and 0.95 on PDDL and 0.62 and 0.89 on ScienceWorld, giving average 0.78 success and 0.91 progress across datasets. On Gemini 2.5 Flash, ReMem achieves average 0.50 success and 0.64 progress, improving over history and ReAct style baselines in all four environments.
Step efficiency is also improved. In AlfWorld, average steps to complete a task drop from 22.6 for a history baseline to 11.5 for ReMem. Lightweight designs such as ExpRecent and ExpRAG reduce steps as well, which indicates that even simple task level experience reuse can make behaviour more efficient without architectural changes to the backbone.
A further analysis links gains to task similarity inside each dataset. Using embeddings from the retriever encoder, the research team compute average distance from tasks to their cluster center. ReMem’s margin over a history baseline correlates strongly with this similarity measure, with reported Pearson correlation about 0.72 on Gemini 2.5 Flash and 0.56 on Claude 3.7 Sonnet. Structured domains such as PDDL and AlfWorld show larger improvements than diverse sets like AIME 25 or GPQA Diamond.
Key Takeaways
- Evo-Memory is a comprehensive streaming benchmark that converts standard datasets into ordered task, so agents can retrieve, integrate and update memory over time rather than rely on static conversational recall.
- The framework formalizes memory augmented agents as a tuple ((F, U, R, C)) and implements more than 10 representative memory modules, including retrieval based, workflow and hierarchical memories, evaluated on 10 single turn and multi turn datasets across reasoning, question answering, tool use and embodied environments.
- ExpRAG provides a minimal experience reuse baseline that stores each task interaction as a structured text record with input, model output and feedback, then retrieves similar experiences as in context exemplars for new tasks, already giving consistent improvements over pure history based baselines.
- ReMem extends the standard ReAct style loop with an explicit Think, Act, Refine Memory control cycle, which lets the agent actively retrieve, prune and reorganize its memory during inference, leading to higher accuracy, higher success rate and fewer steps on both single turn reasoning and long horizon interactive environments.
- Across Gemini 2.5 Flash and Claude 3.7 Sonnet backbones, self evolving memories such as ExpRAG and especially ReMem make smaller models behave like stronger agents at test time, improving exact match, success and progress metrics without any retraining of base model weights.

Editorial Notes
Evo Memory is a useful step for evaluating self evolving memory in LLM agents. It forces models to operate on sequential task streams instead of isolated prompts. It compares more than 10 memory architectures under a single framework. Simple methods like ExpRAG already show clear gains. ReMem’s action, think, refine memory loop improves exact match, success and progress without retraining base weights. Overall, this research work makes test time evolution a concrete design target for LLM agent systems
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter
Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.