
Microsoft Releases Agent Lightning: A New AI Framework that Enables Reinforcement Learning (RL)-based Training of LLMs for Any AI Agent
Source: MarkTechPost How do you convert real agent traces into reinforcement learning RL transitions to improve policy LLMs...

Liquid AI Releases LFM2-ColBERT-350M: A New Small Model that brings Late Interaction Retrieval to Multilingual and Cross-Lingual RAG
Source: MarkTechPost Can a compact late interaction retriever index once and deliver accurate cross lingual search with fast...
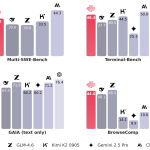
MiniMax Releases MiniMax M2: A Mini Open Model Built for Max Coding and Agentic Workflows at 8% Claude Sonnet Price and ~2x Faster
Source: MarkTechPost Can an open source MoE truly power agentic coding workflows at a fraction of flagship model...

Zhipu AI Releases ‘Glyph’: An AI Framework for Scaling the Context Length through Visual-Text Compression
Source: MarkTechPost Can we render long texts as images and use a VLM to achieve 3–4× token compression,...

Meet ‘kvcached’: A Machine Learning Library to Enable Virtualized, Elastic KV Cache for LLM Serving on Shared GPUs
Source: MarkTechPost Large language model serving often wastes GPU memory because engines pre-reserve large static KV cache regions...
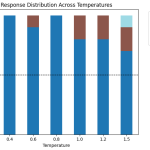
5 Common LLM Parameters Explained with Examples
Source: MarkTechPost Large language models (LLMs) offer several parameters that let you fine-tune their behavior and control how...

Liquid AI’s LFM2-VL-3B Brings a 3B Parameter Vision Language Model (VLM) to Edge-Class Devices
Source: MarkTechPost Liquid AI released LFM2-VL-3B, a 3B parameter vision language model for image text to text tasks....

An Implementation on Building Advanced Multi-Endpoint Machine Learning APIs with LitServe: Batching, Streaming, Caching, and Local Inference
Source: MarkTechPost In this tutorial, we explore LitServe, a lightweight and powerful serving framework that allows us to...

Google AI Introduces FLAME Approach: A One-Step Active Learning that Selects the Most Informative Samples for Training and Makes a Model Specialization Super Fast
Source: MarkTechPost Open vocabulary object detectors answer text queries with boxes. In remote sensing, zero shot performance drops...

PokeeResearch-7B: An Open 7B Deep-Research Agent Trained with Reinforcement Learning from AI Feedback (RLAIF) and a Robust Reasoning Scaffold
Source: MarkTechPost Pokee AI has open sourced PokeeResearch-7B, a 7B parameter deep research agent that executes full research...