
Google AI Introduces DS STAR: A Multi Agent Data Science System That Plans, Codes And Verifies End To End Analytics
Source: MarkTechPost How do you turn a vague business style question over messy folders of CSV, JSON and...
OpenAI Introduces IndQA: A Culture Aware Benchmark For Indian Languages
Source: MarkTechPost How can we reliably test whether large language models actually understand Indian languages and culture in...
Google AI Introduces Consistency Training for Safer Language Models Under Sycophantic and Jailbreak Style Prompts
Source: MarkTechPost How can consistency training help language models resist sycophantic prompts and jailbreak style attacks while keeping...

Comparing the Top 7 Large Language Models LLMs/Systems for Coding in 2025
Source: MarkTechPost Code-oriented large language models moved from autocomplete to software engineering systems. In 2025, leading models must...

Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache Fusion
Source: MarkTechPost Can large language models collaborate without sending a single token of text? a team of researchers...

How to Create AI-ready APIs?
Source: MarkTechPost Postman recently released a comprehensive checklist and developer guide for building AI-ready APIs, highlighting a simple...

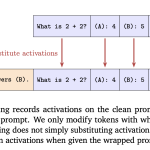
Anthropic’s New Research Shows Claude can Detect Injected Concepts, but only in Controlled Layers
Source: MarkTechPost How do you tell whether a model is actually noticing its own internal state instead of...

OpenAI Releases Research Preview of ‘gpt-oss-safeguard’: Two Open-Weight Reasoning Models for Safety Classification Tasks
Source: MarkTechPost OpenAI has released a research preview of gpt-oss-safeguard, two open weight safety reasoning models that let...
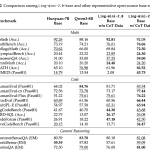
Ant Group Releases Ling 2.0: A Reasoning-First MoE Language Model Series Built on the Principle that Each Activation Enhances Reasoning Capability
Source: MarkTechPost How do you build a language model that grows in capacity but keeps the computation for...

Microsoft Releases Agent Lightning: A New AI Framework that Enables Reinforcement Learning (RL)-based Training of LLMs for Any AI Agent
Source: MarkTechPost How do you convert real agent traces into reinforcement learning RL transitions to improve policy LLMs...