
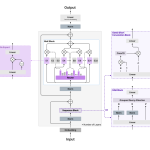
How to Build an Elastic Vector Database with Consistent Hashing, Sharding, and Live Ring Visualization for RAG Systems
Source: MarkTechPost In this tutorial, we build an elastic vector database simulator that mirrors how modern RAG systems...
Liquid AI’s New LFM2-24B-A2B Hybrid Architecture Blends Attention with Convolutions to Solve the Scaling Bottlenecks of Modern LLMs
Source: MarkTechPost The generative AI race has long been a game of ‘bigger is better.’ But as the...
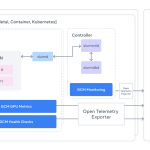
Meta AI Open Sources GCM for Better GPU Cluster Monitoring to Ensure High Performance AI Training and Hardware Reliability
Source: MarkTechPost While the tech folks obsesses over the latest Llama checkpoints, a much grittier battle is being...

Alibaba Qwen Team Releases Qwen 3.5 Medium Model Series: A Production Powerhouse Proving that Smaller AI Models are Smarter
Source: MarkTechPost The development of large language models (LLMs) has been defined by the pursuit of raw scale....
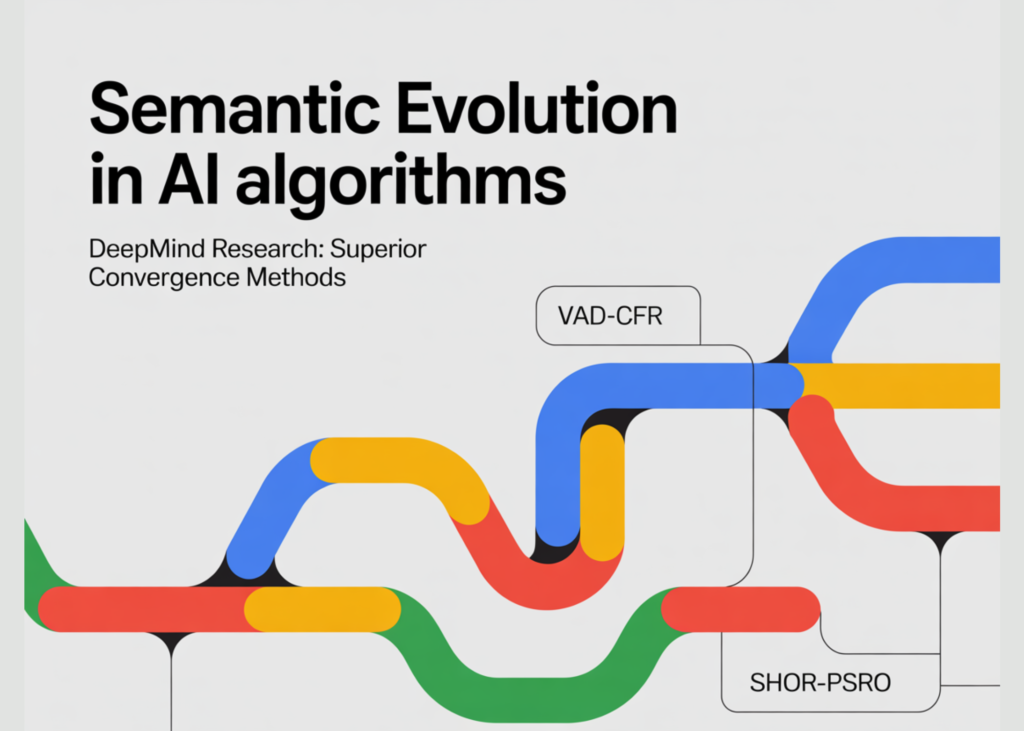
Google DeepMind Researchers Apply Semantic Evolution to Create Non Intuitive VAD-CFR and SHOR-PSRO Variants for Superior Algorithmic Convergence
Source: MarkTechPost In the competitive arena of Multi-Agent Reinforcement Learning (MARL), progress has long been bottlenecked by human...
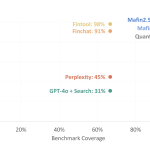
VectifyAI Launches Mafin 2.5 and PageIndex: Achieving 98.7% Financial RAG Accuracy with a New Open-Source Vectorless Tree Indexing.
Source: MarkTechPost Building a Retrieval-Augmented Generation (RAG) pipeline is easy; building one that doesn’t hallucinate during a 10-K...
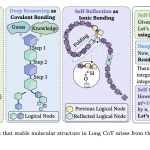
Forget Keyword Imitation: ByteDance AI Maps Molecular Bonds in AI Reasoning to Stabilize Long Chain-of-Thought Performance and Reinforcement Learning (RL) Training
Source: MarkTechPost ByteDance Seed recently dropped a research that might change how we build reasoning AI. For years,...
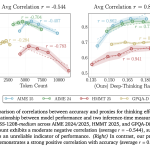
A New Google AI Research Proposes Deep-Thinking Ratio to Improve LLM Accuracy While Cutting Total Inference Costs by Half
Source: MarkTechPost For the last few years, the AI world has followed a simple rule: if you want...

Is There a Community Edition of Palantir? Meet OpenPlanter: An Open Source Recursive AI Agent for Your Micro Surveillance Use Cases
Source: MarkTechPost The balance of power in the digital age is shifting. While governments and large corporations have...

NVIDIA Releases DreamDojo: An Open-Source Robot World Model Trained on 44,711 Hours of Real-World Human Video Data
Source: MarkTechPost Building simulators for robots has been a long term challenge. Traditional engines require manual coding of...