
Can We Improve Llama 3’s Reasoning Through Post-Training Alone? ASTRO Shows +16% to +20% Benchmark Gains
Source: MarkTechPost Improving the reasoning capabilities of large language models (LLMs) without architectural changes is a core challenge...

Crome: Google DeepMind’s Causal Framework for Robust Reward Modeling in LLM Alignment
Source: MarkTechPost Reward models are fundamental components for aligning LLMs with human feedback, yet they face the challenge...
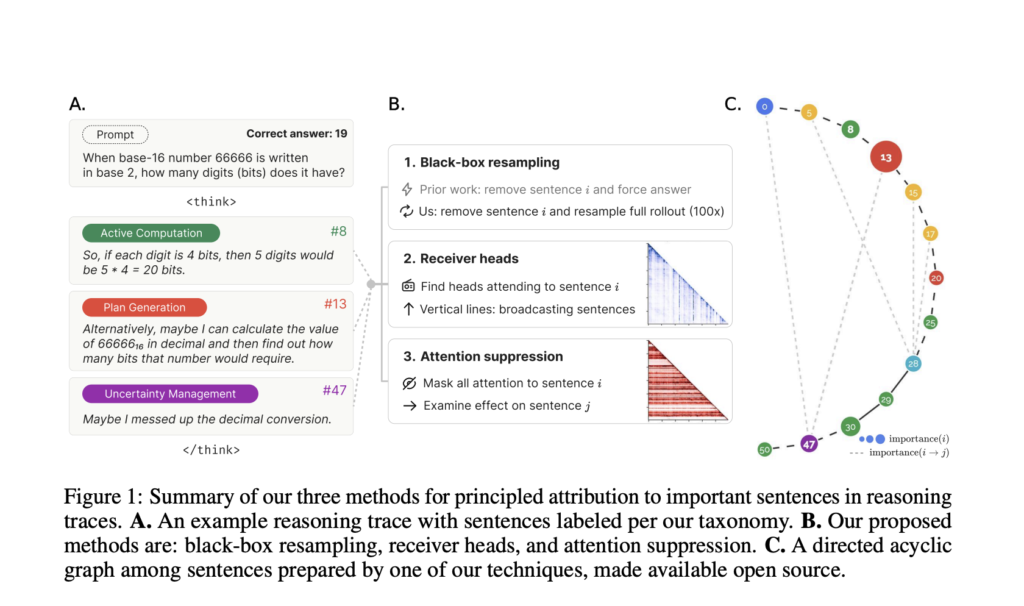
Thought Anchors: A Machine Learning Framework for Identifying and Measuring Key Reasoning Steps in Large Language Models with Precision
Source: MarkTechPost Understanding the Limits of Current Interpretability Tools in LLMs AI models, such as DeepSeek and GPT...
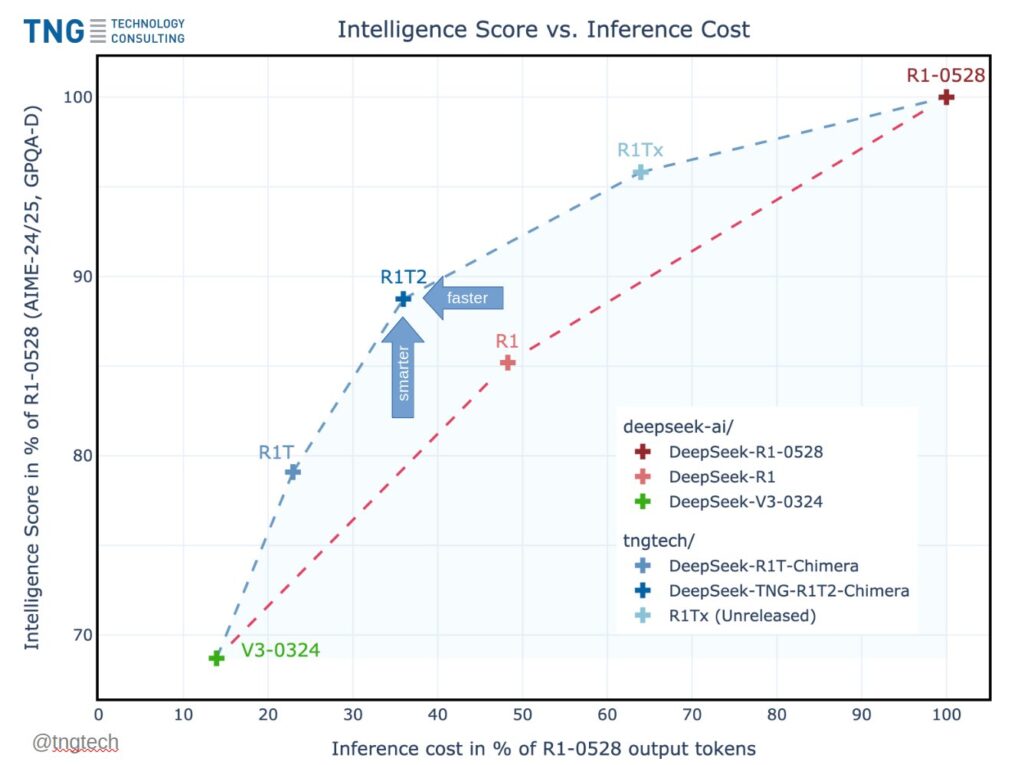
DeepSeek R1T2 Chimera: 200% Faster Than R1-0528 With Improved Reasoning and Compact Output
Source: MarkTechPost TNG Technology Consulting has unveiled DeepSeek-TNG R1T2 Chimera, a new Assembly-of-Experts (AoE) model that blends intelligence...

Shanghai Jiao Tong Researchers Propose OctoThinker for Reinforcement Learning-Scalable LLM Development
Source: MarkTechPost Introduction: Reinforcement Learning Progress through Chain-of-Thought Prompting LLMs have shown excellent progress in complex reasoning tasks...
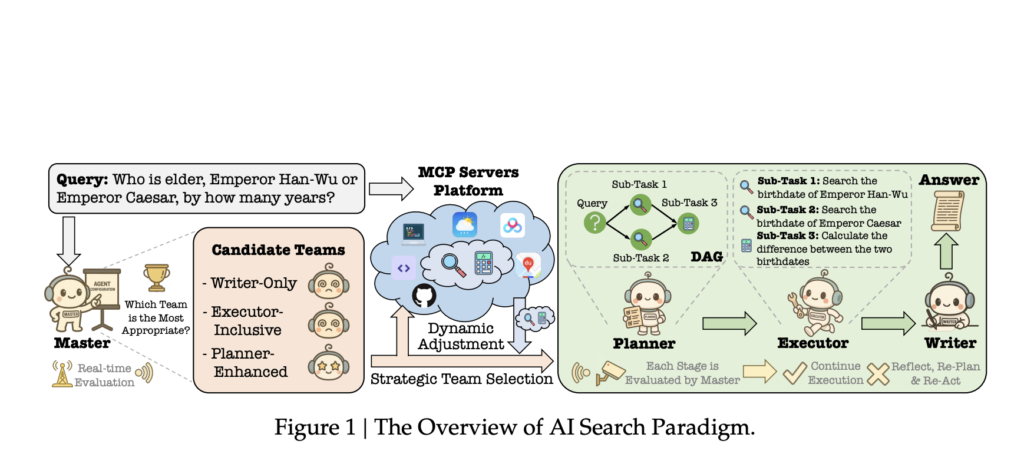
Baidu Researchers Propose AI Search Paradigm: A Multi-Agent Framework for Smarter Information Retrieval
Source: MarkTechPost The Need for Cognitive and Adaptive Search Engines Modern search systems are evolving rapidly as the...

Baidu Open Sources ERNIE 4.5: LLM Series Scaling from 0.3B to 424B Parameters
Source: MarkTechPost Baidu has officially open-sourced its latest ERNIE 4.5 series, a powerful family of foundation models designed...

OMEGA: A Structured Math Benchmark to Probe the Reasoning Limits of LLMs
Source: MarkTechPost Introduction to Generalization in Mathematical Reasoning Large-scale language models with long CoT reasoning, such as DeepSeek-R1,...
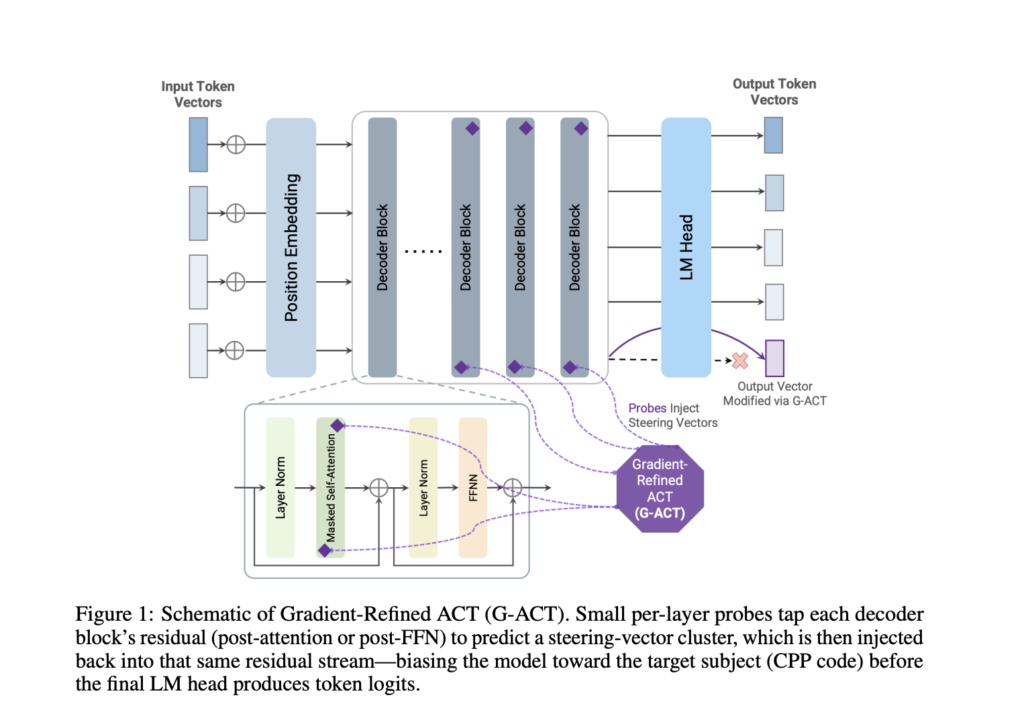
University of Michigan Researchers Propose G-ACT: A Scalable Machine Learning Framework to Steer Programming Language Bias in LLMs
Source: MarkTechPost LLMs and the Need for Scientific Code Control LLMs have rapidly evolved into complex natural language...

Alibaba Qwen Team Releases Qwen-VLo: A Unified Multimodal Understanding and Generation Model
Source: MarkTechPost The Alibaba Qwen team has introduced Qwen-VLo, a new addition to its Qwen model family, designed...