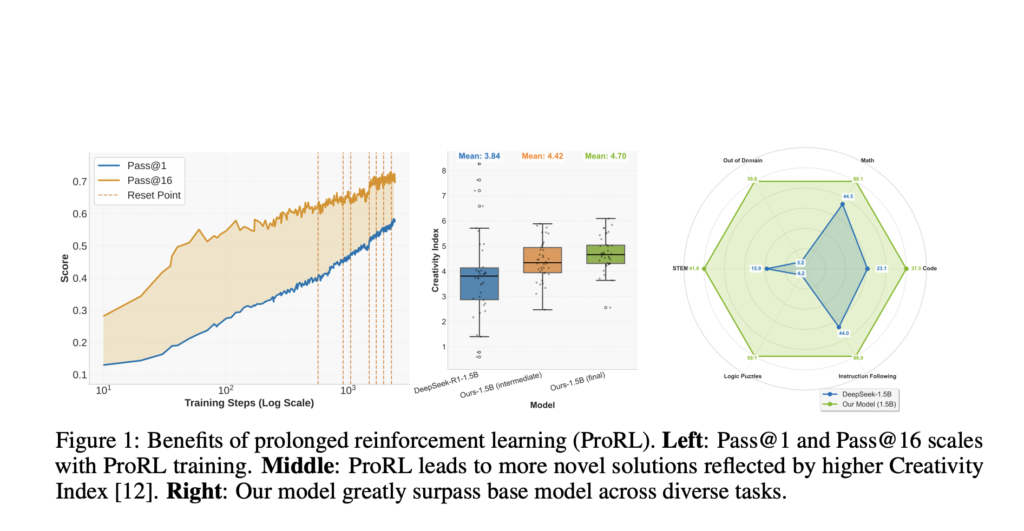
NVIDIA Introduces ProRL: Long-Horizon Reinforcement Learning Boosts Reasoning and Generalization
Source: MarkTechPost Recent advances in reasoning-focused language models have marked a major change in AI by scaling test-time...

NVIDIA AI Releases Llama Nemotron Nano VL: A Compact Vision-Language Model Optimized for Document Understanding
Source: MarkTechPost NVIDIA has introduced Llama Nemotron Nano VL, a vision-language model (VLM) designed to address document-level understanding...
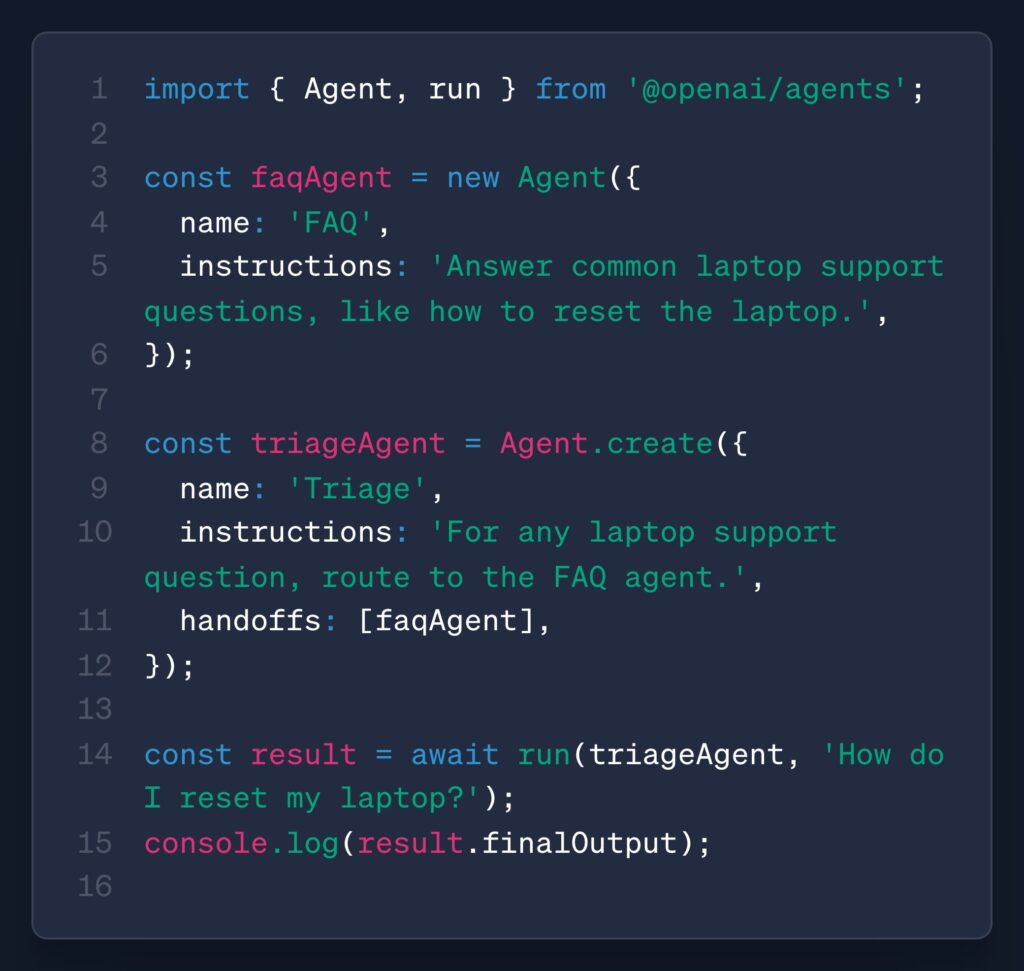
OpenAI Introduces Four Key Updates to Its AI Agent Framework
Source: MarkTechPost OpenAI has announced a set of targeted updates to its AI agent development stack, aimed at...
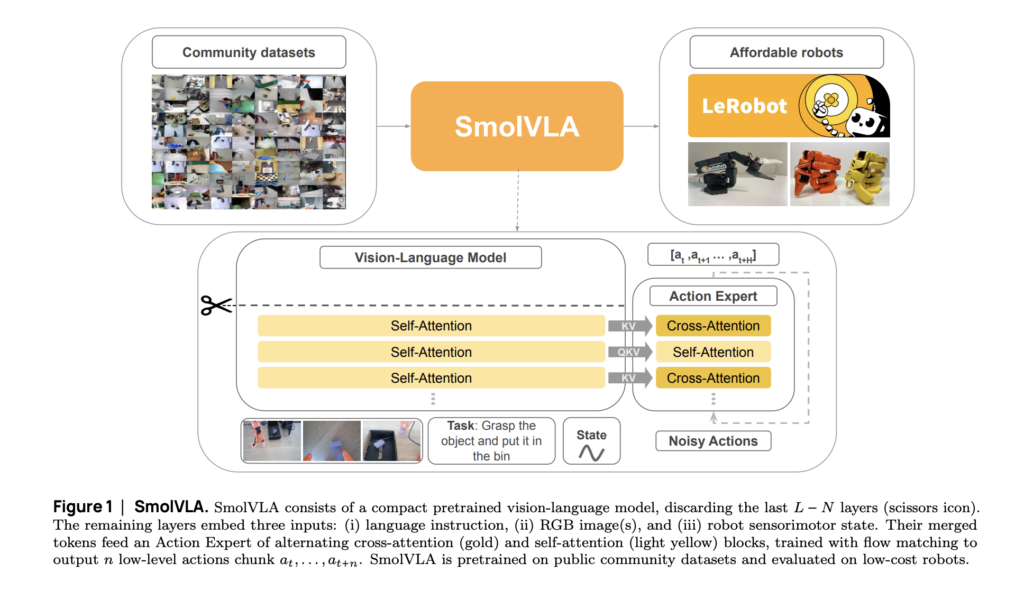
Hugging Face Releases SmolVLA: A Compact Vision-Language-Action Model for Affordable and Efficient Robotics
Source: MarkTechPost Despite recent progress in robotic control via large-scale vision-language-action (VLA) models, real-world deployment remains constrained by...
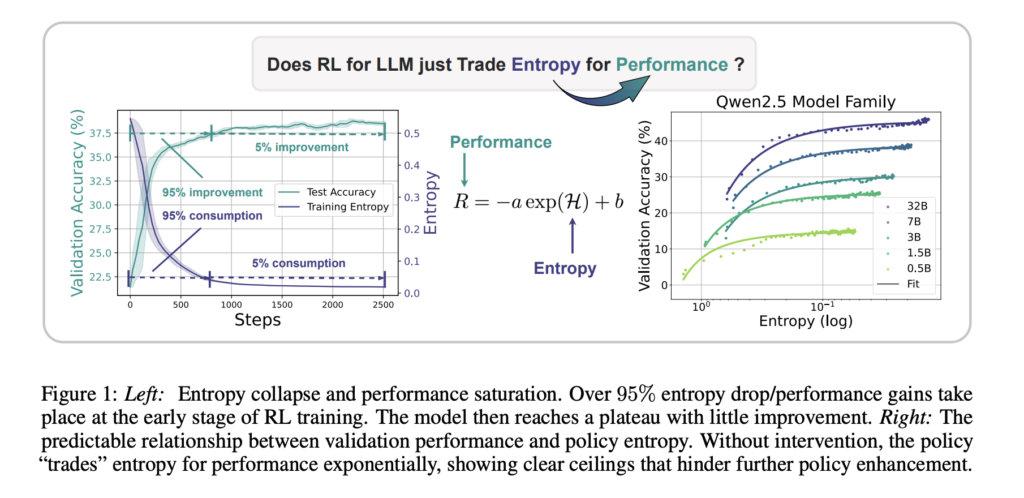
From Exploration Collapse to Predictable Limits: Shanghai AI Lab Proposes Entropy-Based Scaling Laws for Reinforcement Learning in LLMs
Source: MarkTechPost Recent advances in reasoning-centric large language models (LLMs) have expanded the scope of reinforcement learning (RL)...
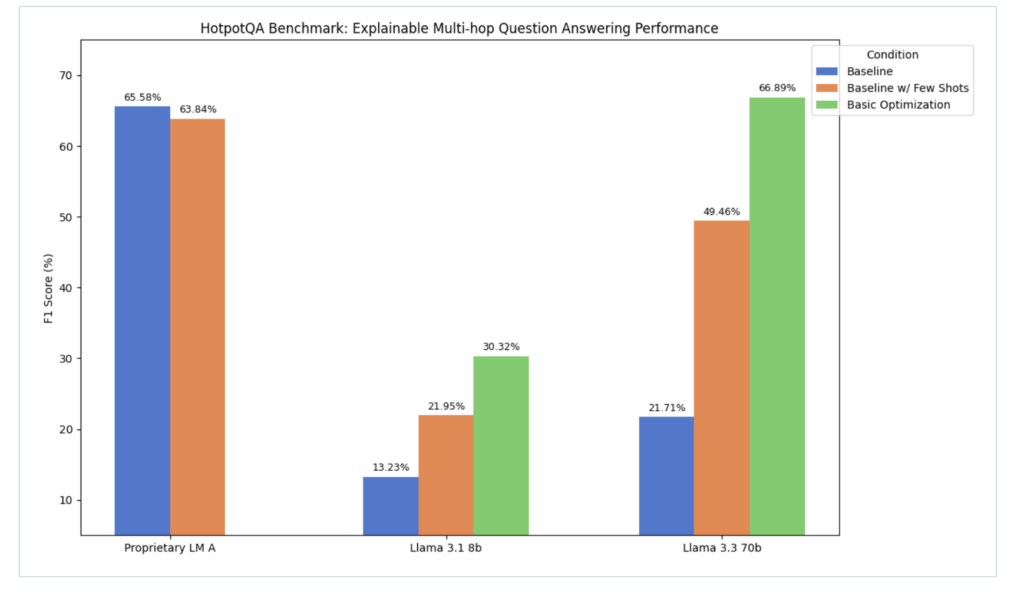
Meta Releases Llama Prompt Ops: A Python Package that Automatically Optimizes Prompts for Llama Models
Source: MarkTechPost The growing adoption of open-source large language models such as Llama has introduced new integration challenges...
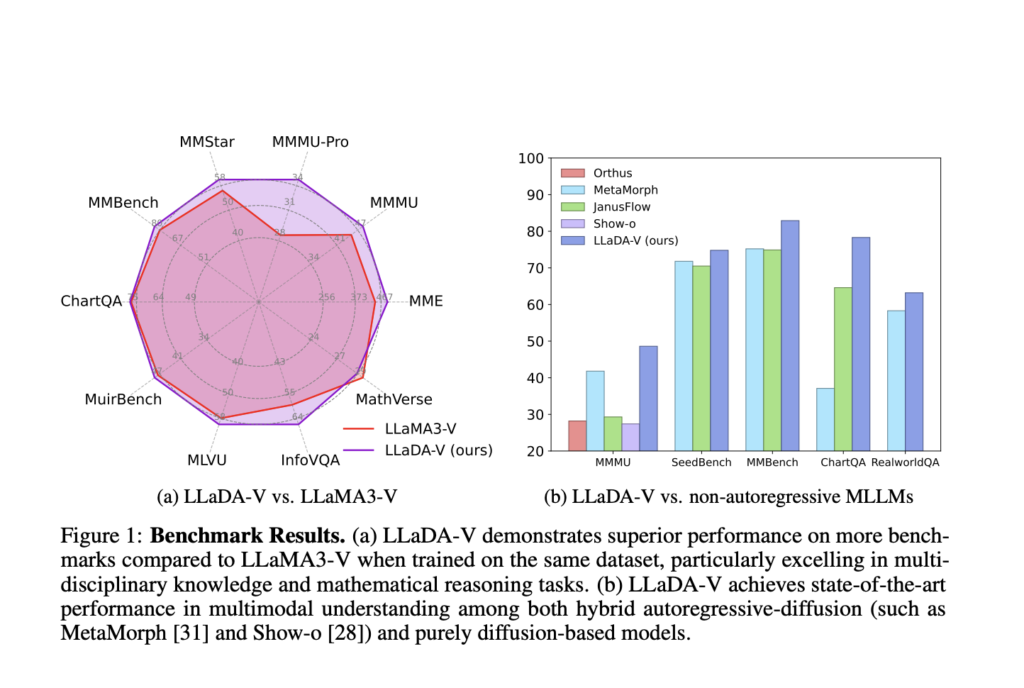
This AI Paper Introduces LLaDA-V: A Purely Diffusion-Based Multimodal Large Language Model for Visual Instruction Tuning and Multimodal Reasoning
Source: MarkTechPost Multimodal large language models (MLLMs) are designed to process and generate content across various modalities, including...

NVIDIA AI Introduces Fast-dLLM: A Training-Free Framework That Brings KV Caching and Parallel Decoding to Diffusion LLMs
Source: MarkTechPost Diffusion-based large language models (LLMs) are being explored as a promising alternative to traditional autoregressive models,...
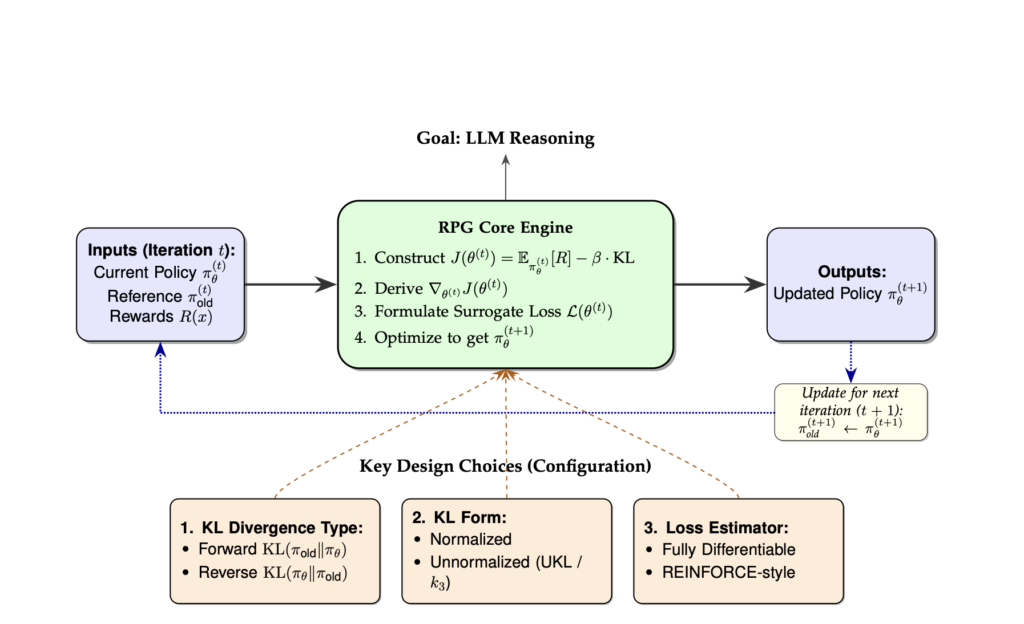
Off-Policy Reinforcement Learning RL with KL Divergence Yields Superior Reasoning in Large Language Models
Source: MarkTechPost Policy gradient methods have significantly advanced the reasoning capabilities of LLMs, particularly through RL. A key...
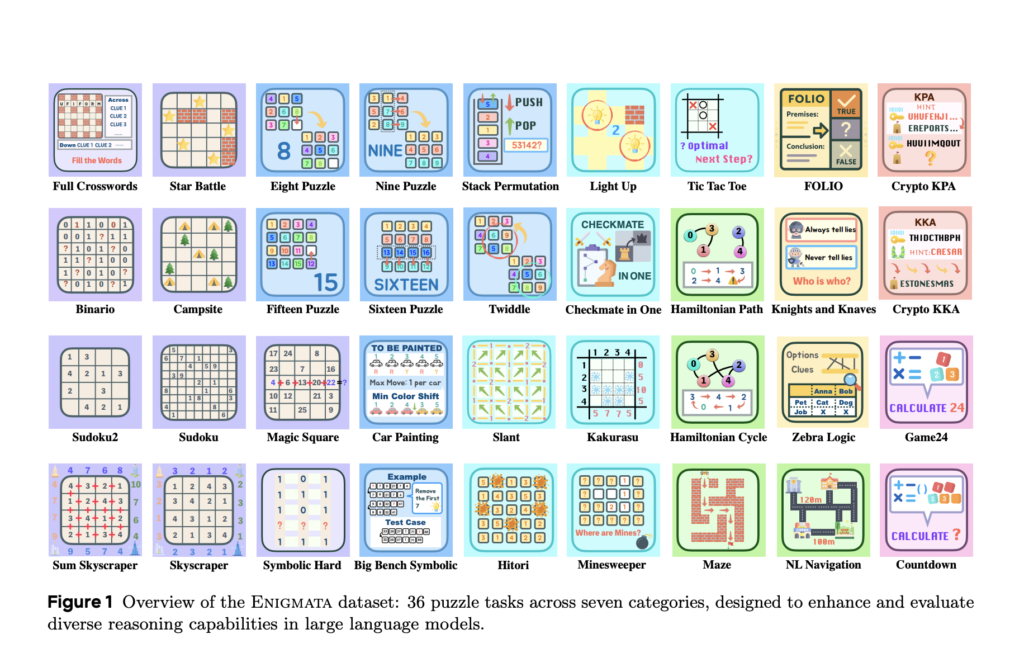
Enigmata’s Multi-Stage and Mix-Training Reinforcement Learning Recipe Drives Breakthrough Performance in LLM Puzzle Reasoning
Source: MarkTechPost Large Reasoning Models (LRMs), trained from LLMs using reinforcement learning (RL), demonstrated great performance in complex...