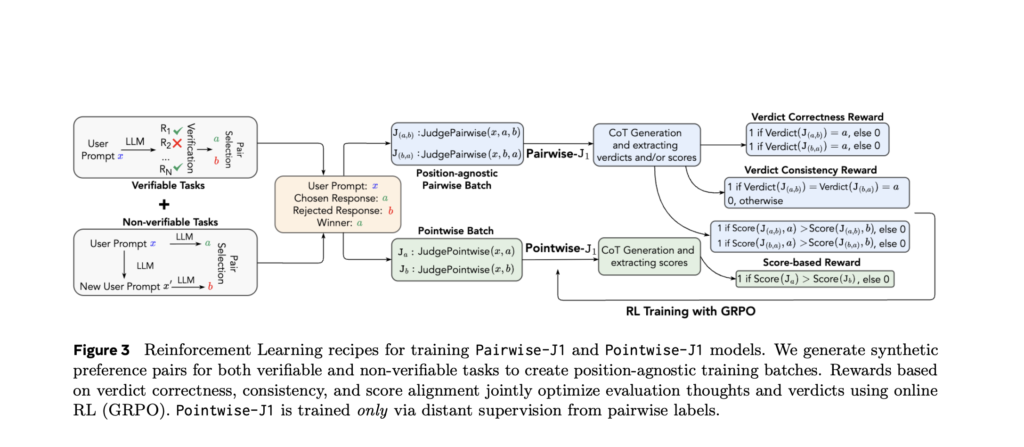
Meta Researchers Introduced J1: A Reinforcement Learning Framework That Trains Language Models to Judge With Reasoned Consistency and Minimal Data
Source: MarkTechPost Large language models are now being used for evaluation and judgment tasks, extending beyond their traditional...

Sampling Without Data is Now Scalable: Meta AI Releases Adjoint Sampling for Reward-Driven Generative Modeling
Source: MarkTechPost Data Scarcity in Generative Modeling Generative models traditionally rely on large, high-quality datasets to produce samples...

Google AI Releases MedGemma: An Open Suite of Models Trained for Performance on Medical Text and Image Comprehension
Source: MarkTechPost At Google I/O 2025, Google introduced MedGemma, an open suite of models designed for multimodal medical...

Enhancing Language Model Generalization: Bridging the Gap Between In-Context Learning and Fine-Tuning
Source: MarkTechPost Language models (LMs) have great capabilities as in-context learners when pretrained on vast internet text corpora,...

Researchers from Renmin University and Huawei Propose MemEngine: A Unified Modular AI Library for Customizing Memory in LLM-Based Agents
Source: MarkTechPost LLM-based agents are increasingly used across various applications because they handle complex tasks and assume multiple...

Salesforce AI Researchers Introduce UAEval4RAG: A New Benchmark to Evaluate RAG Systems’ Ability to Reject Unanswerable Queries
Source: MarkTechPost While RAG enables responses without extensive model retraining, current evaluation frameworks focus on accuracy and relevance...

Chain-of-Thought May Not Be a Window into AI’s Reasoning: Anthropic’s New Study Reveals Hidden Gaps
Source: MarkTechPost Chain-of-thought (CoT) prompting has become a popular method for improving and interpreting the reasoning processes of...

Reinforcement Learning Makes LLMs Search-Savvy: Ant Group Researchers Introduce SEM to Optimize Tool Usage and Reasoning Efficiency
Source: MarkTechPost Recent progress in LLMs has shown their potential in performing complex reasoning tasks and effectively using...
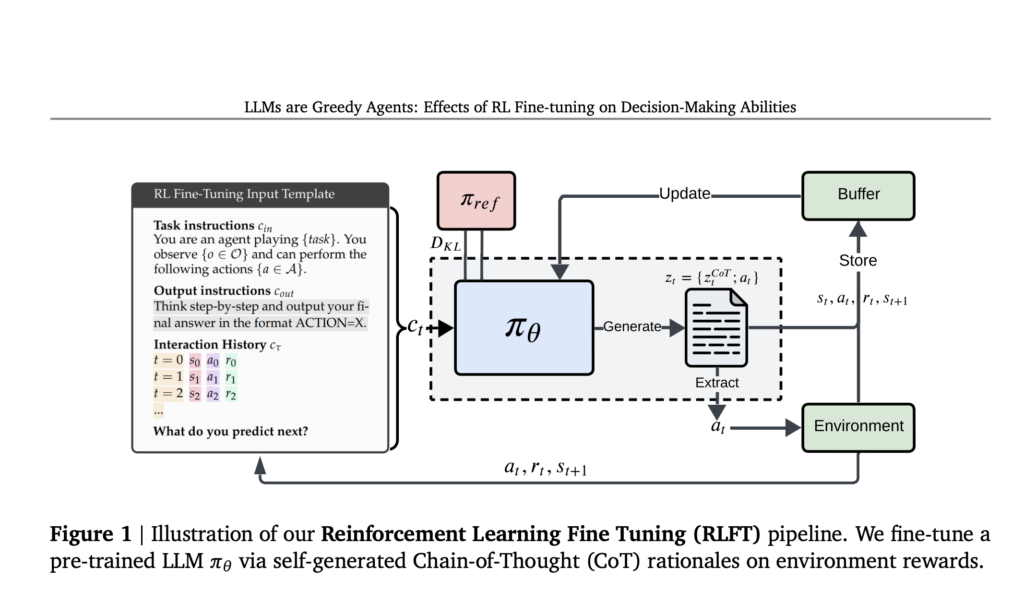
LLMs Struggle to Act on What They Know: Google DeepMind Researchers Use Reinforcement Learning Fine-Tuning to Bridge the Knowing-Doing Gap
Source: MarkTechPost Language models trained on vast internet-scale datasets have become prominent language understanding and generation tools. Their...
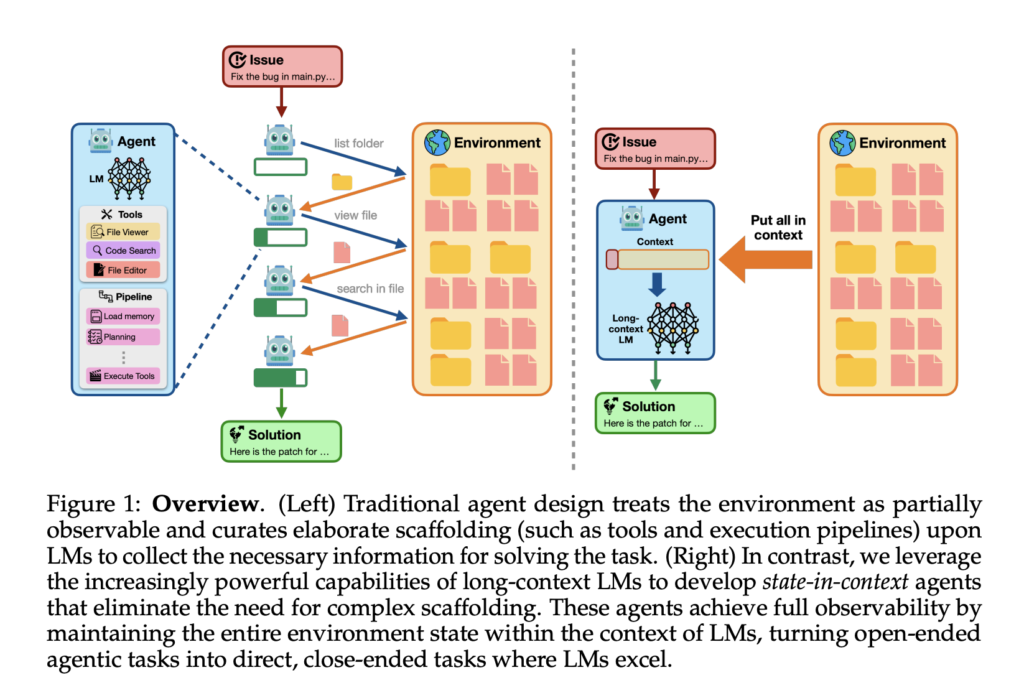
SWE-Bench Performance Reaches 50.8% Without Tool Use: A Case for Monolithic State-in-Context Agents
Source: MarkTechPost Recent advancements in LM agents have shown promising potential for automating intricate real-world tasks. These agents...