
Moonshot AI Releases Kimi K3: A 2.8 Trillion Parameter Open MoE Model With Kimi Delta Attention and 1M Context
Source: MarkTechPost Moonshot AI just released Kimi K3. It is a 2.8-trillion-parameter model with native vision and a...
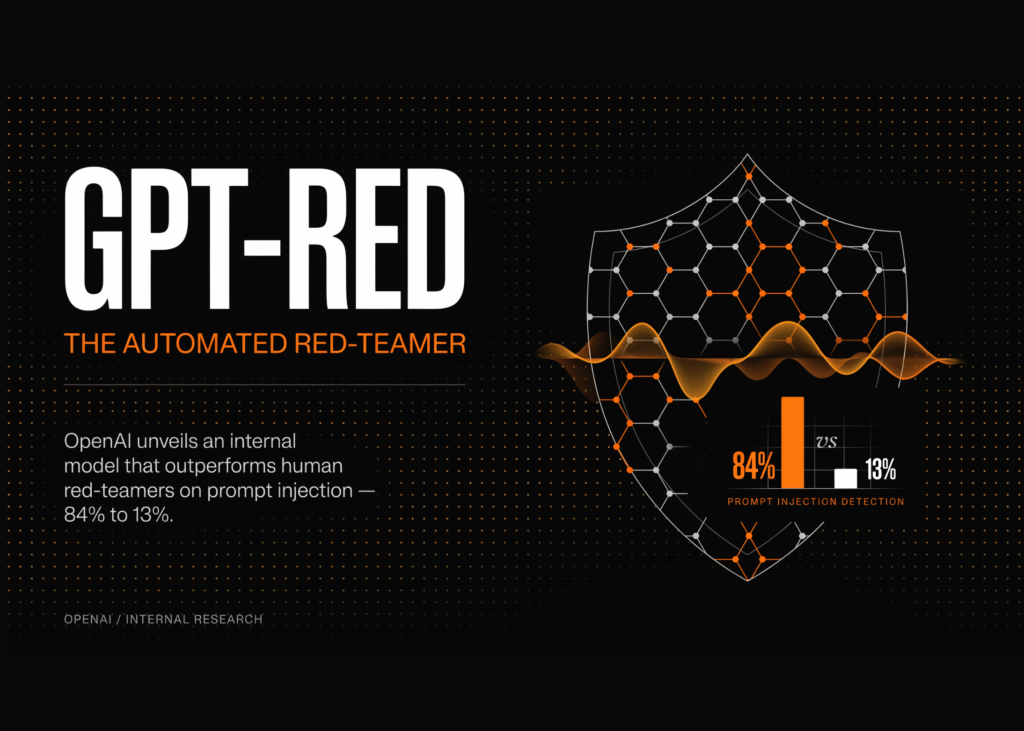
OpenAI Details GPT-Red: An Internal Automated Red-Teaming Model That Beat Human Red-Teamers 84% To 13% On Prompt Injection
Source: MarkTechPost This week, OpenAI published details of GPT-Red, an internal-only automated red-teaming model. Its job is to...

SpaceXAI Open-Sources Grok Build: The Rust Agent Harness, TUI, and Tool Layer Behind Its Coding CLI
Source: MarkTechPost SpaceXAI has open-sourced Grok Build, the terminal-based AI coding agent behind its grok CLI. The source...

Thinking Machines Lab Releases Inkling: A 975B-Parameter Open-Weights Multimodal MoE With 41B Active Parameters And Controllable Thinking Effort
Source: MarkTechPost Thinking Machines Lab just released Inkling, their first model trained from scratch, weights are open, fine-tunable...

Soofi Consortium Releases Soofi S 30B-A3B: An Open Hybrid Mamba-Transformer MoE Foundation Model For German And English
Source: MarkTechPost A German research consortium has published the pretraining report for Soofi S 30B-A3B. It is an...

Building a Gin Config Controlled PyTorch Pipeline with Configurable MLP Variants, Cosine Scheduling, and Runtime Parameter Overrides
Source: MarkTechPost In this tutorial, we implement a Gin Config–controlled PyTorch experiment pipeline in which the executable training...

PrismML Releases Bonsai 27B: 1-bit and Ternary Builds of Qwen3.6-27B That Run on Laptops and Phones
Source: MarkTechPost PrismML just released Bonsai 27B. It is a low-bit representation of Qwen3.6-27B, not a new pretrain....

Meet Blume: An Open-Source, Zero-Config Documentation Framework That Ships AI-Ready Docs From a Markdown Folder
Source: MarkTechPost Hayden Bleasel, an expert developer from OpenAI, released Blume, an open-source documentation framework. Blume shipped to...

Stanford Researchers Introduce TRACE: A Capability-Targeted Agentic Training System That Turns Recurrent Agent Failures Into Synthetic RL Environment
Source: MarkTechPost Agentic LLMs often fail the same way, again and again. A Stanford research team traced this...

Meet NeuroVFM: A New Neuroimaging Foundation Model Trained With Vol-JEPA on Uncurated Clinical MRI and CT Volumes
Source: MarkTechPost Frontier models learn mostly from public internet data. However, clinical neuroimaging rarely appears there, because MRI...