
A Coding Implementation of Extracting Structured Data Using LangSmith, Pydantic, LangChain, and Claude 3.7 Sonnet
Source: MarkTechPost Unlock the power of structured data extraction with LangChain and Claude 3.7 Sonnet, transforming raw text...

This AI Paper from NVIDIA Introduces Cosmos-Reason1: A Multimodal Model for Physical Common Sense and Embodied Reasoning
Source: MarkTechPost Artificial intelligence systems designed for physical settings require more than just perceptual abilities—they must also reason...

TokenSet: A Dynamic Set-Based Framework for Semantic-Aware Visual Representation
Source: MarkTechPost Visual generation frameworks follow a two-stage approach: first compressing visual signals into latent representations and then...

Lyra: A Computationally Efficient Subquadratic Architecture for Biological Sequence Modeling
Source: MarkTechPost Deep learning architectures like CNNs and Transformers have significantly advanced biological sequence modeling by capturing local...
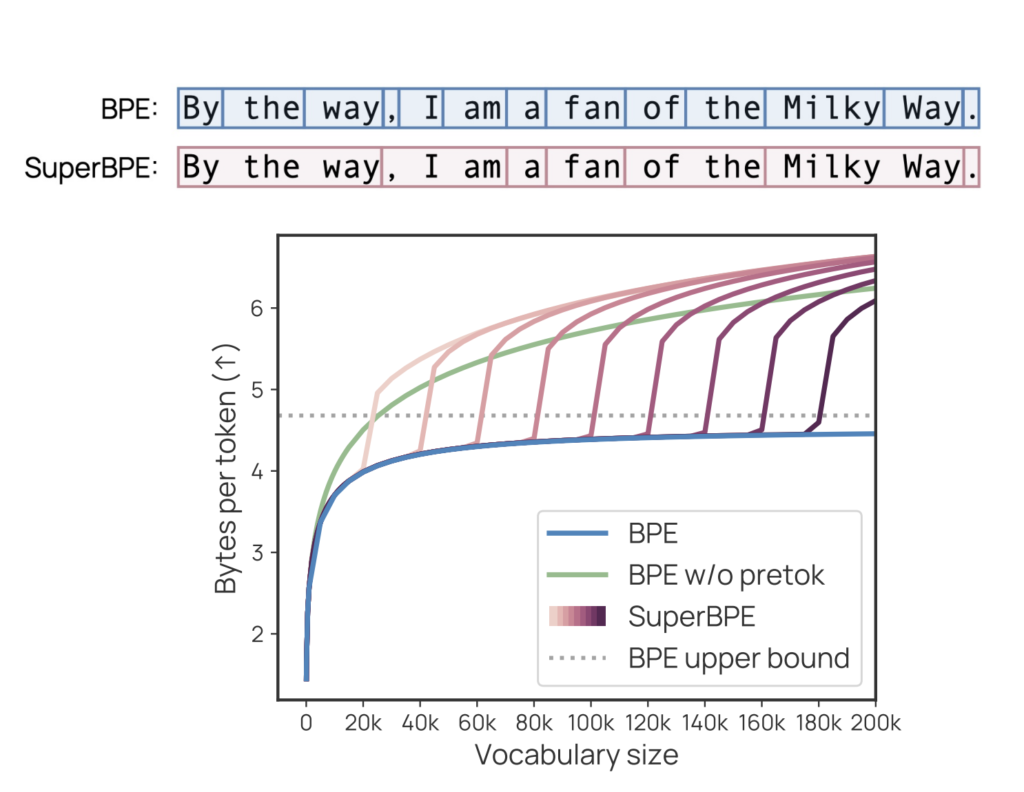
SuperBPE: Advancing Language Models with Cross-Word Tokenization
Source: MarkTechPost Language models (LMs) face a fundamental challenge in how to perceive textual data through tokenization. Current...
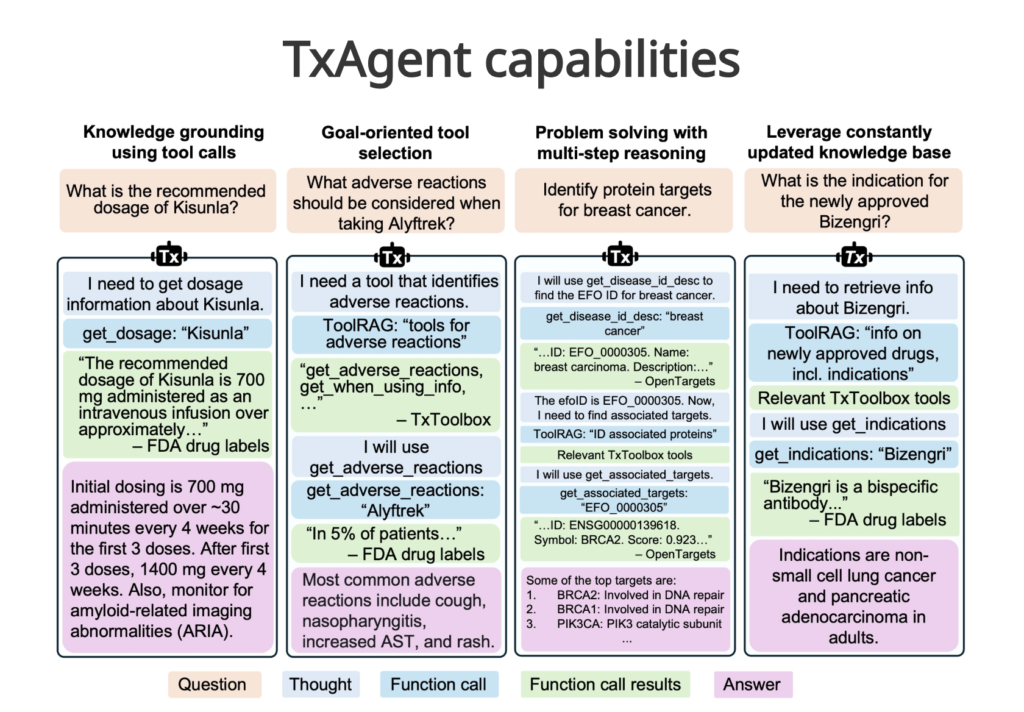
TxAgent: An AI Agent that Delivers Evidence-Grounded Treatment Recommendations by Combining Multi-Step Reasoning with Real-Time Biomedical Tool Integration
Source: MarkTechPost Precision therapy has emerged as a critical approach in healthcare, tailoring treatments to individual patient profiles...
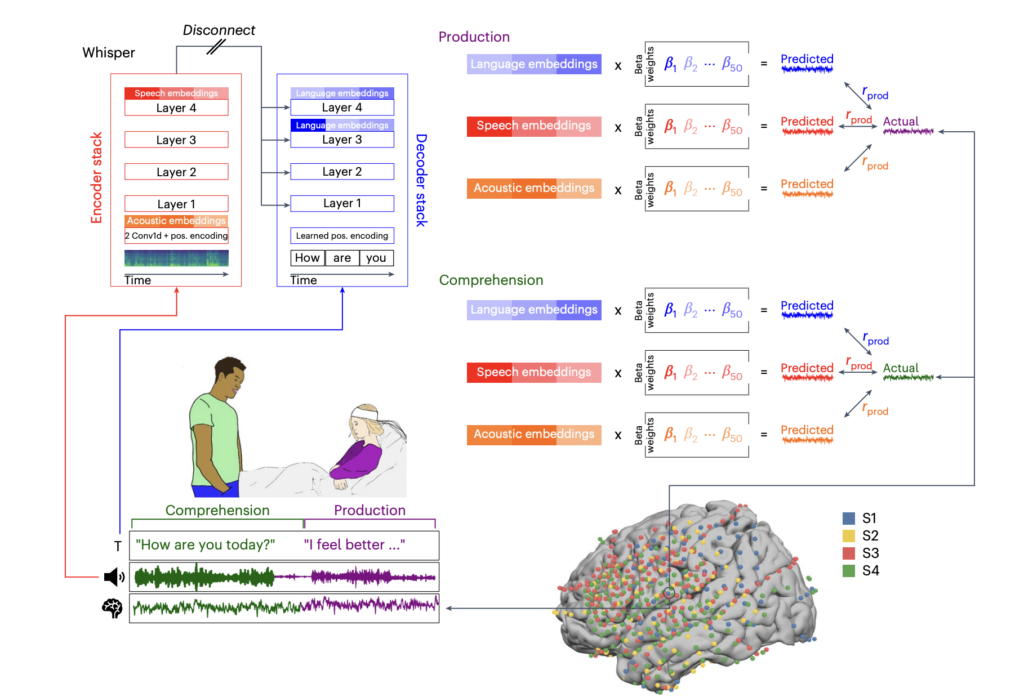
A Unified Acoustic-to-Speech-to-Language Embedding Space Captures the Neural Basis of Natural Language Processing in Everyday Conversations
Source: MarkTechPost Language processing in the brain presents a challenge due to its inherently complex, multidimensional, and context-dependent...

Achieving Critical Reliability in Instruction-Following with LLMs: How to Achieve AI Customer Service That’s 100% Reliable
Source: MarkTechPost Ensuring reliable instruction-following in LLMs remains a critical challenge. This is particularly important in customer-facing applications,...
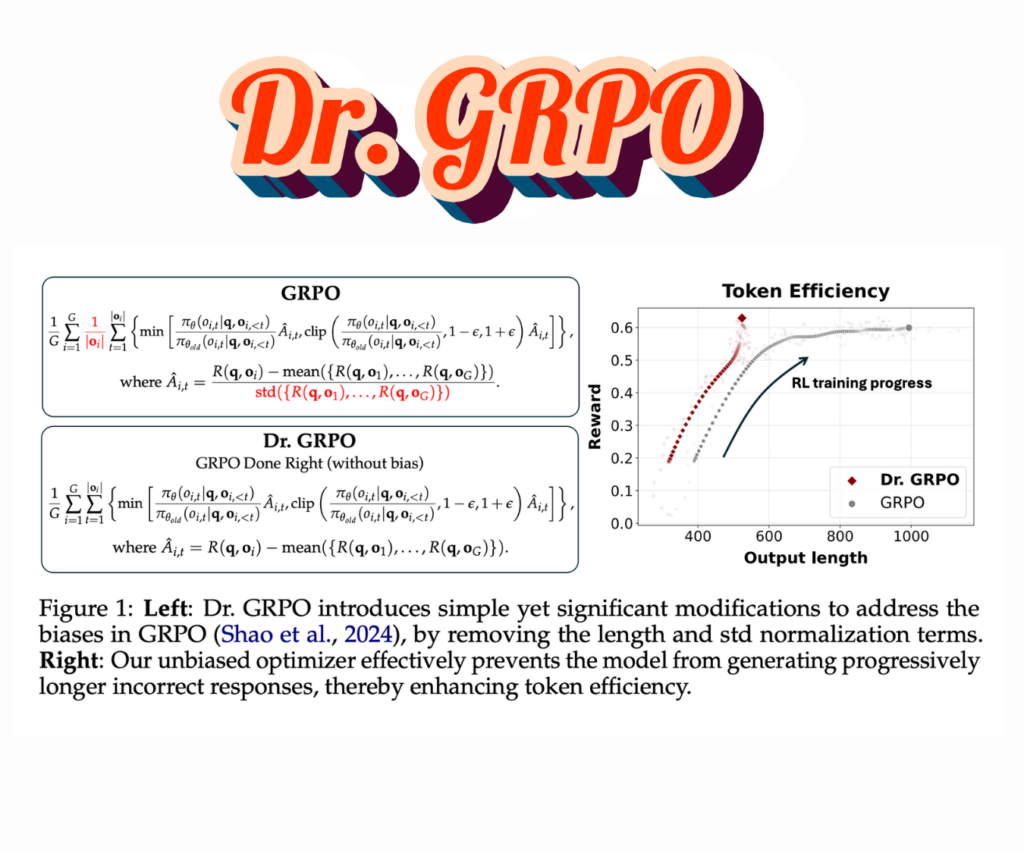
Sea AI Lab Researchers Introduce Dr. GRPO: A Bias-Free Reinforcement Learning Method that Enhances Math Reasoning Accuracy in Large Language Models Without Inflating Responses
Source: MarkTechPost A critical advancement in recent times has been exploring reinforcement learning (RL) techniques to improve LLMs...
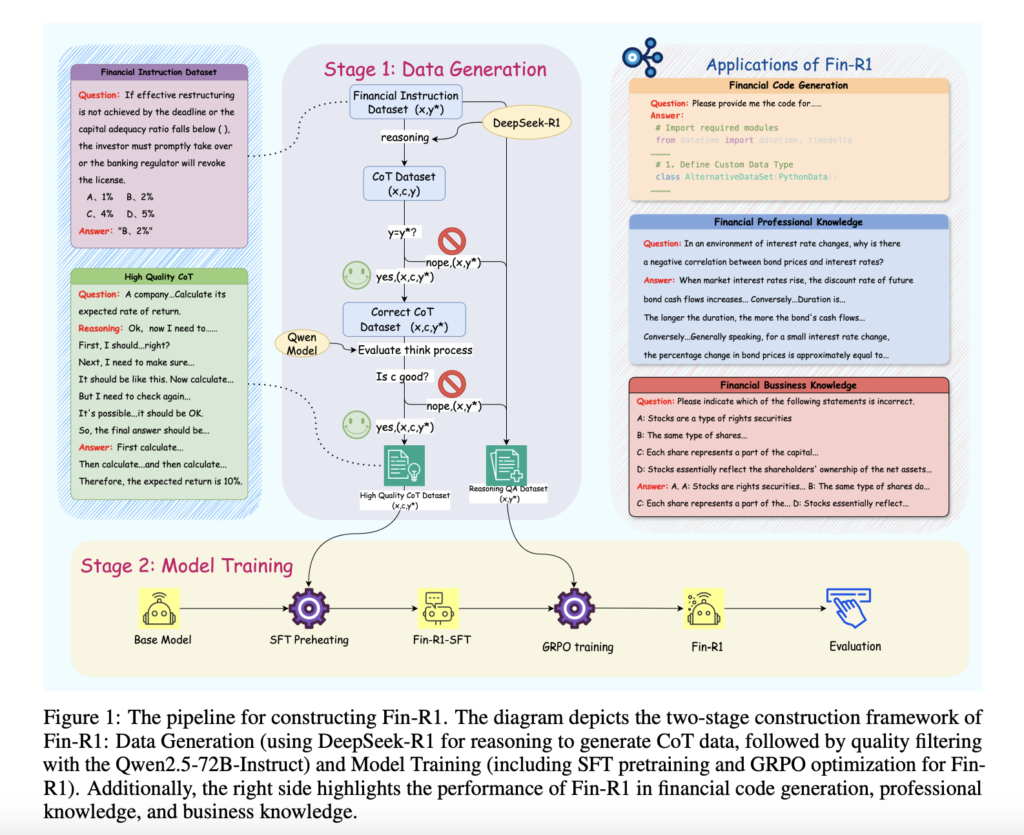
Fin-R1: A Specialized Large Language Model for Financial Reasoning and Decision-Making
Source: MarkTechPost LLMs are advancing rapidly across multiple domains, yet their effectiveness in tackling complex financial problems remains...