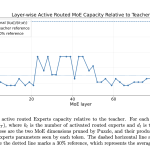
NVIDIA Releases Nemotron-Labs-3-Puzzle-75B-A9B: A Compressed Hybrid MoE LLM Delivering 2.03x Server Throughput at Matched User Throughput
Source: MarkTechPost Large hybrid MoE models like Nemotron-3-Super are accurate but expensive to serve. Their active parameters, KV...

Datalab Lift vs the Field: How a 9B Schema-First Extractor Compares with NuExtract3, LlamaExtract, Marker, and Docling
Source: MarkTechPost Datalab’s Lift is a focused document extraction tool with a specific promise: give it a PDF...

Robbyant Releases LingBot-VLA 2.0: An Open-Source 6B Vision-Language-Action (VLA) Model for Cross-Embodiment Robot Manipulation
Source: MarkTechPost Ant Group’s Robbyant has released LingBot-VLA 2.0, a Vision-Language-Action (VLA) foundation model for robots. The release...

SpaceXAI Releases Grok 4.5, a Cursor-Trained Model for Coding, Agentic Tasks, and Knowledge Work at $2/M Input
Source: MarkTechPost SpaceXAI just released Grok 4.5. The company calls it its smartest model to date. It targets...
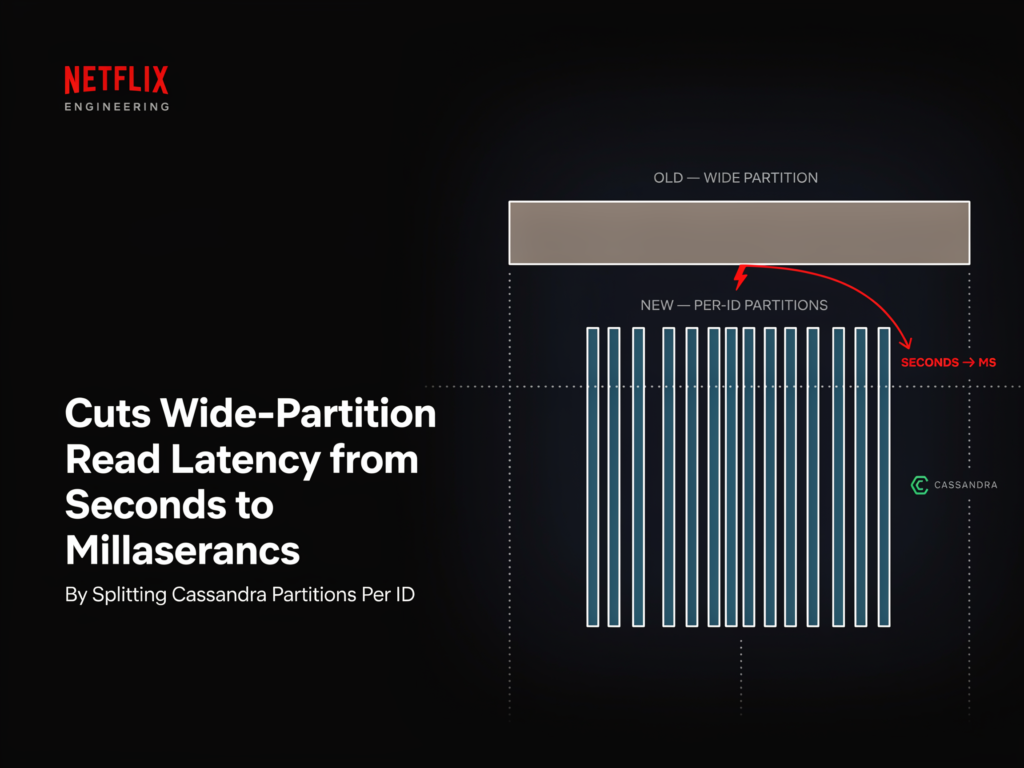
Netflix AI Team Cuts Wide-Partition Read Latency from Seconds to Milliseconds by Splitting Cassandra Partitions Per ID
Source: MarkTechPost Netflix’s engineering team published a method for handling wide partitions in Apache Cassandra. The research work...

OpenAI Releases GPT-Live and GPT-Live-1 mini: Full-Duplex Voice Models That Delegate Deeper Reasoning to GPT-5.5
Source: MarkTechPost Today, OpenAI released GPT-Live. It is a new generation of voice models. GPT-Live now powers the...

Ant Group’s Robbyant Open-Sources LingBot-Vision: A 1B Boundary-Centric Vision Foundation Model for Dense Spatial Perception
Source: MarkTechPost Robbyant, the embodied-AI company within Ant Group, has open-sourced LingBot-Vision, a family of self-supervised Vision Transformers...

NVIDIA Releases Audex (Nemotron-Labs-Audex-30B-A3B): A Unified Audio-Text LLM That Preserves the Text Intelligence of Its Backbone
Source: MarkTechPost NVIDIA has released Audex (Nemotron-Labs-Audex-30B-A3B), a unified audio-text large language model. It understands and generates both...

Liquid AI Open-Sources Antidoom: A Final Token Preference Optimization (FTPO) Method that Reduces Doom Loops in Reasoning Models
Source: MarkTechPost Liquid AI has released Antidoom, an open-source method that targets a common failure mode in reasoning...

Tencent Releases Hy3: An Open 295B Mixture-of-Experts (MoE) Model with 21B Active Parameters and 256K Context
Source: MarkTechPost Tencent’s Hy team released Hy3. Hy3 is a 295B-parameter Mixture-of-Experts (MoE) model. It activates only 21B...