
OpenAI Releases GPT-Realtime-2.1 and GPT-Realtime-2.1-mini for Low-Latency Voice Agents in the API
Source: MarkTechPost OpenAI has released two new Realtime models in its API. They are named gpt-realtime-2.1 and gpt-realtime-2.1-mini....

Sakana AI Launches Sakana Translate, a Namazu-Powered Japanese–English–Chinese Translation Tool With Translate, Proofread, and Ask Modes
Source: MarkTechPost Sakana AI has added a new feature called Sakana Translate to its chat service, Sakana Chat....

Synthetic Sciences Releases OpenScience: An Open-Source, Model-Agnostic AI Workbench for Machine Learning, Biology, Physics, and Chemistry Research
Source: MarkTechPost Synthetic Sciences has released OpenScience, an open-source AI workbench for scientific research. It is licensed under...
Training Gemma-3 for Structured Mathematical Reasoning with Tunix GRPO, LoRA Adapters, and GSM8K Rewards
Source: MarkTechPost In this tutorial, we build an end-to-end GRPO training workflow that teaches Gemma-3 to reason through...

Meituan Releases LongCat-2.0: A 1.6T-Parameter Open MoE Model with Native 1M Context and LongCat Sparse Attention
Source: MarkTechPost Meituan has released LongCat-2.0, a large-scale Mixture-of-Experts (MoE) language model. It carries 1.6 trillion total parameters...

LlamaIndex ‘legal-kb’: Agentic Retrieval over Index v2 with retrieve, find, read, and grep Tools
Source: MarkTechPost LlamaIndex has published legal-kb, a public reference application on GitHub. It is described as a knowledge...

Anthropic Launches Claude Science Beta: A Multi-Agent AI Workbench for Reproducible Genomics, Proteomics, and Cheminformatics Pipelines
Source: MarkTechPost This week, Anthropic released Claude Science. It is an app for scientists, available in beta. It...
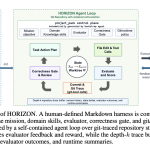
NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion
Source: MarkTechPost NVIDIA Research introduced HORIZON, a hands-free agent framework for hardware design. It treats hardware design as...

Mistral AI Releases Leanstral 1.5: An Apache-2.0 Lean 4 Code Agent Model Solving 587 of 672 PutnamBench Problems
Source: MarkTechPost Today, Mistral AI released Leanstral 1.5. It is a code agent model built for Lean 4....

Designing a Schema-Guided Invoice Intelligence Pipeline with lift-pdf for Accounts-Payable Extraction, Validation, and Ledger Generation
Source: MarkTechPost In this tutorial, we build an end-to-end accounts-payable extraction pipeline with lift-pdf, using synthetic invoice PDFs...