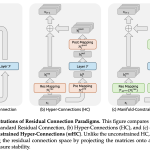
DeepSeek Researchers Apply a 1967 Matrix Normalization Algorithm to Fix Instability in Hyper Connections
Source: MarkTechPost DeepSeek researchers are trying to solve a precise issue in large language model training. Residual connections...

Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long Horizon LLM Agents
Source: MarkTechPost Recursive Language Models aim to break the usual trade off between context length, accuracy and cost...
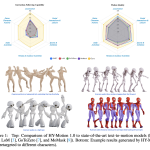
Tencent Released Tencent HY-Motion 1.0: A Billion-Parameter Text-to-Motion Model Built on the Diffusion Transformer (DiT) Architecture and Flow Matching
Source: MarkTechPost Tencent Hunyuan’s 3D Digital Human team has released HY-Motion 1.0, an open weight text-to-3D human motion...
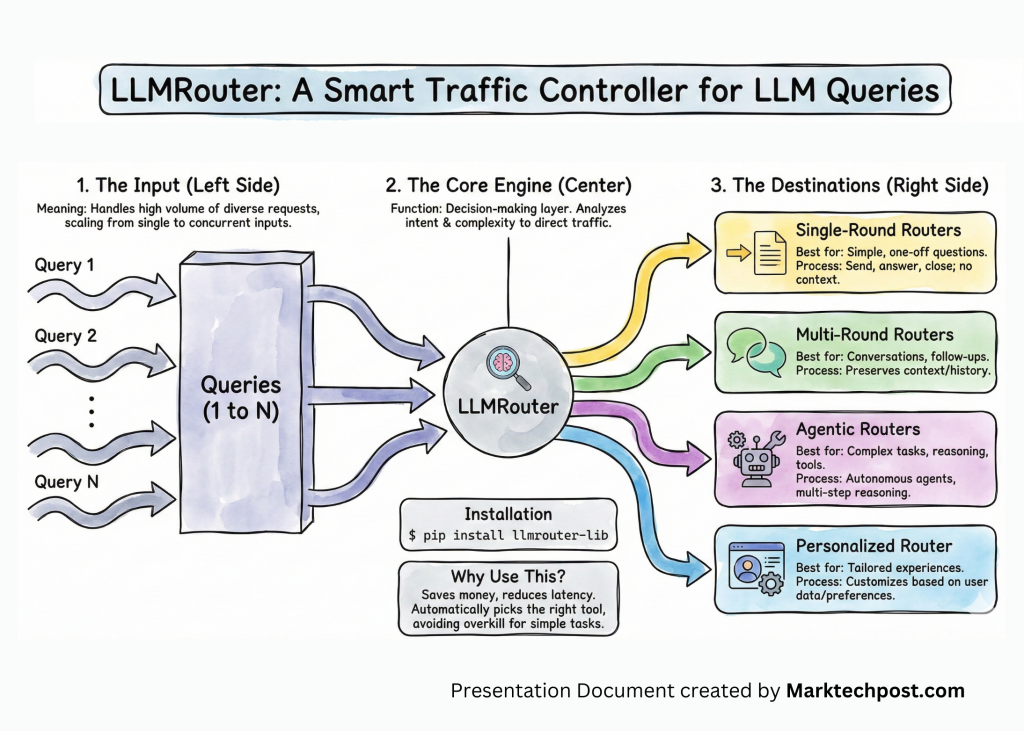
Meet LLMRouter: An Intelligent Routing System designed to Optimize LLM Inference by Dynamically Selecting the most Suitable Model for Each Query
Source: MarkTechPost LLMRouter is an open source routing library from the U Lab at the University of Illinois...

From Gemma 3 270M to FunctionGemma, How Google AI Built a Compact Function Calling Specialist for Edge Workloads
Source: MarkTechPost Google has released FunctionGemma, a specialized version of the Gemma 3 270M model that is trained...

A Coding Implementation on Building Self-Organizing Zettelkasten Knowledge Graphs and Sleep-Consolidation Mechanisms
Source: MarkTechPost In this tutorial, we dive into the cutting edge of Agentic AI by building a “Zettelkasten”...

MiniMax Releases M2.1: An Enhanced M2 Version with Features like Multi-Coding Language Support, API Integration, and Improved Tools for Structured Coding
Source: MarkTechPost Just months after releasing M2—a fast, low-cost model designed for agents and code—MiniMax has introduced an...

This AI Paper from Stanford and Harvard Explains Why Most ‘Agentic AI’ Systems Feel Impressive in Demos and then Completely Fall Apart in Real Use
Source: MarkTechPost Agentic AI systems sit on top of large language models and connect to tools, memory, and...

Google Health AI Releases MedASR: a Conformer Based Medical Speech to Text Model for Clinical Dictation
Source: MarkTechPost Google Health AI team has released MedASR, an open weights medical speech to text model that...
Google DeepMind Researchers Release Gemma Scope 2 as a Full Stack Interpretability Suite for Gemma 3 Models
Source: MarkTechPost Google DeepMind Researchers introduce Gemma Scope 2, an open suite of interpretability tools that exposes how...