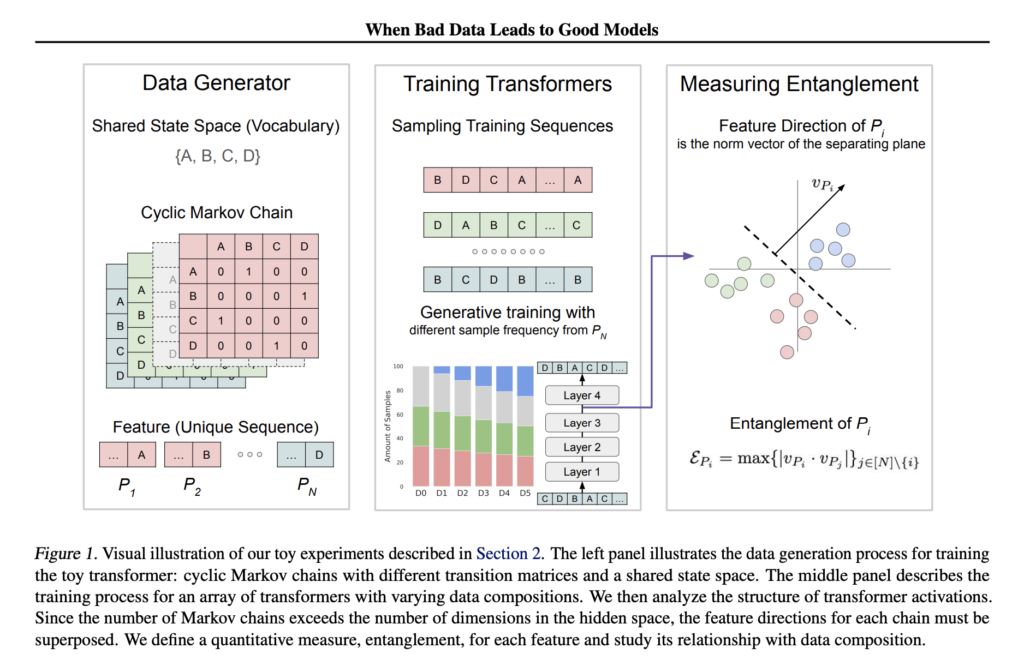
Rethinking Toxic Data in LLM Pretraining: A Co-Design Approach for Improved Steerability and Detoxification
Source: MarkTechPost In the pretraining of LLMs, the quality of training data is crucial in determining model performance....

Reinforcement Learning, Not Fine-Tuning: Nemotron-Tool-N1 Trains LLMs to Use Tools with Minimal Supervision and Maximum Generalization
Source: MarkTechPost Equipping LLMs with external tools or functions has become popular, showing great performance across diverse domains....
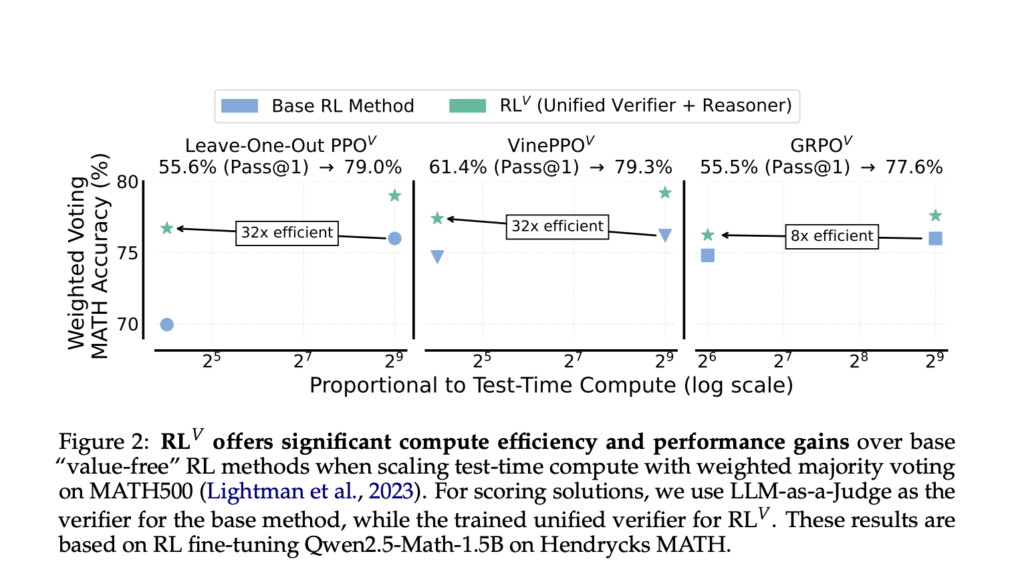
RL^V: Unifying Reasoning and Verification in Language Models through Value-Free Reinforcement Learning
Source: MarkTechPost LLMs have gained outstanding reasoning capabilities through reinforcement learning (RL) on correctness rewards. Modern RL algorithms...
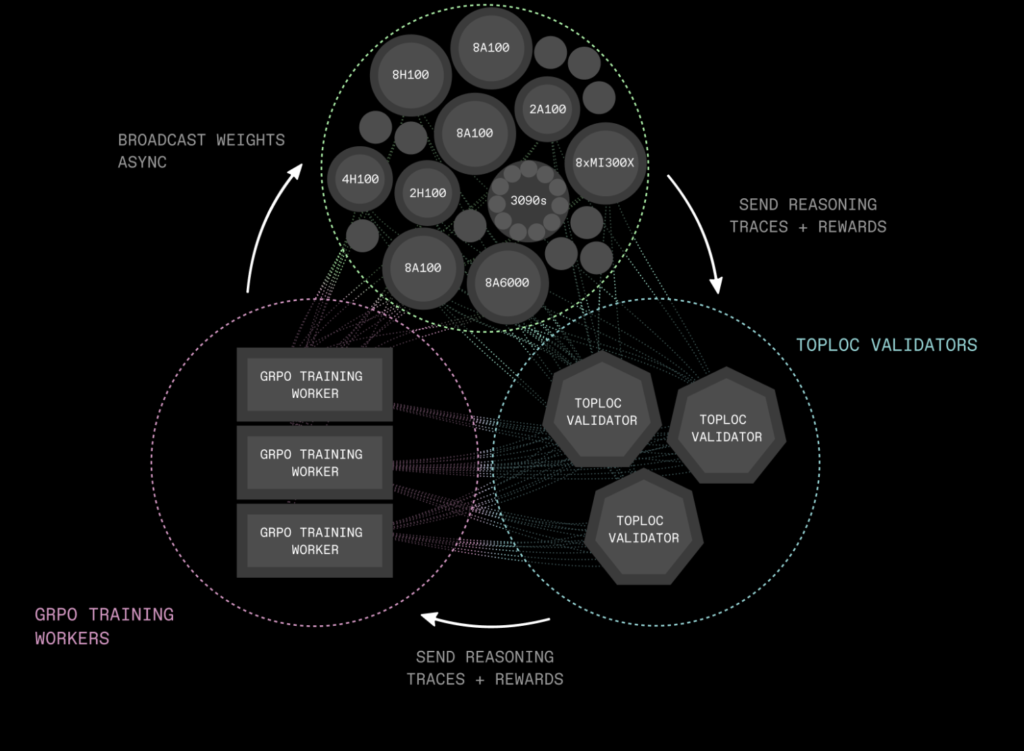
PrimeIntellect Releases INTELLECT-2: A 32B Reasoning Model Trained via Distributed Asynchronous Reinforcement Learning
Source: MarkTechPost As language models scale in parameter count and reasoning complexity, traditional centralized training pipelines face increasing...
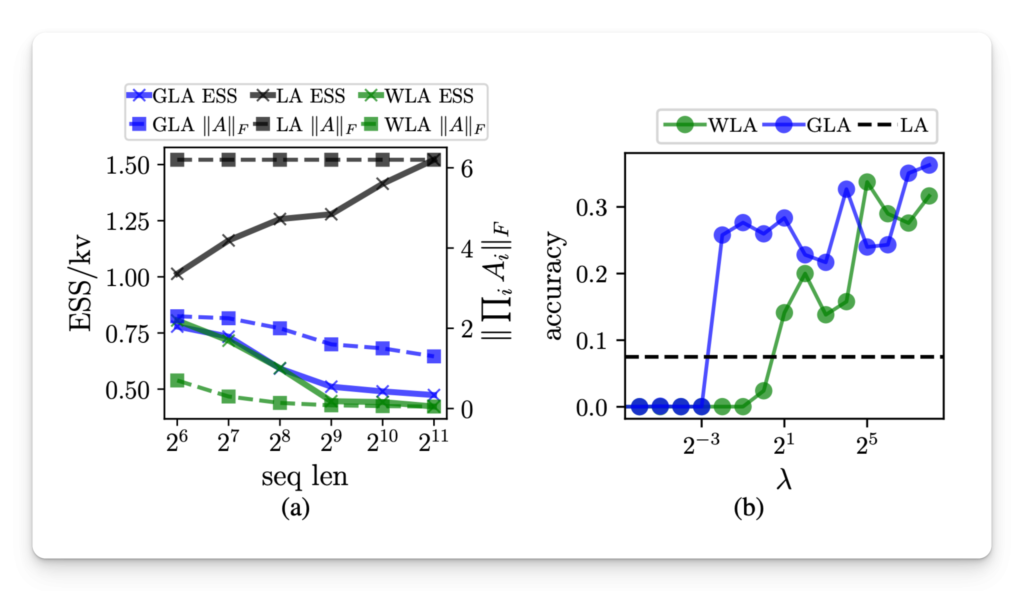
This AI Paper Introduces Effective State-Size (ESS): A Metric to Quantify Memory Utilization in Sequence Models for Performance Optimization
Source: MarkTechPost In machine learning, sequence models are designed to process data with temporal structure, such as language,...
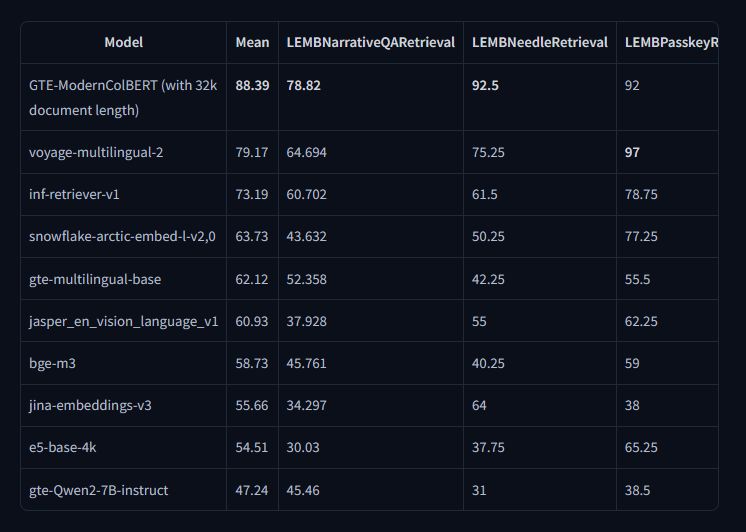
LightOn AI Released GTE-ModernColBERT-v1: A Scalable Token-Level Semantic Search Model for Long-Document Retrieval and Benchmark-Leading Performance
Source: MarkTechPost Semantic retrieval focuses on understanding the meaning behind text rather than matching keywords, allowing systems to...

ZeroSearch from Alibaba Uses Reinforcement Learning and Simulated Documents to Teach LLMs Retrieval Without Real-Time Search
Source: MarkTechPost Large language models are now central to various applications, from coding to academic tutoring and automated...

Microsoft Researchers Introduce ARTIST: A Reinforcement Learning Framework That Equips LLMs with Agentic Reasoning and Dynamic Tool Use
Source: MarkTechPost LLMs have made impressive gains in complex reasoning, primarily through innovations in architecture, scale, and training...

AI That Teaches Itself: Tsinghua University’s ‘Absolute Zero’ Trains LLMs With Zero External Data
Source: MarkTechPost LLMs have shown advancements in reasoning capabilities through Reinforcement Learning with Verifiable Rewards (RLVR), which relies...

NVIDIA Open-Sources Open Code Reasoning Models (32B, 14B, 7B)
Source: MarkTechPost NVIDIA continues to push the boundaries of open AI development by open-sourcing its Open Code Reasoning...