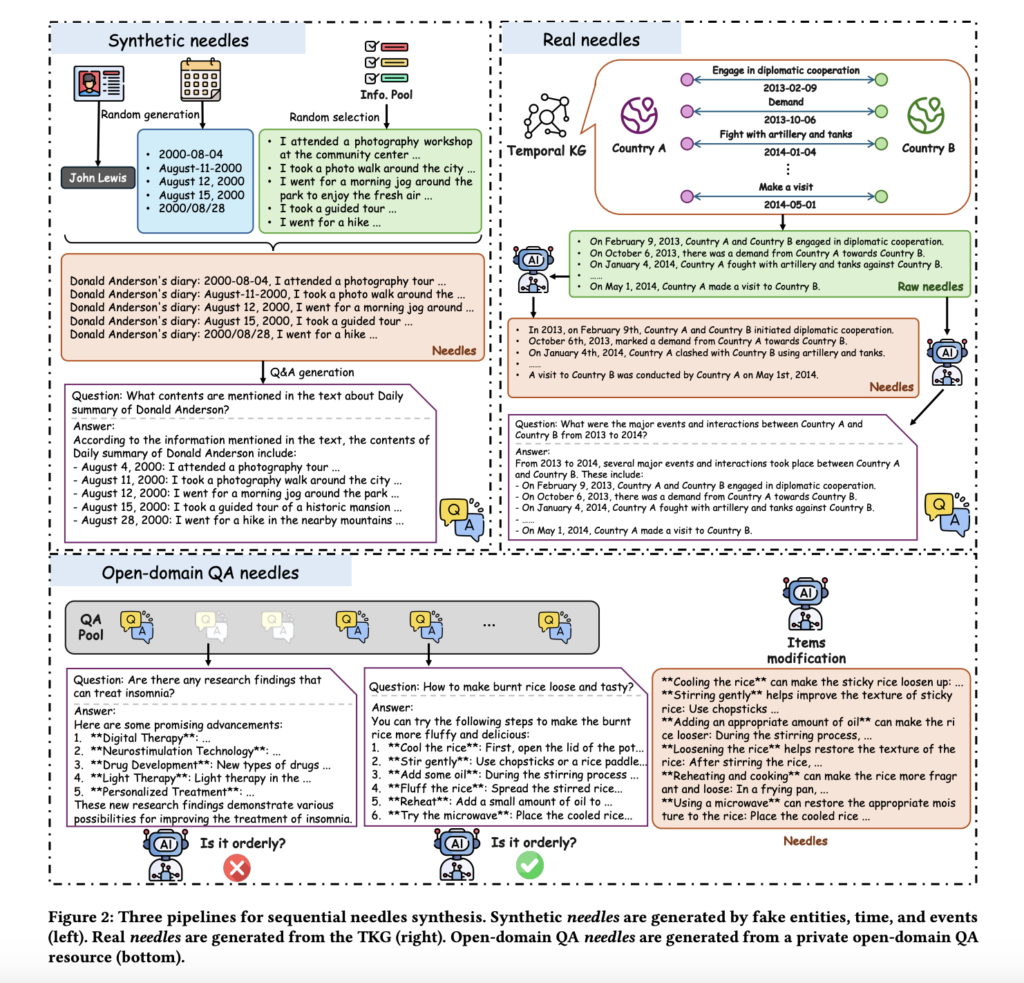
Sequential-NIAH: A Benchmark for Evaluating LLMs in Extracting Sequential Information from Long Texts
Source: MarkTechPost Evaluating how well LLMs handle long contexts is essential, especially for retrieving specific, relevant information embedded...

New model predicts a chemical reaction’s point of no return
Source: MIT News – Artificial intelligence When chemists design new chemical reactions, one useful piece of information involves...
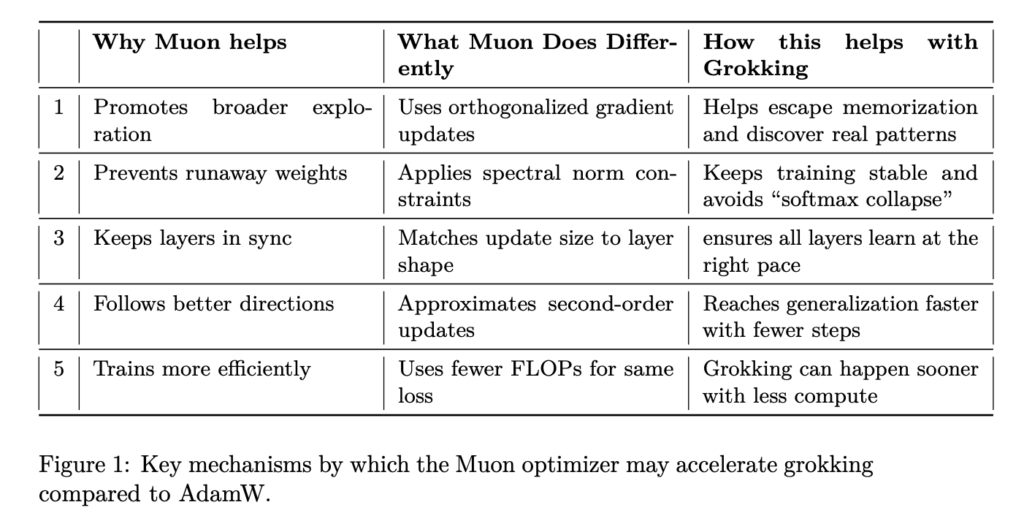
Muon Optimizer Significantly Accelerates Grokking in Transformers: Microsoft Researchers Explore Optimizer Influence on Delayed Generalization
Source: MarkTechPost Revisiting the Grokking Challenge In recent years, the phenomenon of grokking—where deep learning models exhibit a...
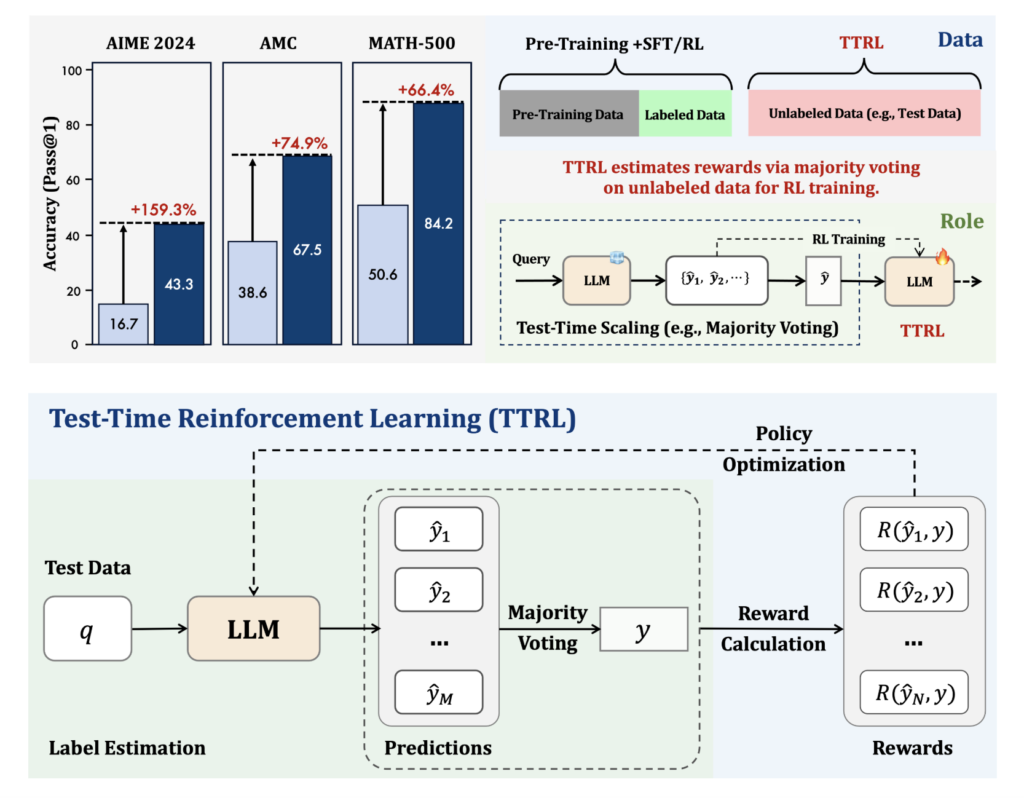
LLMs Can Now Learn without Labels: Researchers from Tsinghua University and Shanghai AI Lab Introduce Test-Time Reinforcement Learning (TTRL) to Enable Self-Evolving Language Models Using Unlabeled Data
Source: MarkTechPost Despite significant advances in reasoning capabilities through reinforcement learning (RL), most large language models (LLMs) remain...
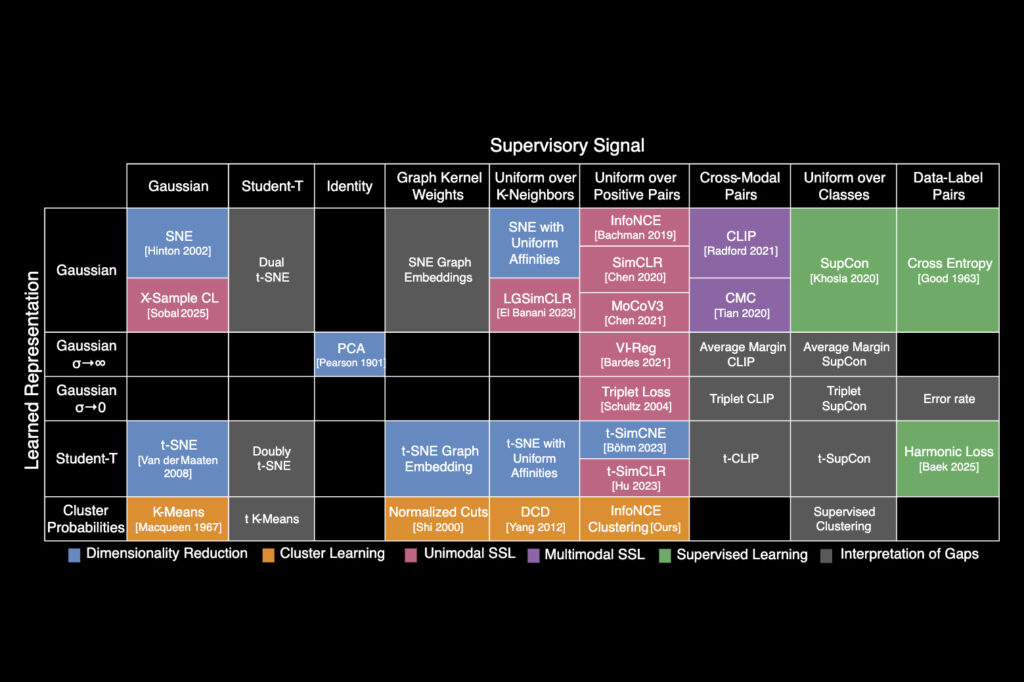
“Periodic table of machine learning” could fuel AI discovery
Source: MIT News – Artificial intelligence MIT researchers have created a periodic table that shows how more than...

LLMs Can Now Retain High Accuracy at 2-Bit Precision: Researchers from UNC Chapel Hill Introduce TACQ, a Task-Aware Quantization Approach that Preserves Critical Weight Circuits for Compression Without Performance Loss
Source: MarkTechPost LLMs show impressive capabilities across numerous applications, yet they face challenges due to computational demands and...

Long-Context Multimodal Understanding No Longer Requires Massive Models: NVIDIA AI Introduces Eagle 2.5, a Generalist Vision-Language Model that Matches GPT-4o on Video Tasks Using Just 8B Parameters
Source: MarkTechPost In recent years, vision-language models (VLMs) have advanced significantly in bridging image, video, and textual modalities....

OpenAI Releases a Practical Guide to Identifying and Scaling AI Use Cases in Enterprise Workflows
Source: MarkTechPost As the deployment of artificial intelligence accelerates across industries, a recurring challenge for enterprises is determining...
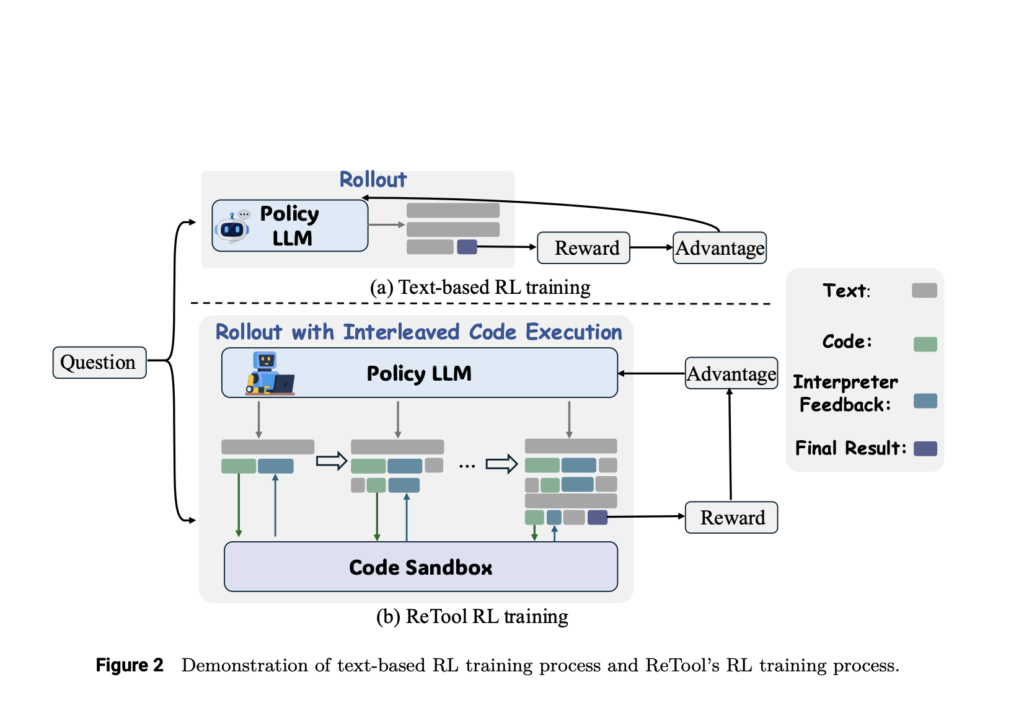
ReTool: A Tool-Augmented Reinforcement Learning Framework for Optimizing LLM Reasoning with Computational Tools
Source: MarkTechPost Reinforcement learning (RL) is a powerful technique for enhancing the reasoning capabilities of LLMs, enabling them...
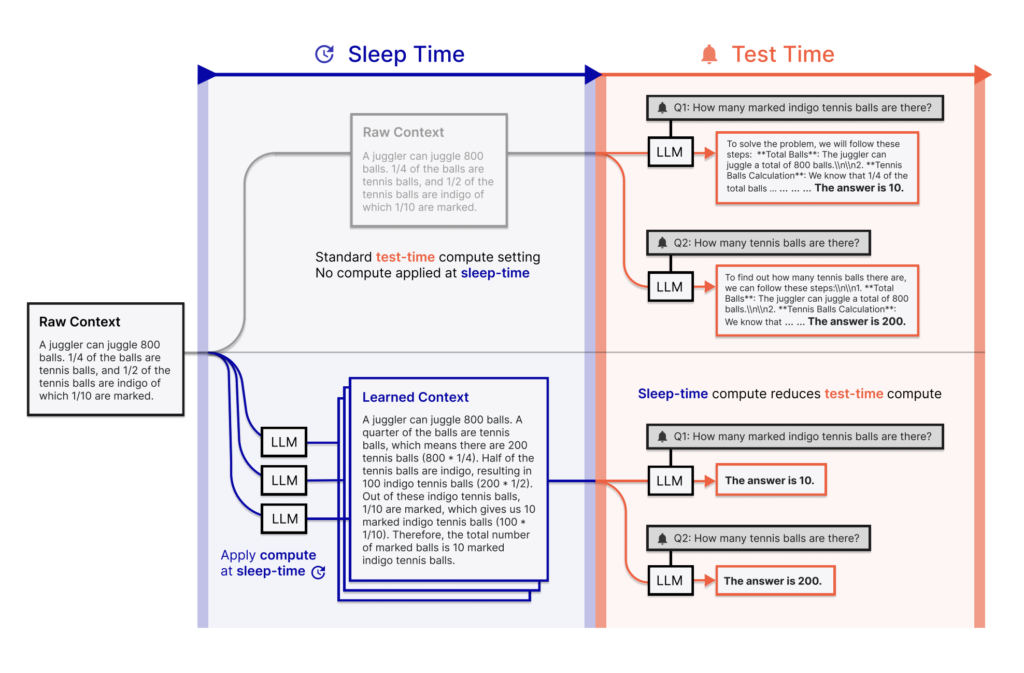
LLMs Can Think While Idle: Researchers from Letta and UC Berkeley Introduce ‘Sleep-Time Compute’ to Slash Inference Costs and Boost Accuracy Without Sacrificing Latency
Source: MarkTechPost Large language models (LLMs) have gained prominence for their ability to handle complex reasoning tasks, transforming...