
Could LLMs help design our next medicines and materials?
Source: MIT News – Artificial intelligence The process of discovering molecules that have the properties needed to create...

This AI Paper from ByteDance Introduces MegaScale-Infer: A Disaggregated Expert Parallelism System for Efficient and Scalable MoE-Based LLM Serving
Source: MarkTechPost Large language models are built on transformer architectures and power applications like chat, code generation, and...

A Code Implementation to Use Ollama through Google Colab and Building a Local RAG Pipeline on Using DeepSeek-R1 1.5B through Ollama, LangChain, FAISS, and ChromaDB for Q&A
Source: MarkTechPost In this tutorial, we’ll build a fully functional Retrieval-Augmented Generation (RAG) pipeline using open-source tools that...
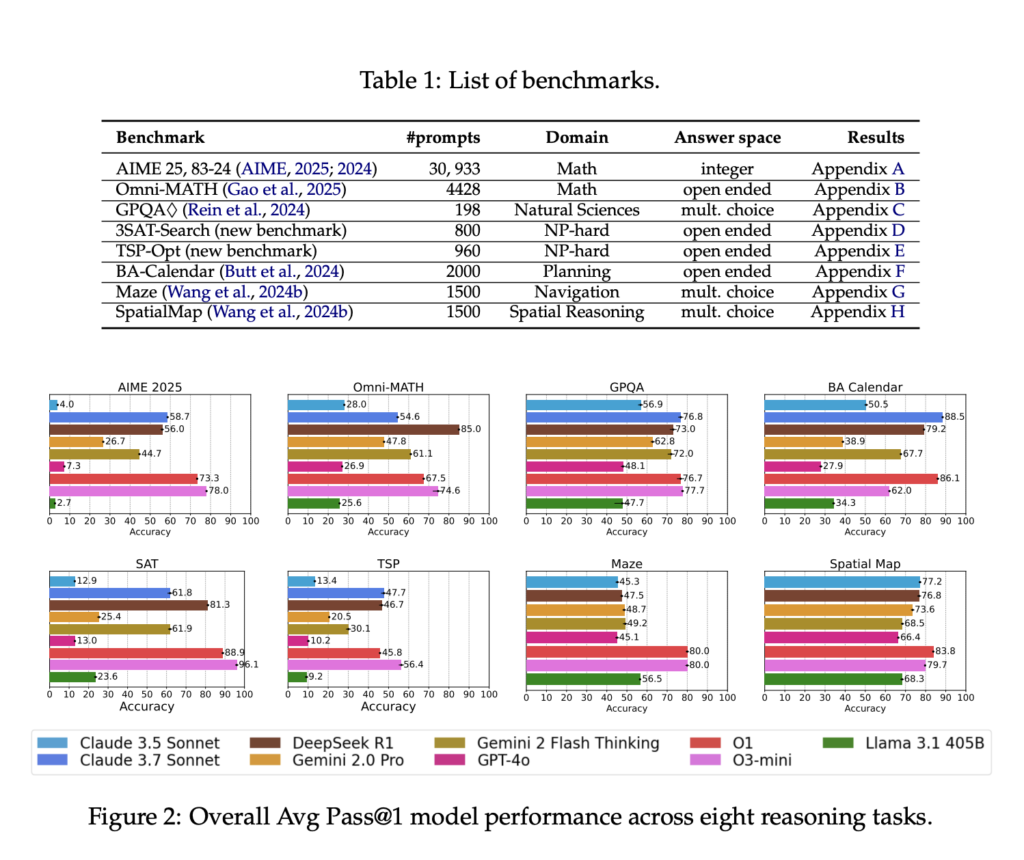
This AI Paper Introduces Inference-Time Scaling Techniques: Microsoft’s Deep Evaluation of Reasoning Models on Complex Tasks
Source: MarkTechPost Large language models are often praised for their linguistic fluency, but a growing area of focus...
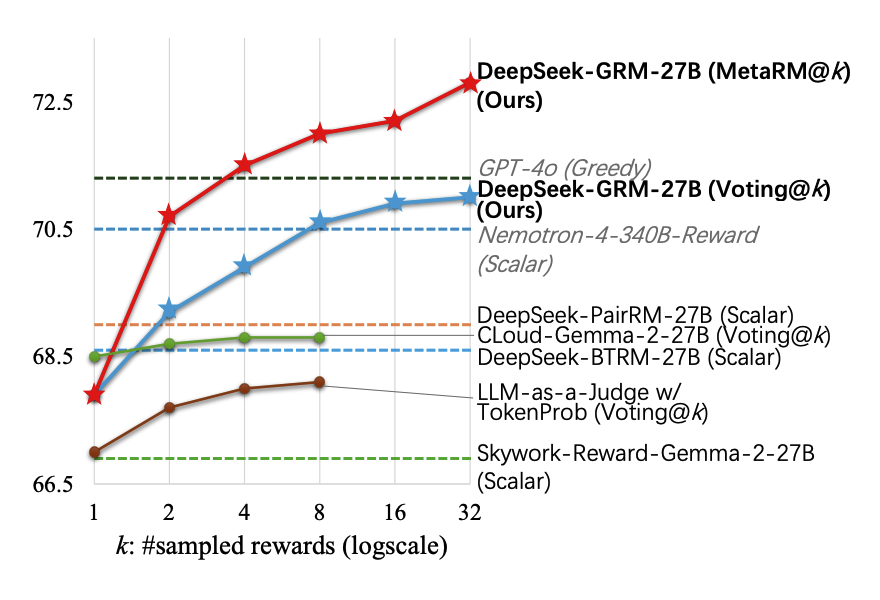
Scalable and Principled Reward Modeling for LLMs: Enhancing Generalist Reward Models RMs with SPCT and Inference-Time Optimization
Source: MarkTechPost Reinforcement Learning RL has become a widely used post-training method for LLMs, enhancing capabilities like human...

Transformer Meets Diffusion: How the Transfusion Architecture Empowers GPT-4o’s Creativity
Source: MarkTechPost OpenAI’s GPT-4o represents a new milestone in multimodal AI: a single model capable of generating fluent...

This AI Paper from Anthropic Introduces Attribution Graphs: A New Interpretability Method to Trace Internal Reasoning in Claude 3.5 Haiku
Source: MarkTechPost While the outputs of large language models (LLMs) appear coherent and useful, the underlying mechanisms guiding...

Anthropic’s Evaluation of Chain-of-Thought Faithfulness: Investigating Hidden Reasoning, Reward Hacks, and the Limitations of Verbal AI Transparency in Reasoning Models
Source: MarkTechPost A key advancement in AI capabilities is the development and use of chain-of-thought (CoT) reasoning, where...
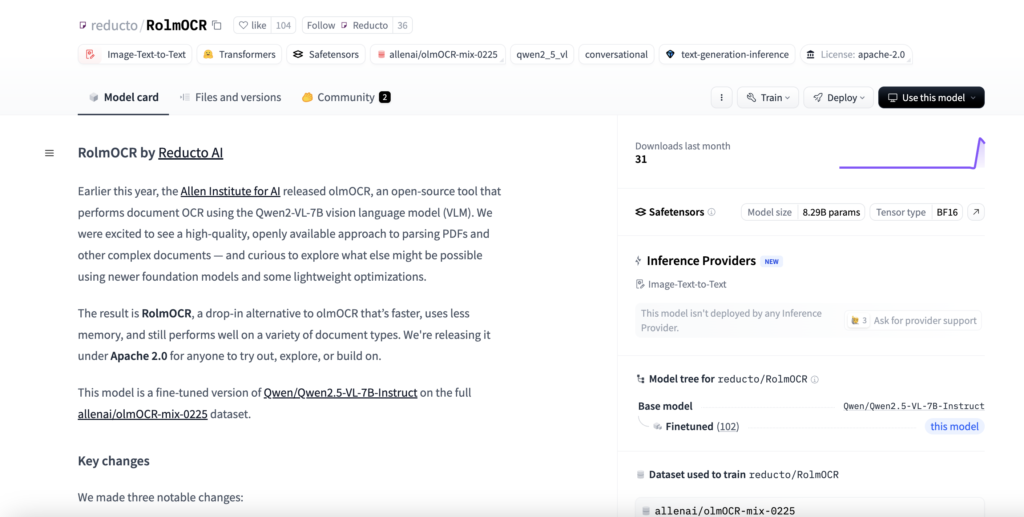
Reducto AI Released RolmOCR: A SoTA OCR Model Built on Qwen 2.5 VL, Fully Open-Source and Apache 2.0 Licensed for Advanced Document Understanding
Source: MarkTechPost Optical Character Recognition (OCR) has long been a cornerstone of document digitization, enabling the transformation of...
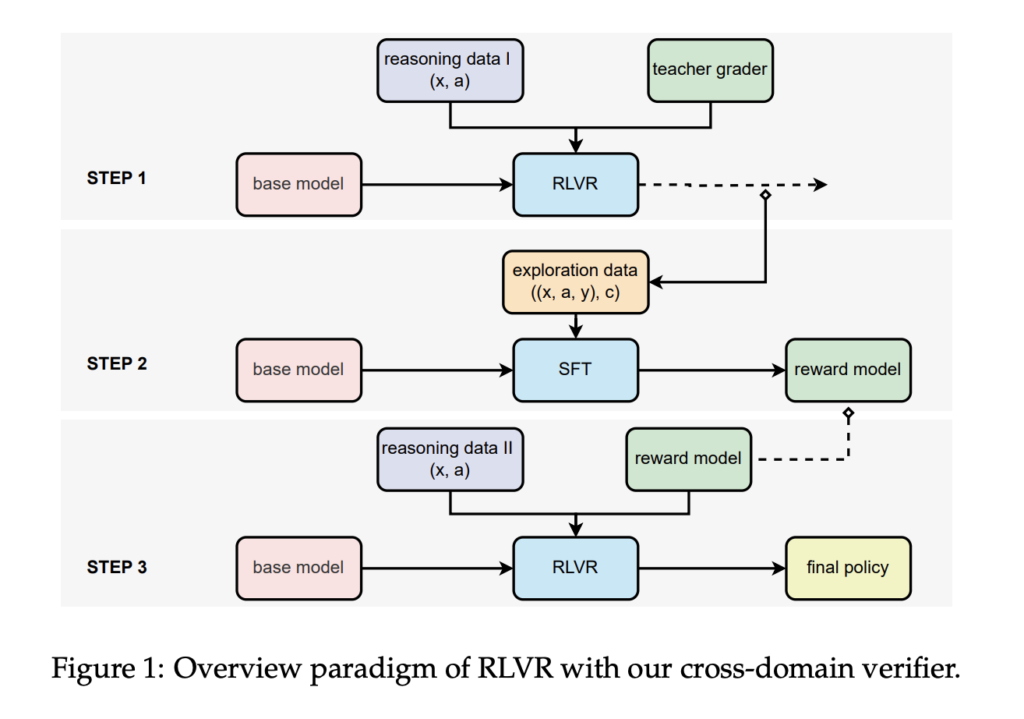
Scalable Reinforcement Learning with Verifiable Rewards: Generative Reward Modeling for Unstructured, Multi-Domain Tasks
Source: MarkTechPost Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective in enhancing LLMs’ reasoning and coding abilities,...