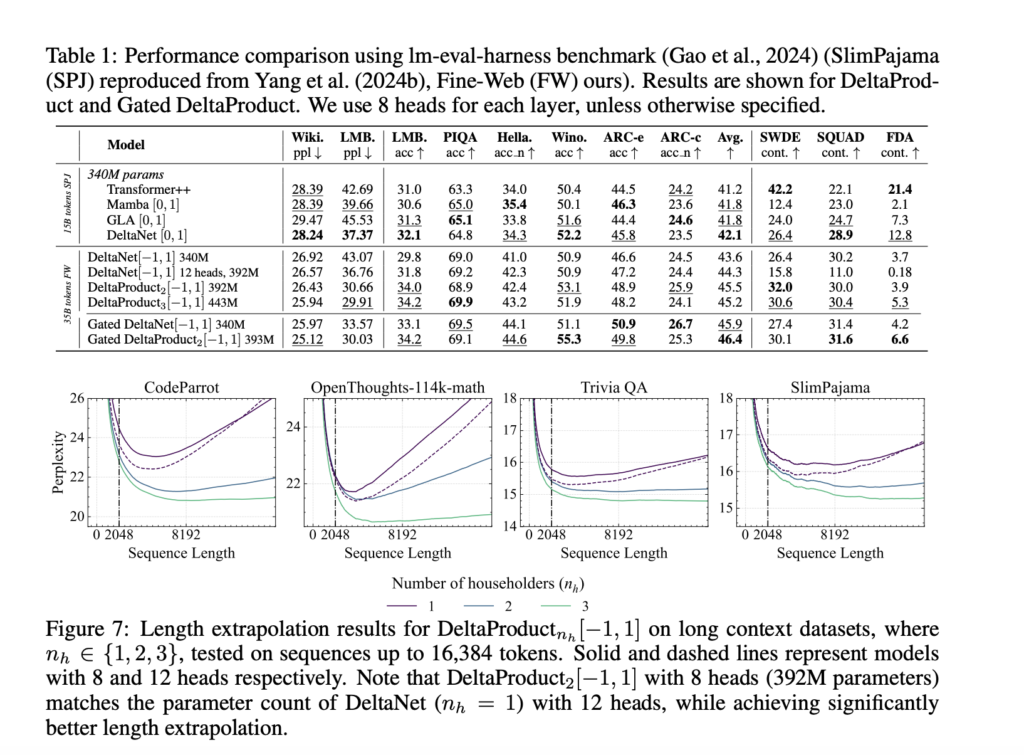
DeltaProduct: An AI Method that Balances Expressivity and Efficiency of the Recurrence Computation, Improving State-Tracking in Linear Recurrent Neural Networks
Source: MarkTechPost The Transformer architecture revolutionised natural language processing with its self-attention mechanism, enabling parallel computation and effective...

Researchers teach LLMs to solve complex planning challenges
Source: MIT News – Artificial intelligence Imagine a coffee company trying to optimize its supply chain. The company...

This AI Paper from ByteDance Introduces a Hybrid Reward System Combining Reasoning Task Verifiers (RTV) and a Generative Reward Model (GenRM) to Mitigate Reward Hacking
Source: MarkTechPost Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning LLMs with human values and preferences....

Meet ReSearch: A Novel AI Framework that Trains LLMs to Reason with Search via Reinforcement Learning without Using Any Supervised Data on Reasoning Steps
Source: MarkTechPost Large language models (LLMs) have demonstrated significant progress across various tasks, particularly in reasoning capabilities. However,...

How to Build a Prototype X-ray Judgment Tool (Open Source Medical Inference System) Using TorchXRayVision, Gradio, and PyTorch
Source: MarkTechPost In this tutorial, we demonstrate how to build a prototype X-ray judgment tool using open-source libraries...
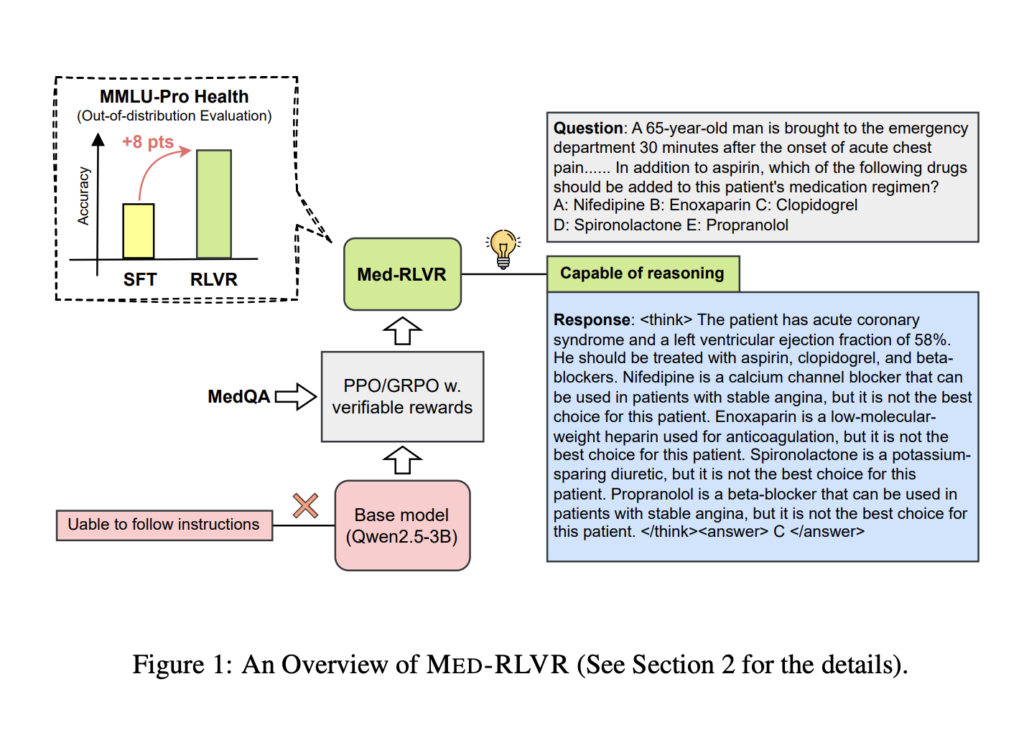
Advancing Medical Reasoning with Reinforcement Learning from Verifiable Rewards (RLVR): Insights from MED-RLVR
Source: MarkTechPost Reinforcement Learning from Verifiable Rewards (RLVR) has recently emerged as a promising method for enhancing reasoning...
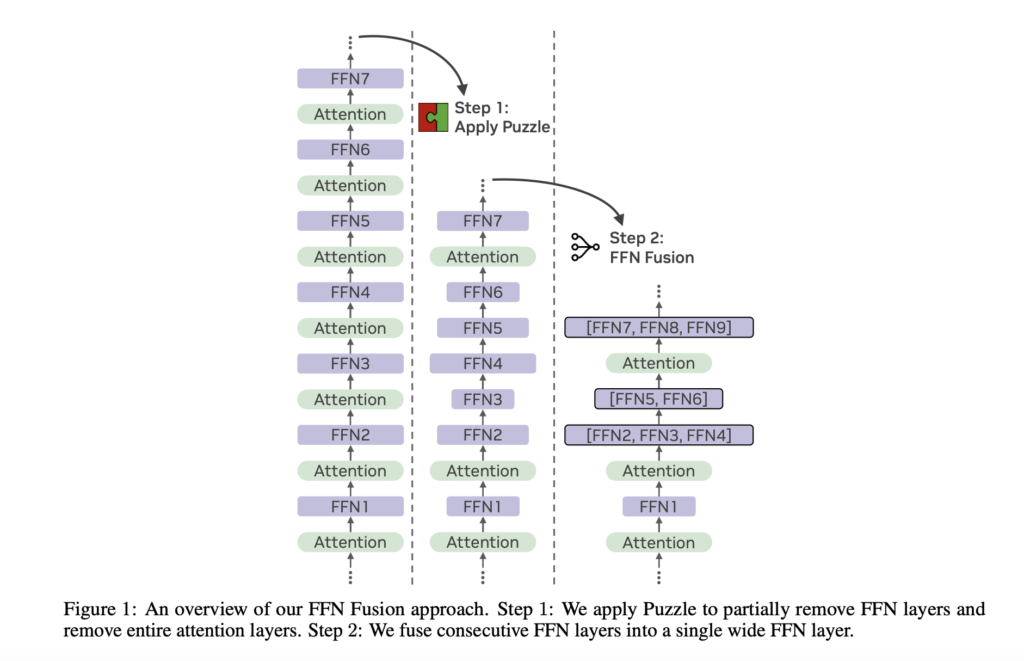
NVIDIA AI Researchers Introduce FFN Fusion: A Novel Optimization Technique that Demonstrates How Sequential Computation in Large Language Models LLMs can be Effectively Parallelized
Source: MarkTechPost Large language models (LLMs) have become vital across domains, enabling high-performance applications such as natural language...
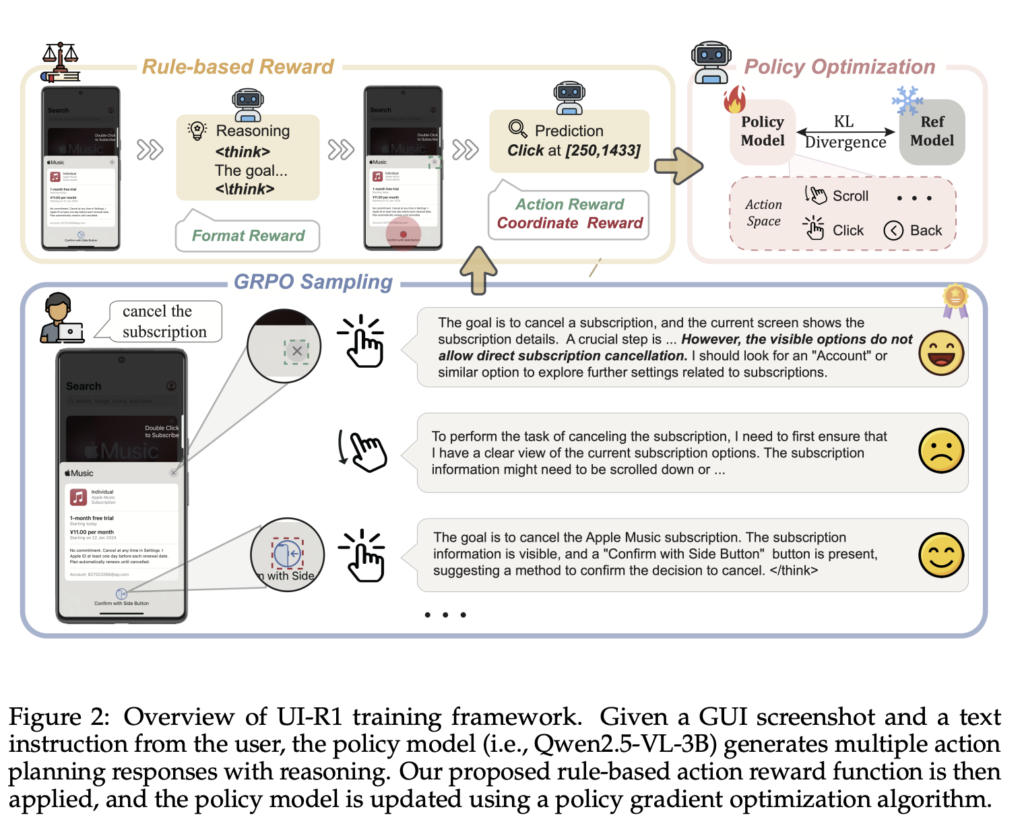
This AI Paper Propose the UI-R1 Framework that Extends Rule-based Reinforcement Learning to GUI Action Prediction Tasks
Source: MarkTechPost Supervised fine-tuning (SFT) is the standard training paradigm for large language models (LLMs) and graphic user...
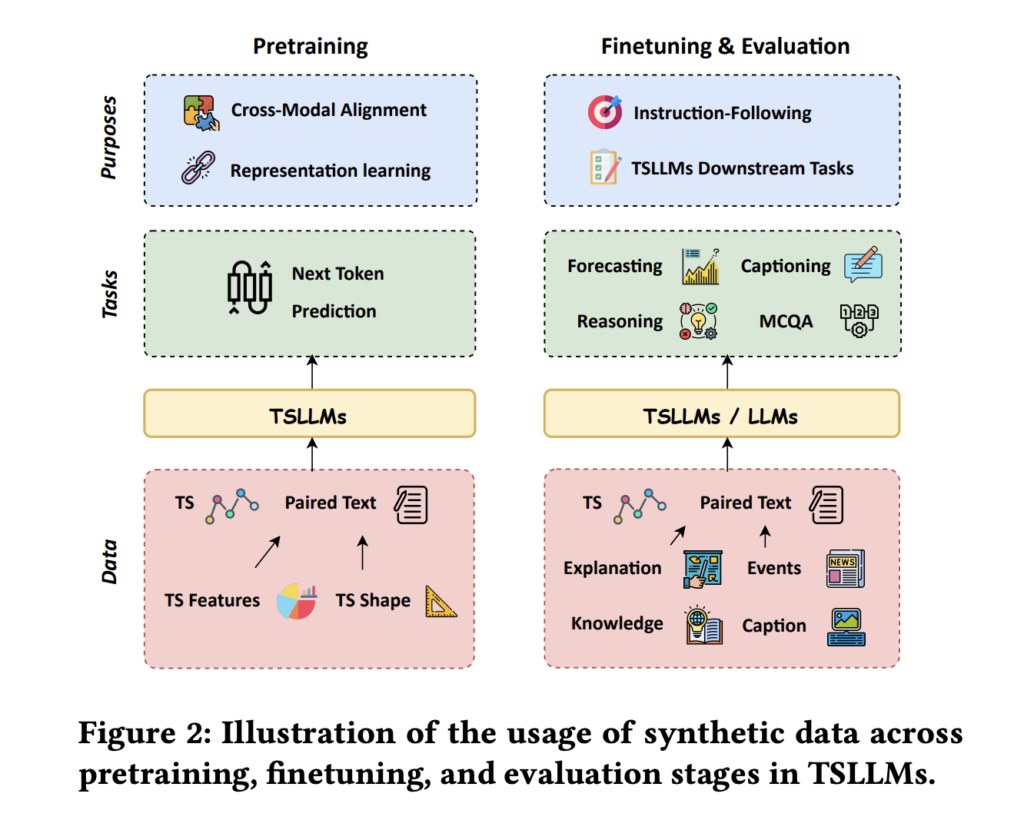
Empowering Time Series AI: How Salesforce is Leveraging Synthetic Data to Enhance Foundation Models
Source: MarkTechPost Time series analysis faces significant hurdles in data availability, quality, and diversity, critical factors in developing...
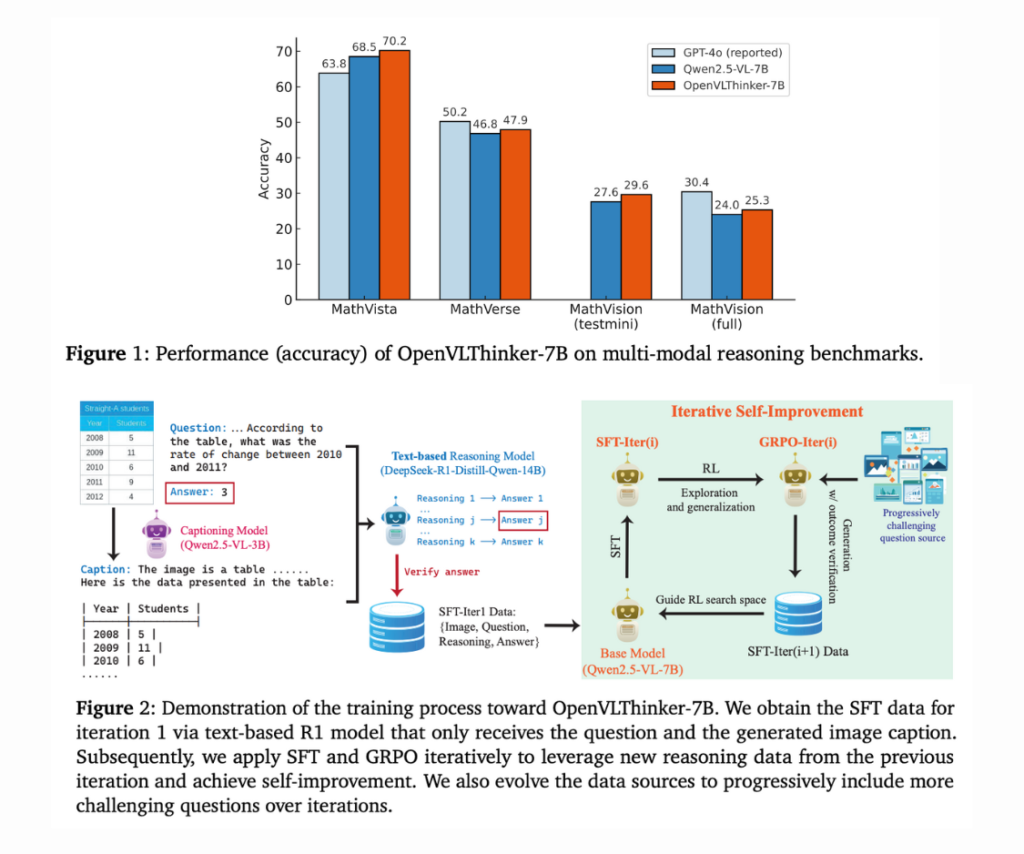
UCLA Researchers Released OpenVLThinker-7B: A Reinforcement Learning Driven Model for Enhancing Complex Visual Reasoning and Step-by-Step Problem Solving in Multimodal Systems
Source: MarkTechPost Large vision-language models (LVLMs) integrate large language models with image processing capabilities, enabling them to interpret...