
Researchers from the University of Cambridge and Monash University Introduce ReasonGraph: A Web-based Platform to Visualize and Analyze LLM Reasoning Processes
Source: MarkTechPost Reasoning capabilities have become essential for LLMs, but analyzing these complex processes poses a significant challenge....

Meet Attentive Reasoning Queries (ARQs): A Structured Approach to Enhancing Large Language Model Instruction Adherence, Decision-Making Accuracy, and Hallucination Prevention in AI-Driven Conversational Systems
Source: MarkTechPost Large Language Models (LLMs) have become crucial in customer support, automated content creation, and data retrieval....
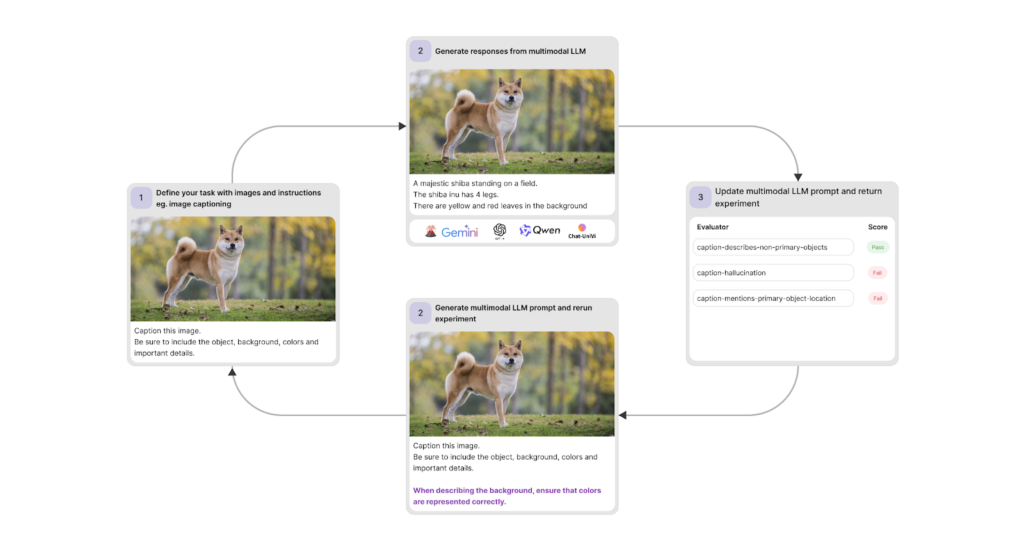
Patronus AI Introduces the Industry’s First Multimodal LLM-as-a-Judge (MLLM-as-a-Judge): Designed to Evaluate and Optimize AI Systems that Convert Image Inputs into Text Outputs
Source: MarkTechPost In recent years, the integration of image generation technologies into various platforms has opened new avenues...

Allen Institute for AI (AI2) Releases OLMo 32B: A Fully Open Model to Beat GPT 3.5 and GPT-4o mini on a Suite of Multi-Skill Benchmarks
Source: MarkTechPost The rapid evolution of artificial intelligence (AI) has ushered in a new era of large language...

This AI Paper Introduces BD3-LMs: A Hybrid Approach Combining Autoregressive and Diffusion Models for Scalable and Efficient Text Generation
Source: MarkTechPost Traditional language models rely on autoregressive approaches, which generate text sequentially, ensuring high-quality outputs at the...
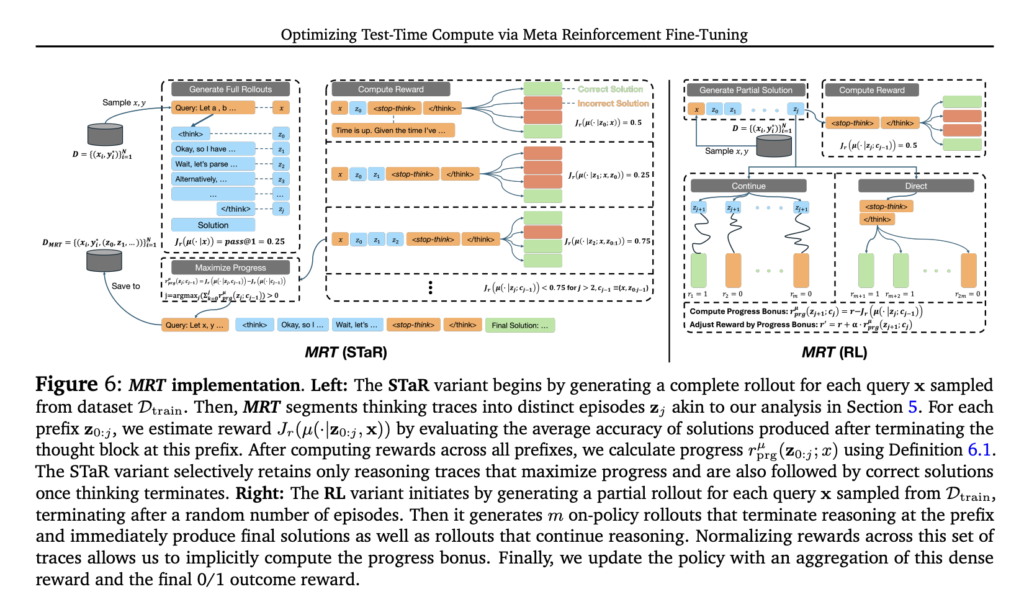
Optimizing Test-Time Compute for LLMs: A Meta-Reinforcement Learning Approach with Cumulative Regret Minimization
Source: MarkTechPost Enhancing the reasoning abilities of LLMs by optimizing test-time compute is a critical research challenge. Current...
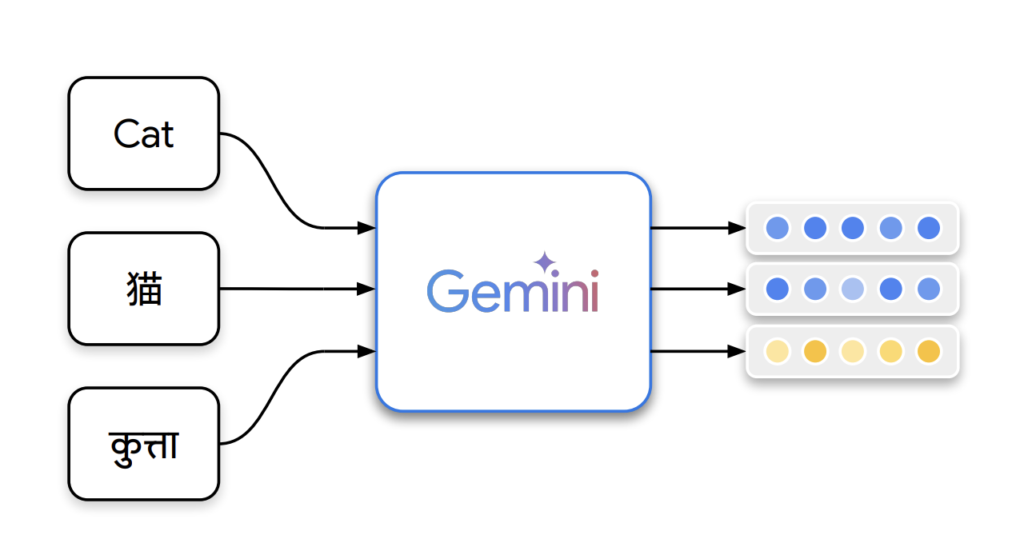
Google AI Introduces Gemini Embedding: A Novel Embedding Model Initialized from the Powerful Gemini Large Language Model
Source: MarkTechPost Recent advancements in embedding models have focused on transforming general-purpose text representations for diverse applications like...

Alibaba Researchers Introduce R1-Omni: An Application of Reinforcement Learning with Verifiable Reward (RLVR) to an Omni-Multimodal Large Language Model
Source: MarkTechPost Emotion recognition from video involves many nuanced challenges. Models that depend exclusively on either visual or...

Making airfield assessments automatic, remote, and safe
Source: MIT News – Artificial intelligence In 2022, Randall Pietersen, a civil engineer in the U.S. Air Force,...
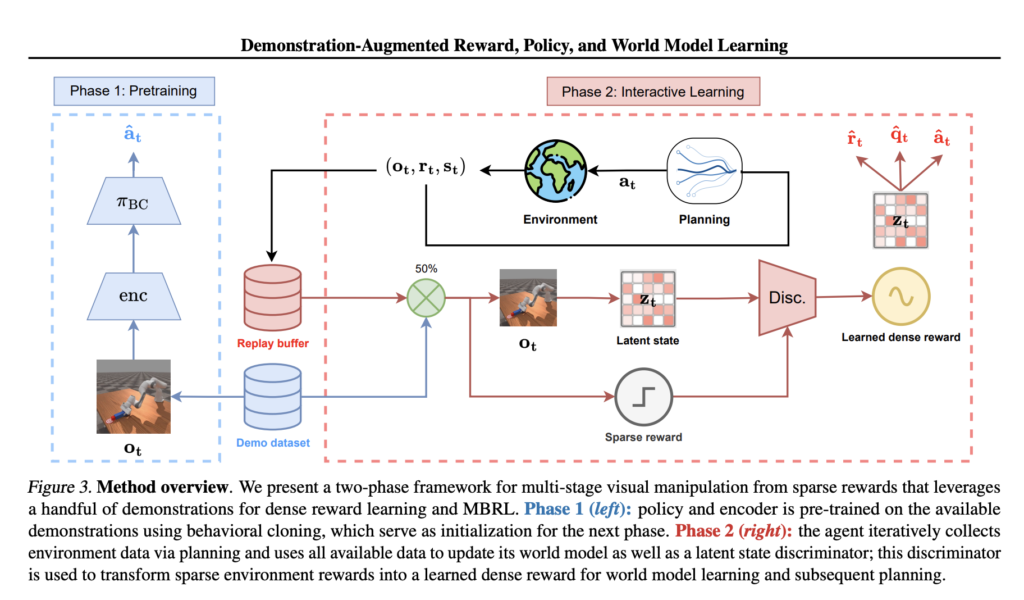
From Sparse Rewards to Precise Mastery: How DEMO3 is Revolutionizing Robotic Manipulation
Source: MarkTechPost Long-horizon robotic manipulation tasks are a serious challenge for reinforcement learning, caused mainly by sparse rewards,...