
Revolutionizing Code Generation: µCODE’s Single-Step Approach to Multi-Turn Feedback
Source: MarkTechPost Generating code with execution feedback is difficult because errors often require multiple corrections, and fixing them...

Visual Studio Code Setup Guide
Source: MarkTechPost Visual Studio Code (VSCode) is a lightweight but powerful source code editor that runs on your...

Understanding Generalization in Deep Learning: Beyond the Mysteries
Source: MarkTechPost Deep neural networks’ seemingly anomalous generalization behaviors, benign overfitting, double descent, and successful overparametrization are neither...
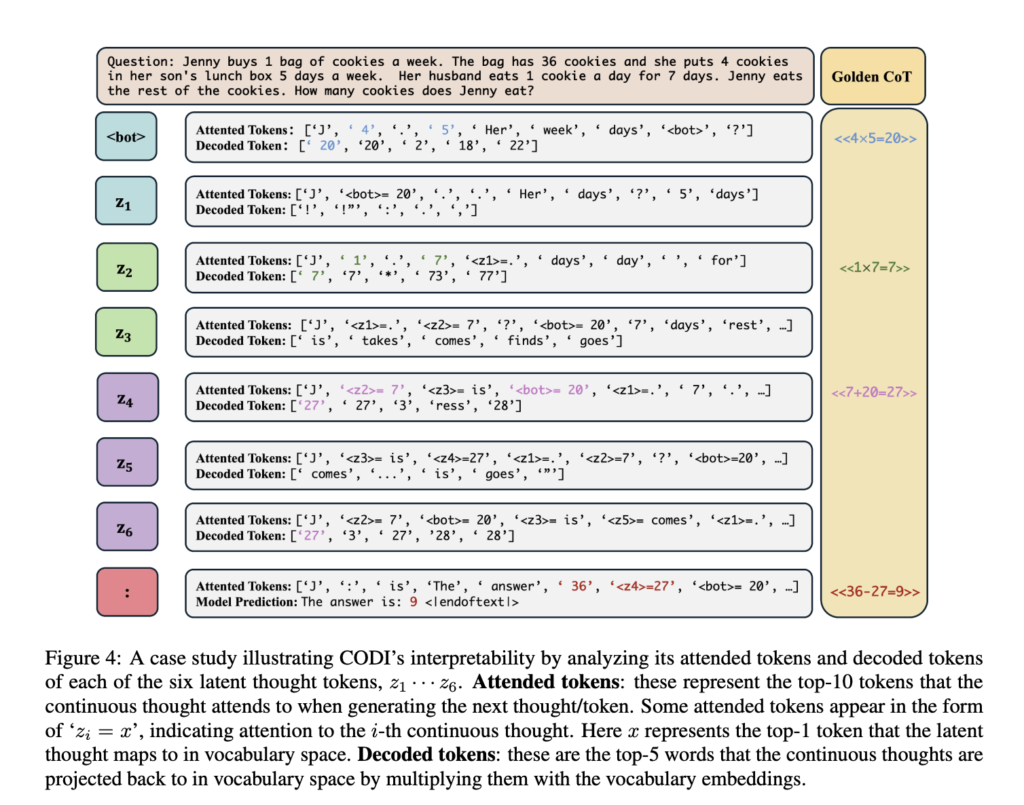
This AI Paper Introduces CODI: A Self-Distillation Framework for Efficient and Scalable Chain-of-Thought Reasoning in LLMs
Source: MarkTechPost Chain-of-Thought (CoT) prompting enables large language models (LLMs) to perform step-by-step logical deductions in natural language....

Google AI Introduces Differentiable Logic Cellular Automata (DiffLogic CA): A Differentiable Logic Approach to Neural Cellular Automata
Source: MarkTechPost Researchers and enthusiasts have been fascinated by the challenge of reverse-engineering complex behaviors that emerge from...
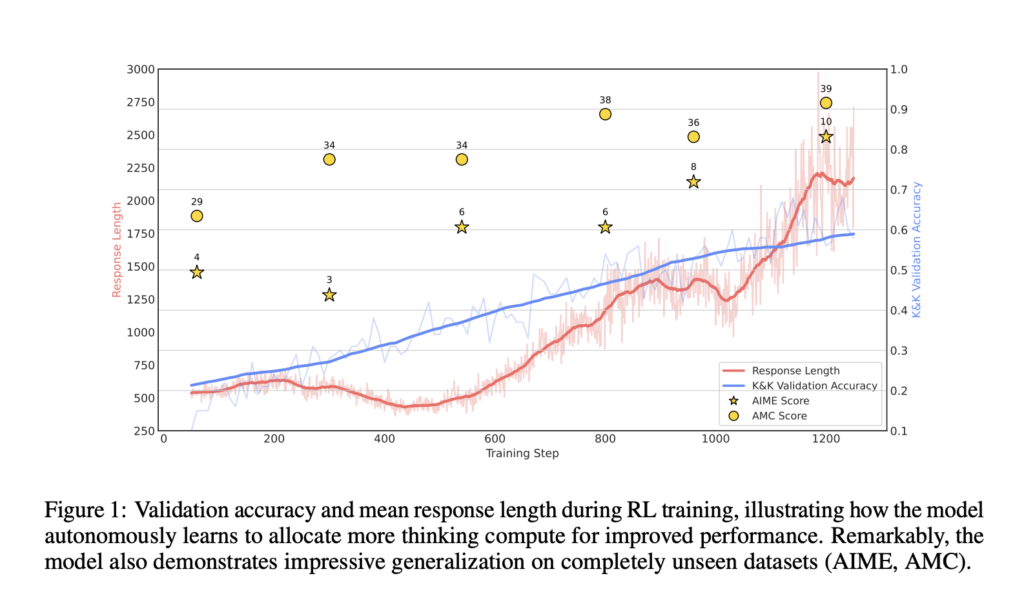
Microsoft and Ubiquant Researchers Introduce Logic-RL: A Rule-based Reinforcement Learning Framework that Acquires R1-like Reasoning Patterns through Training on Logic Puzzles
Source: MarkTechPost Large language models (LLMs) have made significant strides in their post-training phase, like DeepSeek-R1, Kimi-K1.5, and...
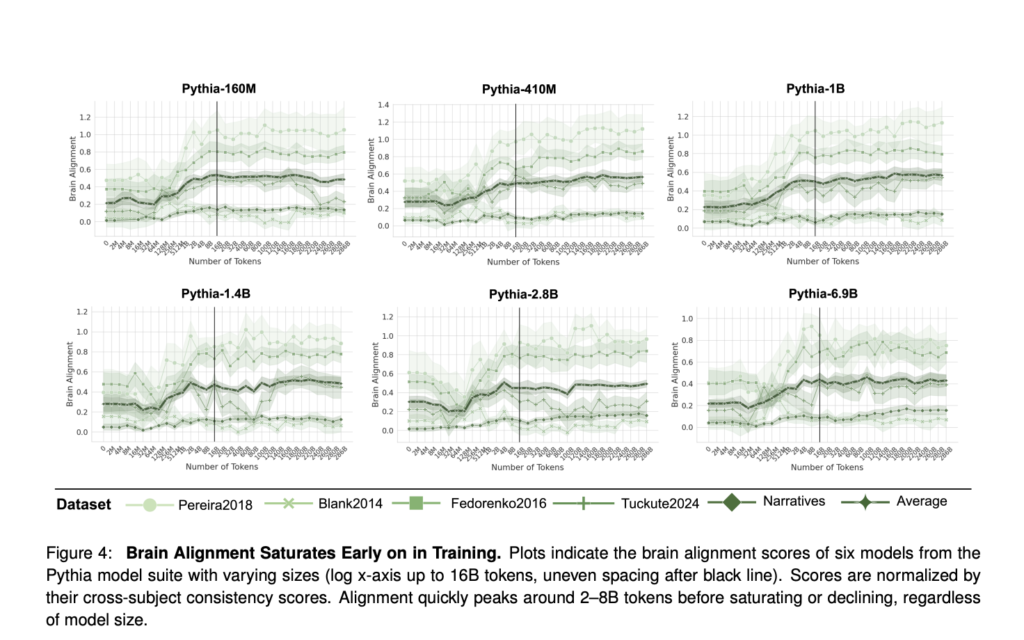
Evaluating Brain Alignment in Large Language Models: Insights into Linguistic Competence and Neural Representations
Source: MarkTechPost LLMs exhibit striking parallels to neural activity within the human language network, yet the specific linguistic...

Inception Unveils Mercury: The First Commercial-Scale Diffusion Large Language Model
Source: MarkTechPost The landscape of generative AI and LLMs has experienced a remarkable leap forward with the launch...
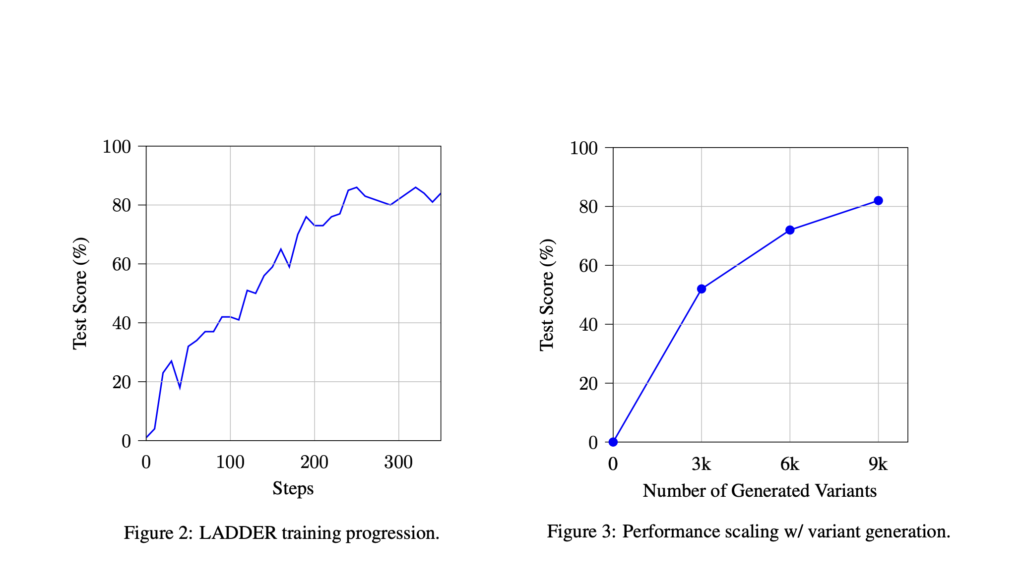
Tufa Labs Introduced LADDER: A Recursive Learning Framework Enabling Large Language Models to Self-Improve without Human Intervention
Source: MarkTechPost Large Language Models (LLMs) benefit significantly from reinforcement learning techniques, which enable iterative improvements by learning...
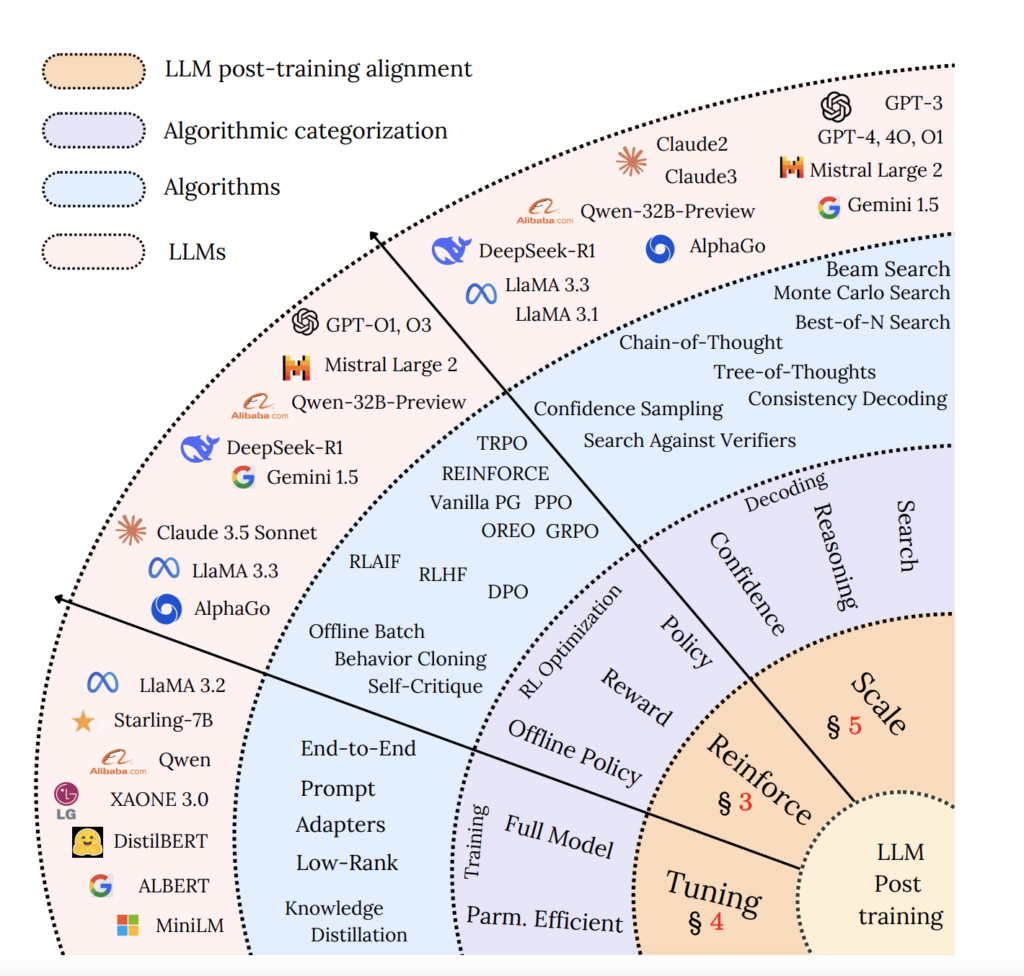
This AI Paper Introduces a Parameter-Efficient Fine-Tuning Framework: LoRA, QLoRA, and Test-Time Scaling for Optimized LLM Performance
Source: MarkTechPost Large Language Models (LLMs) are essential in fields that require contextual understanding and decision-making. However, their...