A Coding Guide Implementing SHAP Explainability Workflows with Explainer Comparisons, Maskers, Interactions, Drift, and Black-Box Models
Source: MarkTechPost In this tutorial, we implement SHAP workflows as a practical framework for interpreting machine learning models...
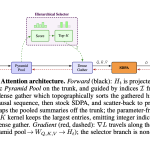
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Source: MarkTechPost Training large language models on long sequences has a well-known problem: attention is expensive. The scaled...

Meet LiteLLM Agent Platform: A Kubernetes-Based, Self-Hosted Infrastructure Layer for Isolated Agent Sandboxes and Persistent Session Management in Production
Source: MarkTechPost Running AI agents in a local script is straightforward. Running them reliably in production across teams,...
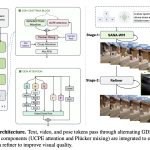
NVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPU
Source: MarkTechPost World models (systems that synthesize realistic video sequences from an initial image and a set of...
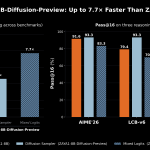
Zyphra Releases ZAYA1-8B-Diffusion-Preview: The First MoE Diffusion Model Converted From an Autoregressive LLM With Up to 7.7x Speedup
Source: MarkTechPost Zyphra, the San Francisco-based AI lab behind the ZAYA1 model family, released ZAYA1-8B-Diffusion-Preview — a preview...

Nous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter Models
Source: MarkTechPost Pre-training large language models is expensive enough that even modest efficiency improvements can translate into meaningful...

Mira Murati’s Thinking Machines Lab Introduces Interaction Models: A Native Multimodal Architecture for Real-Time Human-AI Collaboration
Source: MarkTechPost Most AI systems today work in turns. You type or speak, the model waits, processes your...
Universal AI is “a pathway to AI fluency that’s accessible and approachable to anyone, anywhere”
Source: MIT News – Artificial intelligence “Artificial intelligence is not just for computer scientists anymore; it’s going to...

Tilde Research Introduces Aurora: A Leverage-Aware Optimizer That Fixes a Hidden Neuron Death Problem in Muon
Source: MarkTechPost Researchers at Tilde Research have released Aurora, a new optimizer for training neural networks that addresses...
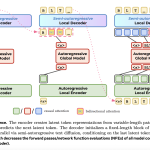
Meta and Stanford Researchers Propose Fast Byte Latent Transformer That Reduces Inference Memory Bandwidth by Over 50% Without Tokenization
Source: MarkTechPost A team of researchers from Meta, Stanford University, and the University of Washington have introduced three...