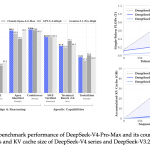
DeepSeek AI Releases DeepSeek-V4: Compressed Sparse Attention and Heavily Compressed Attention Enable One-Million-Token Contexts
Source: MarkTechPost DeepSeek-AI has released a preview version of the DeepSeek-V4 series: two Mixture-of-Experts (MoE) language models built...

MIT scientists build the world’s largest collection of Olympiad-level math problems, and open it to everyone
Source: MIT News – Artificial intelligence Every year, the countries competing in the International Mathematical Olympiad (IMO) arrive...
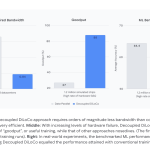
Google DeepMind Introduces Decoupled DiLoCo: An Asynchronous Training Architecture Achieving 88% Goodput Under High Hardware Failure Rates
Source: MarkTechPost Training frontier AI models is, at its core, a coordination problem. Thousands of chips must communicate...

Mend Releases AI Security Governance Framework: Covering Asset Inventory, Risk Tiering, AI Supply Chain Security, and Maturity Model
Source: MarkTechPost There’s a pattern playing out inside almost every engineering organization right now. A developer installs GitHub...
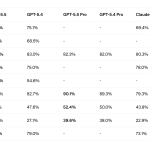
OpenAI Releases GPT-5.5, a Fully Retrained Agentic Model That Scores 82.7% on Terminal-Bench 2.0 and 84.9% on GDPval
Source: MarkTechPost OpenAI has released GPT-5.5, its most capable model to date and the first fully retrained base...

A Coding Tutorial on OpenMythos on Recurrent-Depth Transformers with Depth Extrapolation, Adaptive Computation, and Mixture-of-Experts Routing
Source: MarkTechPost In this tutorial, we explore the implementation of OpenMythos, a theoretical reconstruction of the Claude Mythos...

Google Cloud AI Research Introduces ReasoningBank: A Memory Framework that Distills Reasoning Strategies from Agent Successes and Failures
Source: MarkTechPost Most AI agents today have a fundamental amnesia problem. Deploy one to browse the web, resolve...
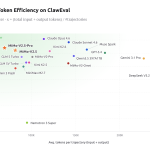
Xiaomi Releases MiMo-V2.5-Pro and MiMo-V2.5: Matching Frontier Model Benchmarks at Significantly Lower Token Cost
Source: MarkTechPost Xiaomi MiMo team publicly released two new models: MiMo-V2.5-Pro and MiMo-V2.5. The benchmarks, combined with some...

Alibaba Qwen Team Releases Qwen3.6-27B: A Dense Open-Weight Model Outperforming 397B MoE on Agentic Coding Benchmarks
Source: MarkTechPost Alibaba’s Qwen Team has released Qwen3.6-27B, the first dense open-weight model in the Qwen3.6 family —...

Teaching AI models to say “I’m not sure”
Source: MIT News – Artificial intelligence Confidence is persuasive. In artificial intelligence systems, it is often misleading. Today’s...