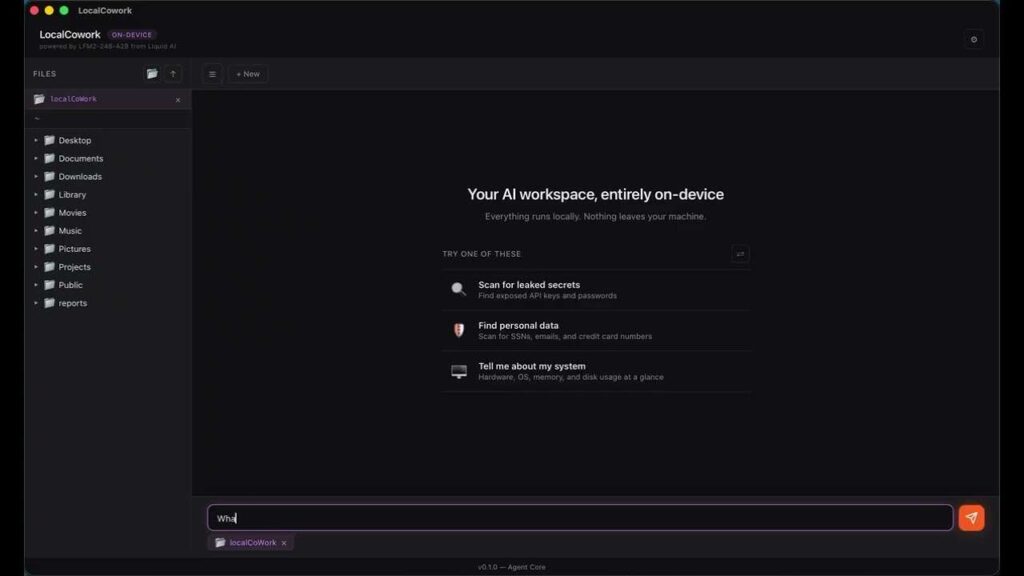
Liquid AI Releases LocalCowork Powered By LFM2-24B-A2B to Execute Privacy-First Agent Workflows Locally Via Model Context Protocol (MCP)
Source: MarkTechPost Liquid AI has released LFM2-24B-A2B, a model optimized for local, low-latency tool dispatch, alongside LocalCowork, an...

A Coding Guide to Build a Scalable End-to-End Machine Learning Data Pipeline Using Daft for High-Performance Structured and Image Data Processing
Source: MarkTechPost In this tutorial, we explore how we use Daft as a high-performance, Python-native data engine to...

Google AI Releases a CLI Tool (gws) for Workspace APIs: Providing a Unified Interface for Humans and AI Agents
Source: MarkTechPost Integrating Google Workspace APIs—such as Drive, Gmail, Calendar, and Sheets—into applications and data pipelines typically requires...

OpenAI Releases Symphony: An Open Source Agentic Framework for Orchestrating Autonomous AI Agents through Structured, Scalable Implementation Runs
Source: MarkTechPost OpenAI has released Symphony, an open-source framework designed to manage autonomous AI coding agents through structured...

YuanLab AI Releases Yuan 3.0 Ultra: A Flagship Multimodal MoE Foundation Model, Built for Stronger Intelligence and Unrivaled Efficiency
Source: MarkTechPost How can a trillion-parameter Large Language Model achieve state-of-the-art enterprise performance while simultaneously cutting its total...
LangWatch Open Sources the Missing Evaluation Layer for AI Agents to Enable End-to-End Tracing, Simulation, and Systematic Testing
Source: MarkTechPost As AI development shifts from simple chat interfaces to complex, multi-step autonomous agents, the industry has...
Physical Intelligence Team Unveils MEM for Robots: A Multi-Scale Memory System Giving Gemma 3-4B VLAs 15-Minute Context for Complex Tasks
Source: MarkTechPost Current end-to-end robotic policies, specifically Vision-Language-Action (VLA) models, typically operate on a single observation or a...
Meet SymTorch: A PyTorch Library that Translates Deep Learning Models into Human-Readable Equations
Source: MarkTechPost Can symbolic regression be the key to transforming opaque deep learning models into interpretable, closed-form mathematical...
How to Build a Stable and Efficient QLoRA Fine-Tuning Pipeline Using Unsloth for Large Language Models
Source: MarkTechPost In this tutorial, we demonstrate how to efficiently fine-tune a large language model using Unsloth and...
Google Drops Gemini 3.1 Flash-Lite: A Cost-efficient Powerhouse with Adjustable Thinking Levels Designed for High-Scale Production AI
Source: MarkTechPost Google has released Gemini 3.1 Flash-Lite, the most cost-efficient entry in the Gemini 3 model series....