Source: MarkTechPost
Understanding the Limitations of Current Omni-Modal Architectures
Large multimodal models (LMMs) have shown outstanding omni-capabilities across text, vision, and speech modalities, creating vast potential for diverse applications. While vision-oriented LMMs have shown success, omni-modal LMMs that support speech interaction based on visual information face challenges due to the intrinsic representational discrepancies across modalities. Recent omni-modal LMMs aim to unify text, vision, and speech by combining representations from individual modality encoders along the sequence dimension. However, they depend on large-scale data to learn modality alignments in a data-driven manner. This is not aligned to limited public tri-modal datasets and has insufficient flexibility to produce intermediate text results during speech interactions.
Categorizing Existing LMMs by Modal Focus
Current LMMs fall into three categories: vision-oriented, speech-oriented, and omni-modal. Vision-oriented LMMs such as LLaVA utilize vision encoders to extract visual features, which are then combined with textual inputs and passed into LLMs to generate text. Speech-oriented LMMs employ either continuous methods, such as Mini-Omni and LLaMA-Omni, to project features into LLM embedding spaces, or discrete speech units, like SpeechGPT and Moshi, to convert speech into discrete units for direct LLM processing. Omni-modal LMMs such as VITA-1.5, MiniCPM2.6-o, and Qwen2.5-Omni extract representations from various encoders, concatenate them for multimodal understanding, and use speech decoders for synthesis.
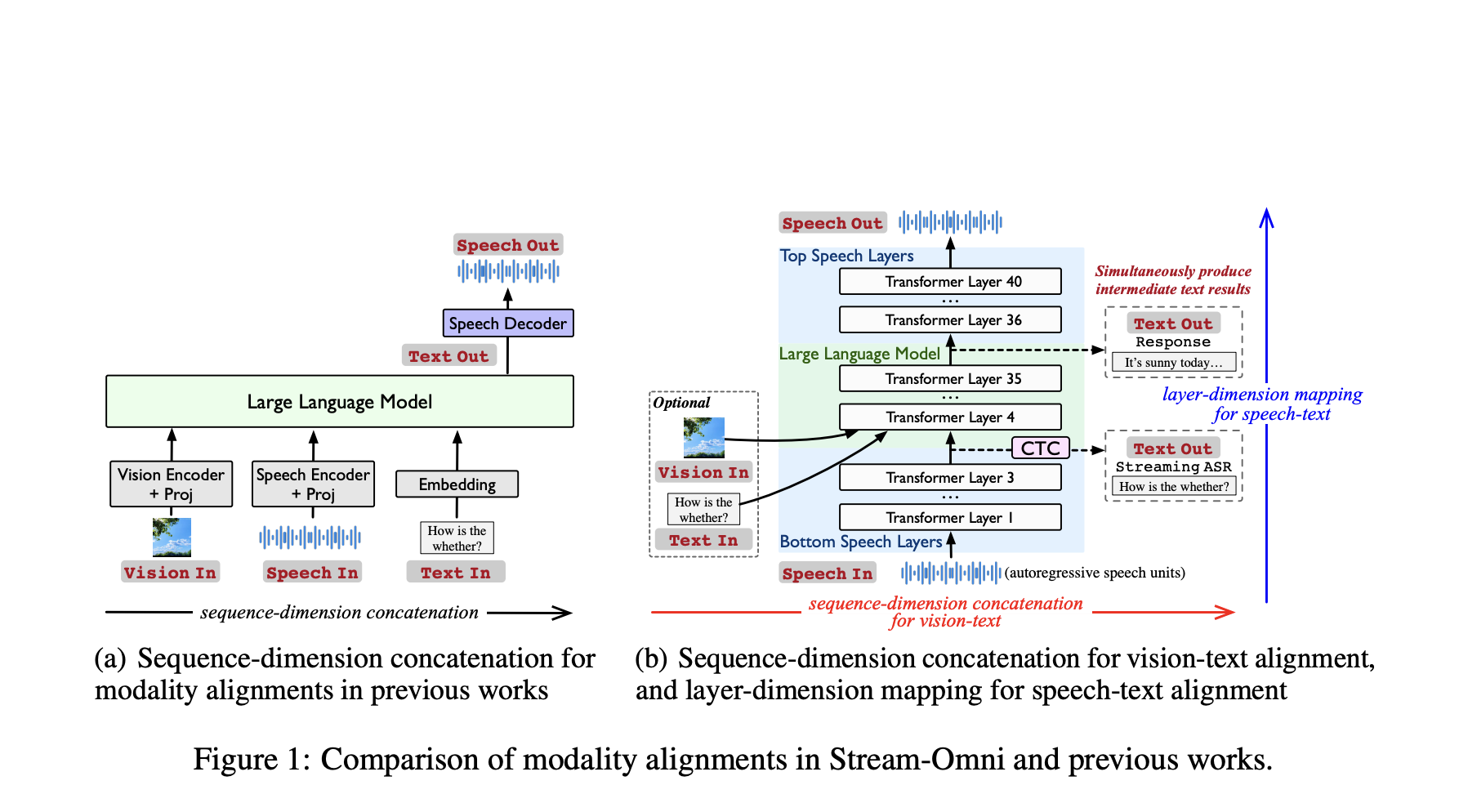
Introducing Stream-Omni: A Text-Centric Alignment Approach
Researchers from the University of Chinese Academy of Sciences have proposed Stream-Omni, a large language-vision-speech model designed to address the modality alignment challenges in omni-modal systems. It utilizes an LLM backbone and aligns vision and speech modalities for text based on their semantic relationships rather than simple concatenation approaches. Stream-Omni aligns modalities by integrating their semantic relationships with text. For vision, the method applies sequence-dimension concatenation to align vision and text. For speech, it introduces a CTC-based layer-dimension mapping for speech-text alignment. Stream-Omni’s design overcomes the limitations of concatenation-based methods by introducing targeted alignment mechanisms.

Architecture Overview: Dual-Layer Speech Integration and Visual Encoding
Stream-Omni’s architecture employs an LLM backbone with progressive modality alignment strategies. For vision-text alignment, Stream-Omni applies a vision encoder and a projection layer to extract visual representations. For speech-text alignment, it introduces special speech layers present at both the bottom and top of the LLM backbone, enabling bidirectional mapping between speech and text modalities. Stream-Omni constructs its training corpus through automated pipelines, utilizing LLaVA datasets for vision-text pairs, LibriSpeech and WenetSpeech for speech-text data, and creating the InstructOmni dataset by converting current instruction datasets using text-to-speech synthesis.
Benchmarking Multimodal Capabilities Across Domains
In visual understanding tasks, Stream-Omni achieves performance comparable to advanced vision-oriented LMMs and outperforms VITA-1.5, reducing modality interference while maintaining strong visual capabilities. For speech interaction, Stream-Omni shows outstanding knowledge-based performance using less speech data (23K hours) compared to discrete speech unit-based models such as SpeechGPT, Moshi, and GLM-4-Voice. In vision-grounded speech interaction evaluations on the SpokenVisIT benchmark, Stream-Omni outperforms VITA-1.5 in real-world visual understanding. The quality of speech-text mapping with Stream-Omni achieves superior ASR performance on the LibriSpeech benchmark in both accuracy and inference time.
Conclusion: A Paradigm Shift in Multimodal Alignment
In conclusion, researchers introduced Stream-Omni, a solution to the modality alignment challenges in omni-modal systems. This method shows that efficient modality alignment can be achieved through sequence-dimension concatenation for vision-text pairs and layer-dimension mapping for speech-text integration, eliminating the need for extensive tri-modal training data. Moreover, this research establishes a new paradigm for omni-modal LMMs, showing that targeted alignment strategies based on semantic relationships can overcome the limitations of traditional concatenation-based approaches in multimodal AI systems.
Check out the Paper and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Sajjad Ansari
Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.
