
Python Concepts Every AI Engineer Must Master
Source: MachineLearningMastery.com In this article, you will learn five essential Python concepts that every AI engineer must master...

Moonshot AI Launches Kimi Work, a Local Desktop Agent Reportedly Running on Kimi K2.6 With a 300-Sub-Agent Agent Swarm
Source: MarkTechPost Moonshot AI has introduced Kimi Work, an AI agent that runs on your own desktop. The...
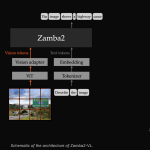
Zyphra Release Zamba2-VL: Hybrid Mamba2–Transformer Vision-Language Models That Cut Time-to-First-Token by About an Order of Magnitude
Source: MarkTechPost Zyphra has released Zamba2-VL, a family of open vision-language models. The release covers three sizes: 1.2B,...
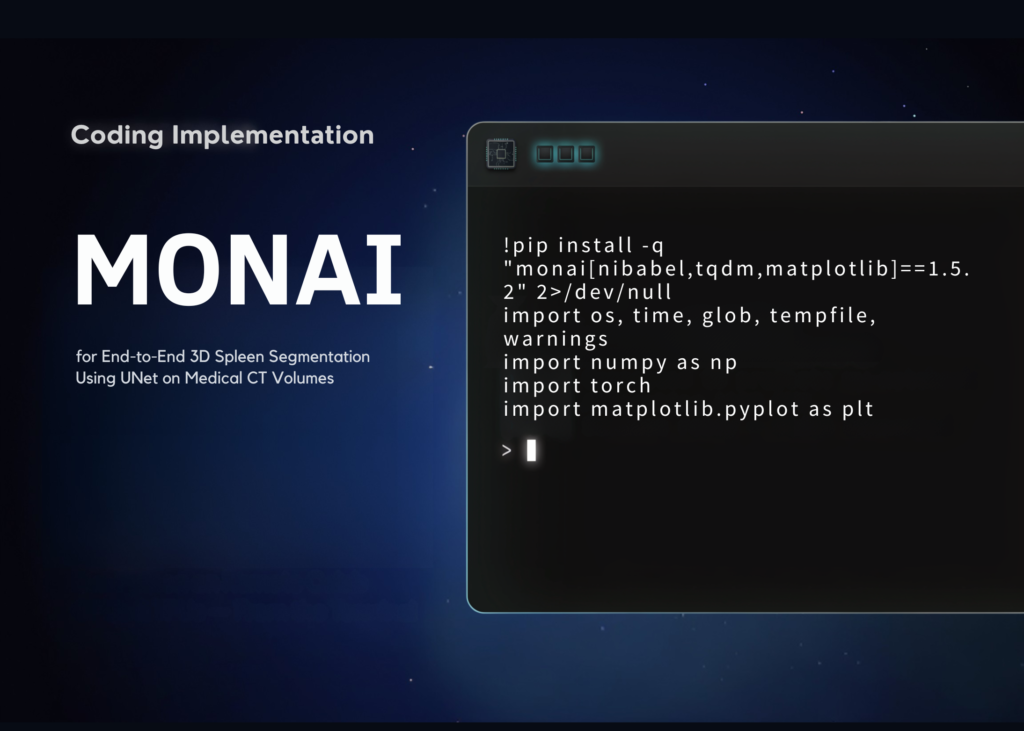
A Coding Implementation on MONAI for End-to-End 3D Spleen Segmentation Using UNet on Medical CT Volumes
Source: MarkTechPost In this tutorial, we build an end-to-end 3D medical image segmentation pipeline using MONAI to segment...
Perplexity Moves Deep Research Into Computer, Routing Research Subtasks Across 20+ Frontier Models For Reports, Decks, And Dashboards
Source: MarkTechPost Perplexity has moved Deep Research into Computer, its multi-model orchestration system. The upgrade improves accuracy, depth...

xAI Ships Grok Build Plugin Marketplace With MongoDB, Vercel, Sentry, Chrome DevTools, Cloudflare, and Superpowers Plugins at Launch
Source: MarkTechPost Today, xAI shipped the Grok Build Plugin Marketplace. It is a built-in catalog of plugins for...

Jinhua Zhao named head of the Department of Urban Studies and Planning
Source: MIT News – Artificial intelligence Jinhua Zhao MCP ’04, SM ’04, PhD ’09 has been appointed head...
When it comes to predicting people’s preferences, it pays to consider “the power of three”
Source: MIT News – Artificial intelligence In his 1927 paper, “A law of comparative judgment,” the American psychologist...

MIT affiliates win 2026 Hertz Foundation Fellowships
Source: MIT News – Artificial intelligence The Hertz Foundation announced that it awarded 2026 fellowships to three current MIT students...

Multi-Label Text Classification with Scikit-LLM
Source: MachineLearningMastery.com In this article, you will learn how to perform multi-label text classification using large language models...