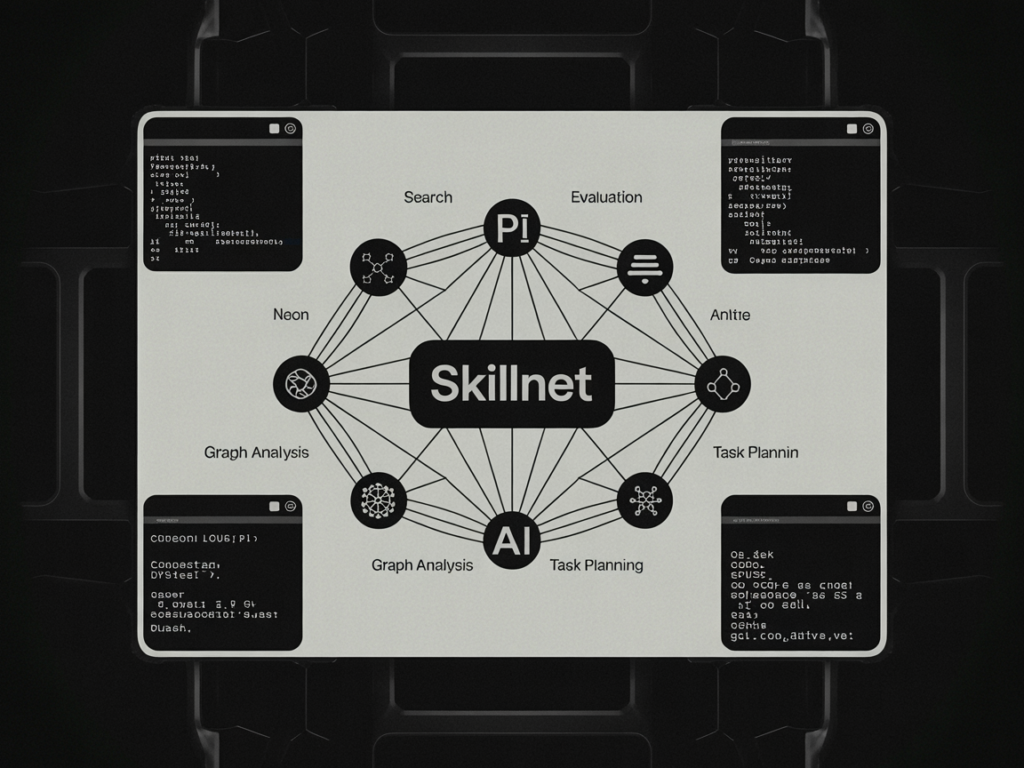
Build Skill-Augmented AI Agents with SkillNet for Search, Evaluation, Graph Analysis, and Task Planning
Source: MarkTechPost In this tutorial, we implement a SkillNet use case as a practical framework for discovering, installing,...

Best Text-to-Speech TTS Models in 2026: A Benchmark-Based Comparison
Source: MarkTechPost Text-to-speech TTS moved fast over the past year. The line between synthetic and human speech narrowed....
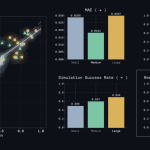
Genesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model Evaluation
Source: MarkTechPost Genesis AI released Genesis World 1.0. The platform consists of four components: the Genesis World physics...
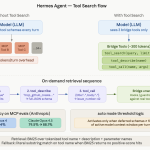
Hermes Agent Ships Tool Search for MCP: Anthropic Evals Show 49% to 74% Accuracy Gain on Opus 4
Source: MarkTechPost Nous Research’s open-source Hermes Agent now ships a Tool Search feature. It directly addresses a growing...

Serving Multiple Users at Once: How Continuous Batching Keeps LLM Inference Efficient
Source: MachineLearningMastery.com “”“ Continuous batching = iteration-level scheduling + ragged (packed) batching. Two approaches are compared (both run...
How to Use AgentTrove: Streaming 1.7M Agentic Traces and Building a Clean ShareGPT SFT Dataset in Python
Source: MarkTechPost In this tutorial, we explore AgentTrove, one of the largest open-source collections of agentic interaction traces,...
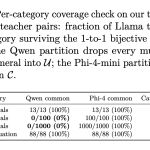
NVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1B
Source: MarkTechPost Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student. The...

StepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search Workflows
Source: MarkTechPost StepFun today released Step 3.7 Flash, a multimodal Mixture-of-Experts model targeting agentic use cases. It adds...

Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven Communication
Source: MarkTechPost GPU communication overhead is a measurable bottleneck in production AI workloads. According to data cited by...
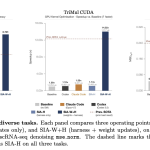
Hexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model Weights
Source: MarkTechPost Most AI agents stop improving once a human stops tuning them. The model is fixed. The...