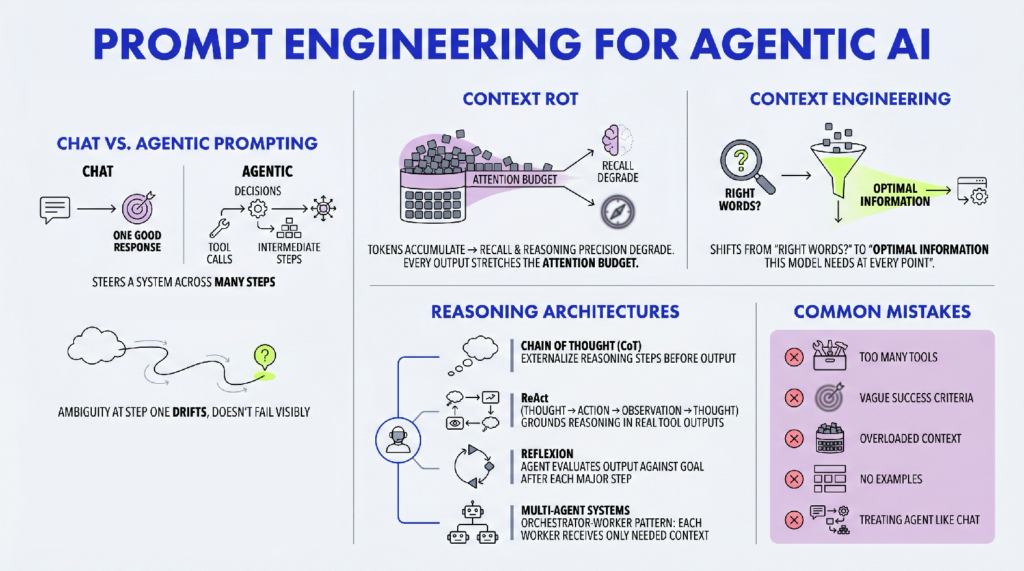
Prompt Engineering for Agentic AI
Source: MachineLearningMastery.com In this article, you will learn how prompt engineering changes fundamentally when applied to agentic AI...

How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI API
Source: MarkTechPost In this tutorial, we build an advanced agentic AI system using the OpenAI API and a...
Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility
Source: MarkTechPost As LLM-powered agents move from research to production, one design tension is becoming harder to ignore:...

Stochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It
Source: MarkTechPost Modern language models are trained on data with extremely uneven token distributions. A small number of...
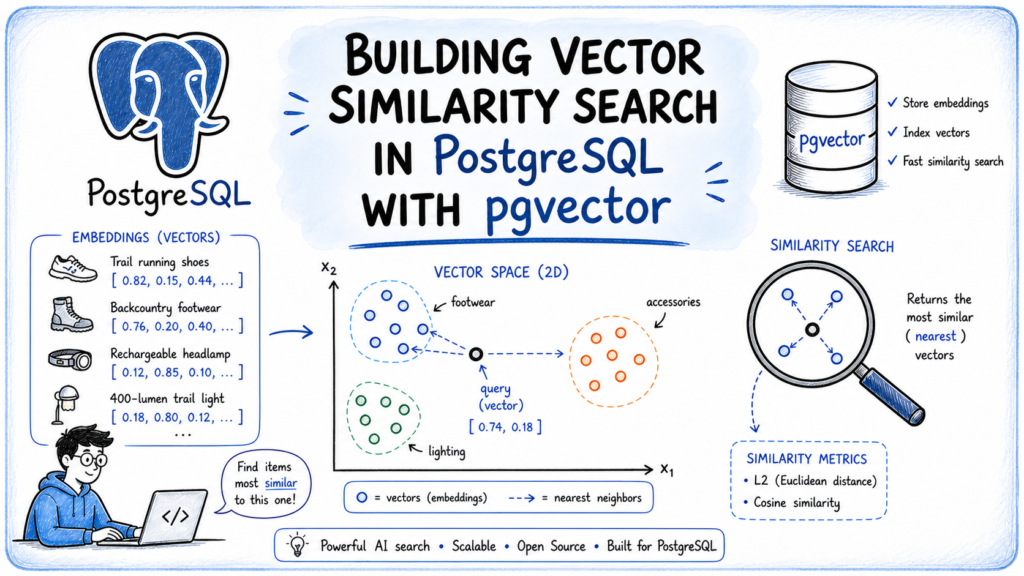
Building Vector Similarity Search in PostgreSQL with pgvector
Source: MachineLearningMastery.com In this article, you will learn how to implement vector similarity search in PostgreSQL using the...

NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token Horizon
Source: MarkTechPost Pretraining frontier-scale LLMs in FP8 is now standard practice, but moving to 4-bit floating point has...

A Coding Implementation to Compress and Benchmark Instruction-Tuned LLMs with FP8, GPTQ, and SmoothQuant Quantization using llmcompressor
Source: MarkTechPost In this tutorial, we explore how to apply post-training quantization to an instruction-tuned language model using...

Vercel Labs Introduces Zero, a Systems Programming Language Designed So AI Agents Can Read, Repair, and Ship Native Programs
Source: MarkTechPost Most programming languages were designed for humans who read error messages, interpret warnings, and manually trace...
A Coding Guide Implementing SHAP Explainability Workflows with Explainer Comparisons, Maskers, Interactions, Drift, and Black-Box Models
Source: MarkTechPost In this tutorial, we implement SHAP workflows as a practical framework for interpreting machine learning models...
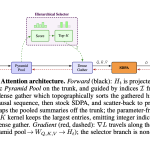
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Source: MarkTechPost Training large language models on long sequences has a well-known problem: attention is expensive. The scaled...