
Agentic Programming: A Roadmap
Source: MachineLearningMastery.com In this article, you will learn what agentic programming is, how production-grade AI agents are built...
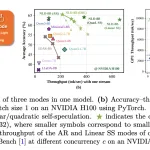
NVIDIA AI Releases Nemotron-Labs-Diffusion: A Tri-Mode Language Model with 6× Tokens Per Forward Over Qwen3-8B
Source: MarkTechPost NVIDIA researchers have released Nemotron-Labs-Diffusion, a language model family that unifies three decoding modes in one...

Building AI models that understand chemical principles
Source: MIT News – Artificial intelligence Among all of the possible chemical compounds, it’s estimated that between 1020 and...

Justin Solomon appointed associate dean of engineering education
Source: MIT News – Artificial intelligence Justin Solomon, associate professor in the MIT Department of Electrical Engineering and...
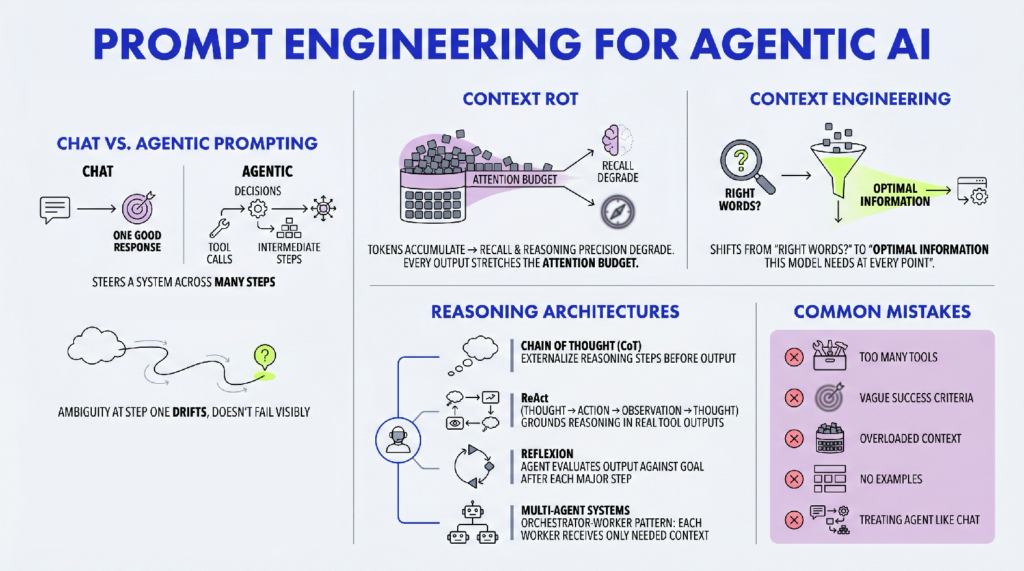
Prompt Engineering for Agentic AI
Source: MachineLearningMastery.com In this article, you will learn how prompt engineering changes fundamentally when applied to agentic AI...

How to Build an Advanced Agentic AI System with Planning, Tool Calling, Memory, and Self-Critique Using OpenAI API
Source: MarkTechPost In this tutorial, we build an advanced agentic AI system using the OpenAI API and a...
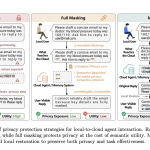
Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility
Source: MarkTechPost As LLM-powered agents move from research to production, one design tension is becoming harder to ignore:...

Stochastic Gradient Descent (SGD’s) Frequency Bias and How Adam Fixes It
Source: MarkTechPost Modern language models are trained on data with extremely uneven token distributions. A small number of...
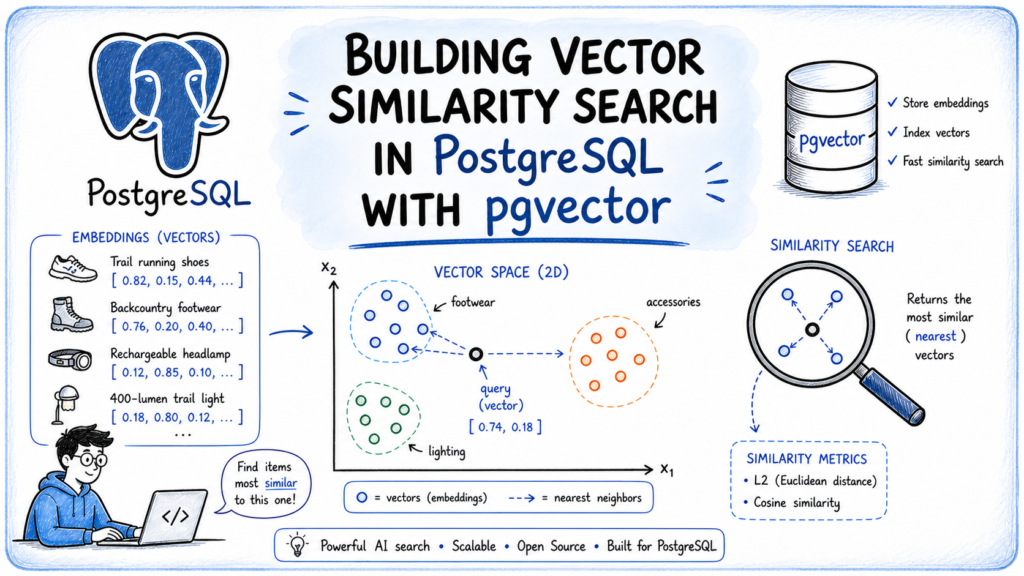
Building Vector Similarity Search in PostgreSQL with pgvector
Source: MachineLearningMastery.com In this article, you will learn how to implement vector similarity search in PostgreSQL using the...

NVIDIA Introduces a 4-Bit Pretraining Methodology Using NVFP4, Validated on a 12B Hybrid Mamba-Transformer at 10T Token Horizon
Source: MarkTechPost Pretraining frontier-scale LLMs in FP8 is now standard practice, but moving to 4-bit floating point has...