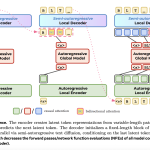
Meta and Stanford Researchers Propose Fast Byte Latent Transformer That Reduces Inference Memory Bandwidth by Over 50% Without Tokenization
Source: MarkTechPost A team of researchers from Meta, Stanford University, and the University of Washington have introduced three...
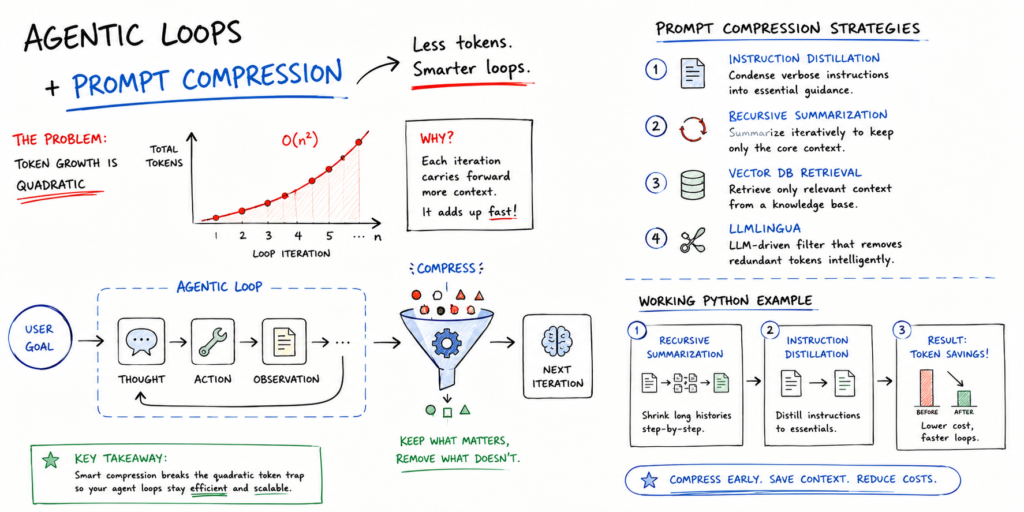
Implementing Prompt Compression to Reduce Agentic Loop Costs
Source: MachineLearningMastery.com In this article, you will learn what prompt compression is, why it matters for agentic AI...
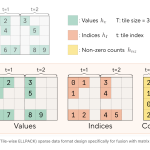
Sakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMs
Source: MarkTechPost Scaling large language models (LLMs) is expensive. Every token processed during inference and every gradient computed...

A Coding Implementation to Build Agent-Native Memory Infrastructure with Memori for Persistent Multi-User and Multi-Session LLM Applications
Source: MarkTechPost In this tutorial, we implement how Memori serves as an agent-native memory infrastructure layer for building...

Best Vector Databases in 2026: Pricing, Scale Limits, and Architecture Tradeoffs Across Nine Leading Systems
Source: MarkTechPost Vector databases have graduated from experimental tooling to mission-critical infrastructure. In 2026, vector databases serve as...

OpenClaw vs Hermes Agent: Why Nous Research’s Self-Improving Agent Now Leads OpenRouter’s Global Rankings
Source: MarkTechPost The open-source AI agent space has a new leader. As of May 10, 2026, Hermes Agent...
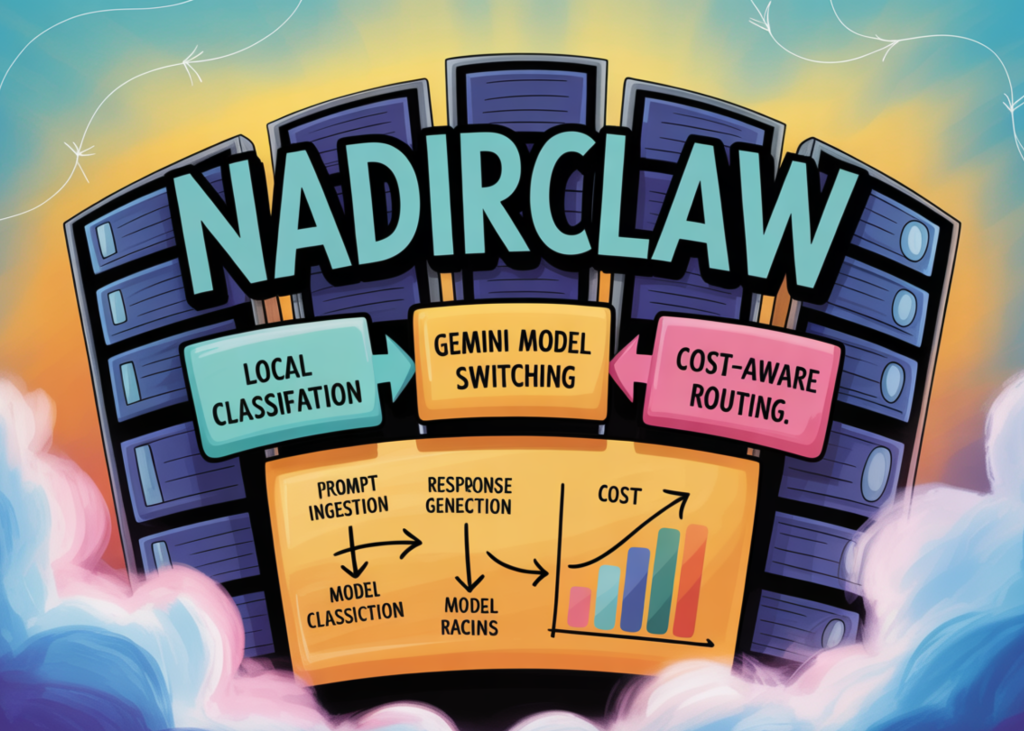
How to Build a Cost-Aware LLM Routing System with NadirClaw Using Local Prompt Classification and Gemini Model Switching
Source: MarkTechPost In this tutorial, we explore NadirClaw as an intelligent routing layer that classifies prompts into simple...

NVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTX
Source: MarkTechPost NVIDIA AI researchers recently released cuda-oxide, an experimental compiler that allows developers to write CUDA SIMT...

A Coding Implementation to Recover Hidden Malware IOCs with FLARE-FLOSS Beyond Classic Strings Analysis
Source: MarkTechPost In this tutorial, we explore how FLARE-FLOSS helps us recover hidden and obfuscated strings from a...
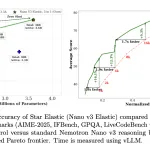
NVIDIA AI Releases Star Elastic: One Checkpoint that Contains 30B, 23B, and 12B Reasoning Models with Zero-Shot Slicing
Source: MarkTechPost Training a family of large language models (LLMs) has always come with a painful multiplier: every...