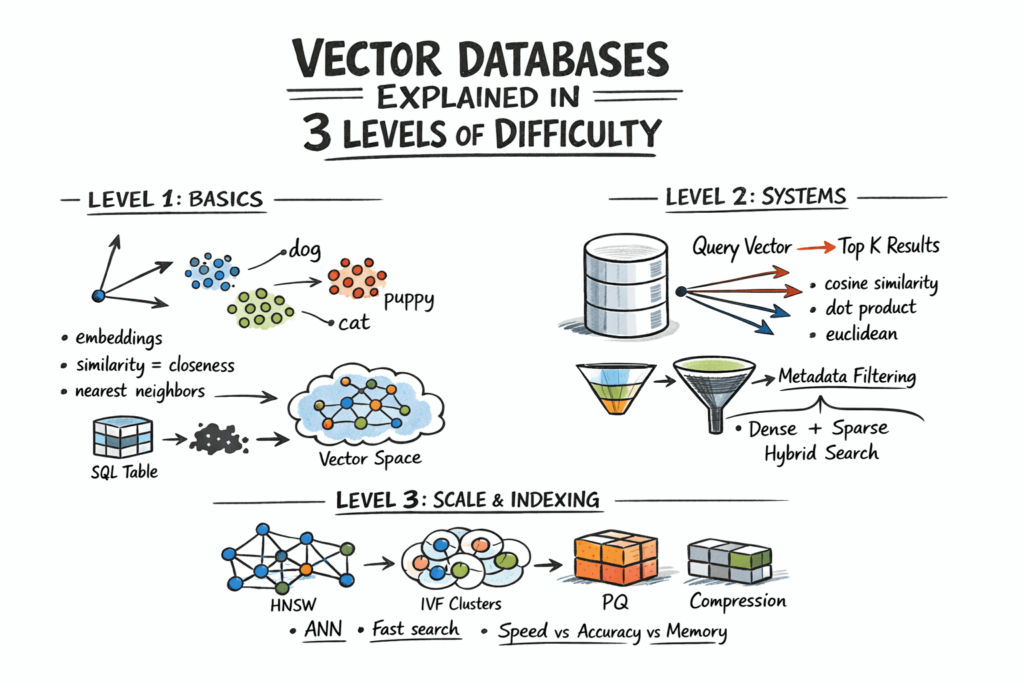
Vector Databases Explained in 3 Levels of Difficulty
Source: MachineLearningMastery.com In this article, you will learn how vector databases work, from the basic idea of similarity...
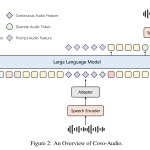
Tencent AI Open Sources Covo-Audio: A 7B Speech Language Model and Inference Pipeline for Real-Time Audio Conversations and Reasoning
Source: MarkTechPost Tencent AI Lab has released Covo-Audio, a 7B-parameter end-to-end Large Audio Language Model (LALM). The model...

AI system learns to keep warehouse robot traffic running smoothly
Source: MIT News – Artificial intelligence Inside a giant autonomous warehouse, hundreds of robots dart down aisles as...
How to Build a Vision-Guided Web AI Agent with MolmoWeb-4B Using Multimodal Reasoning and Action Prediction
Source: MarkTechPost In this tutorial, we explore MolmoWeb, Ai2’s open multimodal web agent that understands and interacts with...

Augmenting citizen science with computer vision for fish monitoring
Source: MIT News – Artificial intelligence Each spring, river herring populations migrate from Massachusetts coastal waters to begin their...

5 Practical Techniques to Detect and Mitigate LLM Hallucinations Beyond Prompt Engineering
Source: MachineLearningMastery.com In this article, you will learn why large language model hallucinations happen and how to reduce...

Wristband enables wearers to control a robotic hand with their own movements
Source: MIT News – Artificial intelligence The next time you’re scrolling your phone, take a moment to appreciate...

NVIDIA AI Introduces PivotRL: A New AI Framework Achieving High Agentic Accuracy With 4x Fewer Rollout Turns Efficiently
Source: MarkTechPost Post-training Large Language Models (LLMs) for long-horizon agentic tasks—such as software engineering, web browsing, and complex...
Google Introduces TurboQuant: A New Compression Algorithm that Reduces LLM Key-Value Cache Memory by 6x and Delivers Up to 8x Speedup, All with Zero Accuracy Loss
Source: MarkTechPost The scaling of Large Language Models (LLMs) is increasingly constrained by memory communication overhead between High-Bandwidth...
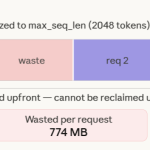
Paged Attention in Large Language Models LLMs
Source: MarkTechPost When running LLMs at scale, the real limitation is GPU memory rather than compute, mainly because...