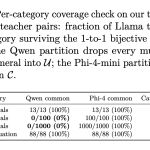
NVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1B
Source: MarkTechPost Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student. The...

StepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search Workflows
Source: MarkTechPost StepFun today released Step 3.7 Flash, a multimodal Mixture-of-Experts model targeting agentic use cases. It adds...

Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven Communication
Source: MarkTechPost GPU communication overhead is a measurable bottleneck in production AI workloads. According to data cited by...
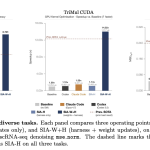
Hexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model Weights
Source: MarkTechPost Most AI agents stop improving once a human stops tuning them. The model is fixed. The...

How to Design an End-to-End Ansible Automation Lab with Playbooks, Inventories, Roles, Vault, Dynamic Inventory, and Custom Modules
Source: MarkTechPost In this tutorial, we build a complete Ansible lab that runs end-to-end in Google Colab or...

Liquid AI Releases LFM2.5-8B-A1B: An On-Device MoE Model With 8.3B Total and 1.5B Active Parameters
Source: MarkTechPost Liquid AI just shipped LFM2.5-8B-A1B. It is an on-device Mixture-of-Experts (MoE) model built for tool calling....

Anthropic Ships Claude Opus 4.8 Alongside Dynamic Workflows and Cheaper Fast Mode, With Workflows Capped at 1,000 Subagents
Source: MarkTechPost Anthropic just launched Claude Opus 4.8. Also, there two Claude Code updates shipped with it. Dynamic...

Media Advisory: MIT to establish regional quantum hub
Source: MIT News – Artificial intelligence MIT and the Commonwealth of Massachusetts announced plans to establish the Quantum...

Building a Context Pruning Pipeline for Long-Running Agents
Source: MachineLearningMastery.com In this article, you will learn how to implement a context pruning pipeline for long-running AI...
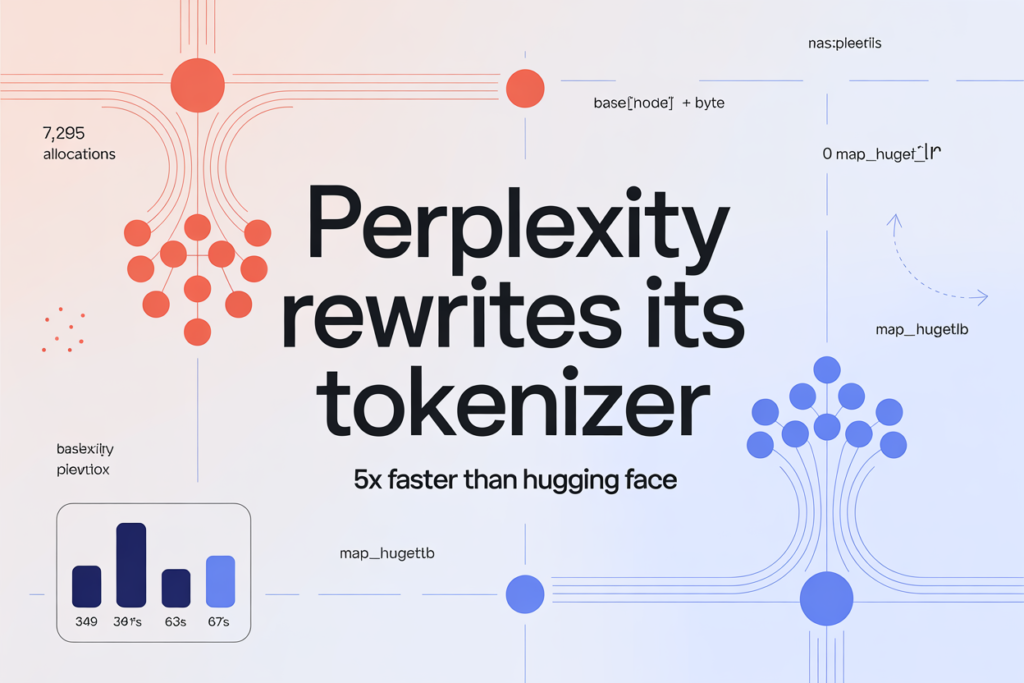
Perplexity AI Open-Sources Unigram Tokenizer That Achieves 5x Lower p50 Latency Than Hugging Face tokenizers Crate
Source: MarkTechPost Perplexity AI’s research team reimplemented their Unigram tokenizer from scratch in Rust and open-sourced the code...