Source: MarkTechPost
Part 1: Uploading a Dataset to Hugging Face Hub
Introduction
This part of the tutorial walks you through the process of uploading a custom dataset to the Hugging Face Hub. The Hugging Face Hub is a platform that allows developers to share and collaborate on datasets and models for machine learning.
Here, we’ll take an existing Python instruction-following dataset, transform it into a format suitable for training the latest Large Language Models (LLMs), and then upload it to Hugging Face for public use. We’re specifically formatting our data to match the Llama 3.2 chat template, which makes it ready for fine-tuning Llama 3.2 models.
Step 1: Installation and Authentication
First, we need to install the necessary libraries and authenticate with the Hugging Face Hub:
!pip install -q datasets !huggingface-cli login What’s happening here:
- datasets is Hugging Face’s library for working with machine learning datasets
- The quiet flag -q reduces installation output messages
- huggingface-cli login will prompt you to enter your Hugging Face authentication token
- You can find your token by going to your Hugging Face account settings → Access Tokens
After running this cell, you will be prompted to enter your token. This authenticates your session and allows you to push content to the Hub.
Step 2: Load the Dataset and Define the Transformation Function
Next, we’ll load an existing dataset and define a function to transform it to match the Llama 3.2 chat format:
from datasets import load_dataset # Load your complete custom dataset dataset = load_dataset('Vezora/Tested-143k-Python-Alpaca') # Define a function to transform the data def transform_conversation(example): system_prompt = """ You are an expert Python coding assistant. Your role is to help users write clean, efficient, and bug-free Python code. You have been trained on a diverse set of high-quality Python code samples, all of which passed rigorous automated testing for functionality and performance. Always follow best practices in Python programming, provide concise and readable solutions, and ensure that your responses include informative comments when necessary. When presented with a coding problem, first create a detailed pseudocode that outlines the structure and logic of the solution step-by-step. Once the pseudocode is complete, follow it to generate the actual Python code. This approach will help ensure clarity and alignment with the desired logic before writing the code. If asked to modify existing code, provide pseudocode highlighting the changes and optimizations to be made, focusing on improvements related to performance, error handling, and robustness. Remember to explain your thought process and rationale clearly for any modifications or code suggestions you provide. """ instruction = example['instruction'].strip() # Accessing the instruction column output = example['output'].strip() # Accessing the output column formatted_text = ( f"""<|begin_of_text|><|start_header_id|>system<|end_header_id|> {system_prompt} <|eot_id|>n<|start_header_id|>user<|end_header_id|> {instruction} <|eot_id|><|start_header_id|>assistant<|end_header_id|> {output}<|eot_id|>""" ) # instruction = example['instruction'].strip() # Accessing the instruction column # output = example['output'].strip() # Accessing the output column # Apply the new template # Since there is no system prompt, we construct the string without the SYS part # formatted_text = f'[INST] {instruction} [/INST] {output} ' return {'text': formatted_text} What’s happening here:
- We load the ‘Vezora/Tested-143k-Python-Alpaca’ dataset, which contains Python programming instructions and outputs
- We define a transformation function that restructures each example into the Llama 3.2 chat format
- We include a detailed system prompt that gives the model context about its role as a Python coding assistant
- The special tokens like <|begin_of_text|>, <|start_header_id|>, and <|eot_id|> are Llama 3.2’s way of formatting conversational data
- This function creates a properly formatted conversation with system, user, and assistant messages
The system prompt is particularly important as it defines the persona and behavior expectations for the model. In this case, we’re instructing the model to act as an expert Python coding assistant that follows best practices and provides well-commented, efficient solutions.
Step 3: Apply the Transformation to the Dataset
Now we apply our transformation function to the entire dataset:
# Apply the transformation to the entire dataset transformed_dataset = dataset['train'].map(transform_conversation)What’s happening here:
- The map() function applies our transformation function to every example in the dataset
- This processes all 143,000 examples in the dataset, reformatting them into the Llama 3.2 chat format
- The result is a new dataset with the same content but structured properly for fine-tuning Llama 3.2
This transformation is crucial because it reformats the data into the specific template required by the Llama 3.2 model family. Without this formatting, the model wouldn’t recognize the different roles in the conversation (system, user, assistant) or where each message begins and ends.
Step 4: Upload the Dataset to Hugging Face Hub
With our dataset prepared, we can now upload it to the Hugging Face Hub:
transformed_dataset.push_to_hub("Llama-3.2-Python-Alpaca-143k")What’s happening here:
- The push_to_hub() method uploads our transformed dataset to the Hugging Face Hub
- “Llama-3.2-Python-Alpaca-143k” will be the name of your dataset repository
- This creates a new repository under your username: https://huggingface.co/datasets/YOUR_USERNAME/Llama-3.2-Python-Alpaca-143k
- The dataset will now be publicly available for others to download and use
After running this cell, you’ll see progress bars indicating the upload status. Once complete, you can visit the Hugging Face Hub to view your newly uploaded dataset, edit its description, and share it with the community.
This dataset is now ready to be used for fine-tuning Llama 3.2 models on Python programming tasks, with properly formatted conversations that include system instructions, user queries, and assistant responses!
Part 2: Fine-tuning and Uploading a Model to Hugging Face Hub
Now that we’ve prepared and uploaded our dataset, let’s move on to fine-tuning a model and uploading it to the Hugging Face Hub.
Step 1: Install Required Libraries
First, we need to install all the necessary libraries for fine-tuning large language models efficiently:
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install "git+https://github.com/huggingface/transformers.git" !pip install -U trl !pip install --no-deps trl peft accelerate bitsandbytes !pip install torch torchvision torchaudio triton !pip install xformers !python -m xformers.info !python -m bitsandbytesWhat this does: Installs Unsloth (a library for faster LLM fine-tuning), the latest version of Transformers, TRL (for reinforcement learning), PEFT (for parameter-efficient fine-tuning), and other dependencies needed for training. The xformers and bitsandbytes libraries help with memory efficiency.
Step 2: Load the Dataset
Next, we load the dataset we prepared in the previous section:
from unsloth import FastLanguageModel from trl import SFTTrainer from transformers import TrainingArguments import torch from datasets import load_dataset max_seq_length = 2048 dataset = load_dataset("nikhiljatiwal/Llama-3.2-Python-Alpaca-143k", split="train") What this does: Sets the maximum sequence length for our model and loads our previously uploaded Python coding dataset from Hugging Face.
Step 3: Load the Pre-trained Model
Now we load a quantized version of Llama 3.2:
model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/Llama-3.2-3B-Instruct-bnb-4bit", max_seq_length = max_seq_length, dtype = None, load_in_4bit = True ) What this does: Loads a 4-bit quantized version of Llama 3.2 3B Instruct model from Unsloth’s repository. Quantization reduces the memory footprint while maintaining most of the model’s performance.
Step 4: Configure PEFT (Parameter-Efficient Fine-Tuning)
We’ll set up the model for efficient fine-tuning using LoRA (Low-Rank Adaptation):
model = FastLanguageModel.get_peft_model( model, r = 16, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 16, lora_dropout = 0, # Supports any, but = 0 is optimized bias = "none", # Supports any, but = "none" is optimized # [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes! use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context random_state = 3407, use_rslora = False, # We support rank stabilized LoRA loftq_config = None, # And LoftQ max_seq_length = max_seq_length ) What this does: Configures the model for Parameter-Efficient Fine-Tuning with LoRA. This technique only trains a small number of new parameters while keeping most of the original model frozen, allowing efficient training with limited resources. We’re targeting specific projection layers in the model with a rank of 16.
Step 5: Mount Google Drive for Saving
To ensure our trained model is saved even if the session disconnects:
from google.colab import drive drive.mount("https://www.marktechpost.com/content/drive")What this does: Mounts your Google Drive to save checkpoints and the final model.
Step 6: Set Up Training and Start Training
Now we configure and start the training process:
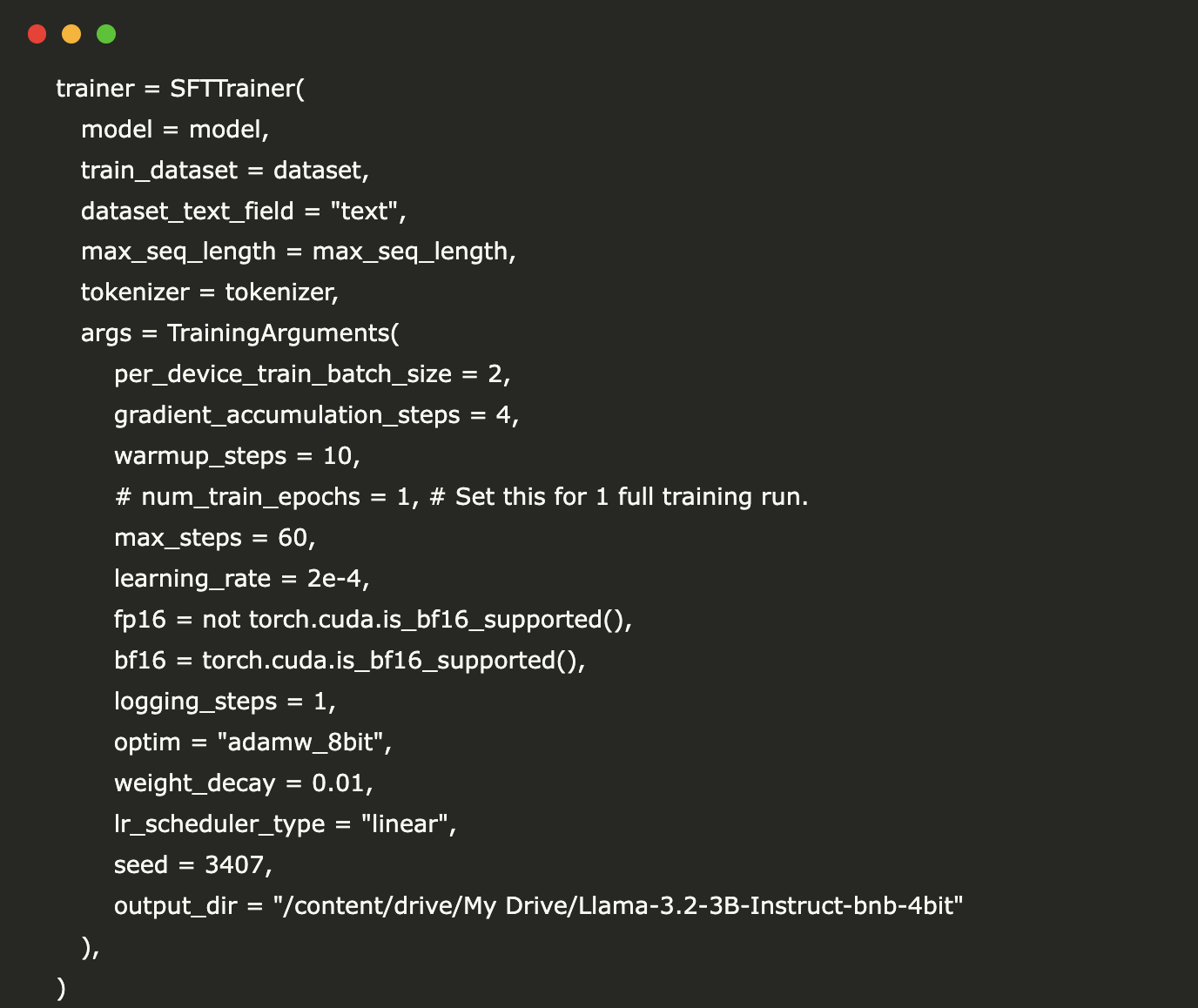
trainer = SFTTrainer( model = model, train_dataset = dataset, dataset_text_field = "text", max_seq_length = max_seq_length, tokenizer = tokenizer, args = TrainingArguments( per_device_train_batch_size = 2, gradient_accumulation_steps = 4, warmup_steps = 10, # num_train_epochs = 1, # Set this for 1 full training run. max_steps = 60, learning_rate = 2e-4, fp16 = not torch.cuda.is_bf16_supported(), bf16 = torch.cuda.is_bf16_supported(), logging_steps = 1, optim = "adamw_8bit", weight_decay = 0.01, lr_scheduler_type = "linear", seed = 3407, output_dir = "https://www.marktechpost.com/content/drive/My Drive/Llama-3.2-3B-Instruct-bnb-4bit" ), ) trainer.train()What this does: Creates a Supervised Fine-Tuning Trainer with our model, dataset, and training parameters. The training runs for 60 steps with a batch size of 2, gradient accumulation of 4, and a learning rate of 2e-4. The model checkpoints will be saved to Google Drive.
Step 7: Save the Fine-tuned Model Locally
After training, we save our model:
model.save_pretrained("lora_model") # Local saving tokenizer.save_pretrained("lora_model")What this does: Saves the fine-tuned LoRA model and tokenizer to a local directory.
Step 8: Upload the Model to Hugging Face Hub
Finally, we upload our fine-tuned model to Hugging Face:
import os from google.colab import userdata HF_TOKEN = userdata.get('HF_WRITE_API_KEY') model.push_to_hub_merged("nikhiljatiwal/Llama-3.2-3B-Instruct-code-bnb-4bit", tokenizer, save_method = "merged_16bit", token=HF_TOKEN)Conclusion
In this guide, we demonstrated a complete workflow for AI model customization using Hugging Face. We transformed a Python instruction dataset into Llama 3.2 format with a specialized system prompt and uploaded it as “Llama-3.2-Python-Alpaca-143k”. We then fine-tuned a Llama 3.2 model using efficient techniques (4-bit quantization and LoRA) with minimal computing resources. Finally, we shared both resources on Hugging Face Hub, making our Python coding assistant available to the community. This project showcases how accessible AI development has become, enabling developers to create specialized models for specific tasks with relatively modest resources.
Here is the Colab Notebook_Llama_3_2_3B_Instruct_code and Colab Notebook_Llama_3_2_Python_Alpaca_143k . Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.

Nikhil
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
