
Researchers from MIT, NVIDIA, and Zhejiang University Propose TriAttention: A KV Cache Compression Method That Matches Full Attention at 2.5× Higher Throughput
Source: MarkTechPost Long-chain reasoning is one of the most compute-intensive tasks in modern large language models. When a...
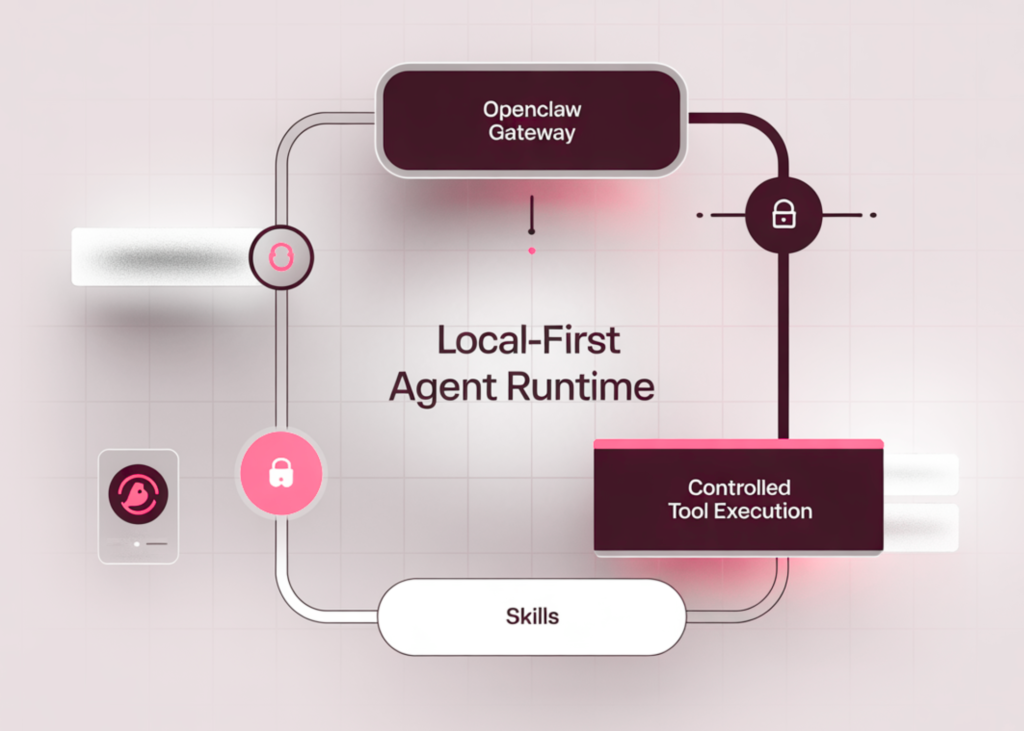
How to Build a Secure Local-First Agent Runtime with OpenClaw Gateway, Skills, and Controlled Tool Execution
Source: MarkTechPost In this tutorial, we build and operate a fully local, schema-valid OpenClaw runtime. We configure the...
How Knowledge Distillation Compresses Ensemble Intelligence into a Single Deployable AI Model
Source: MarkTechPost Complex prediction problems often lead to ensembles because combining multiple models improves accuracy by reducing variance...