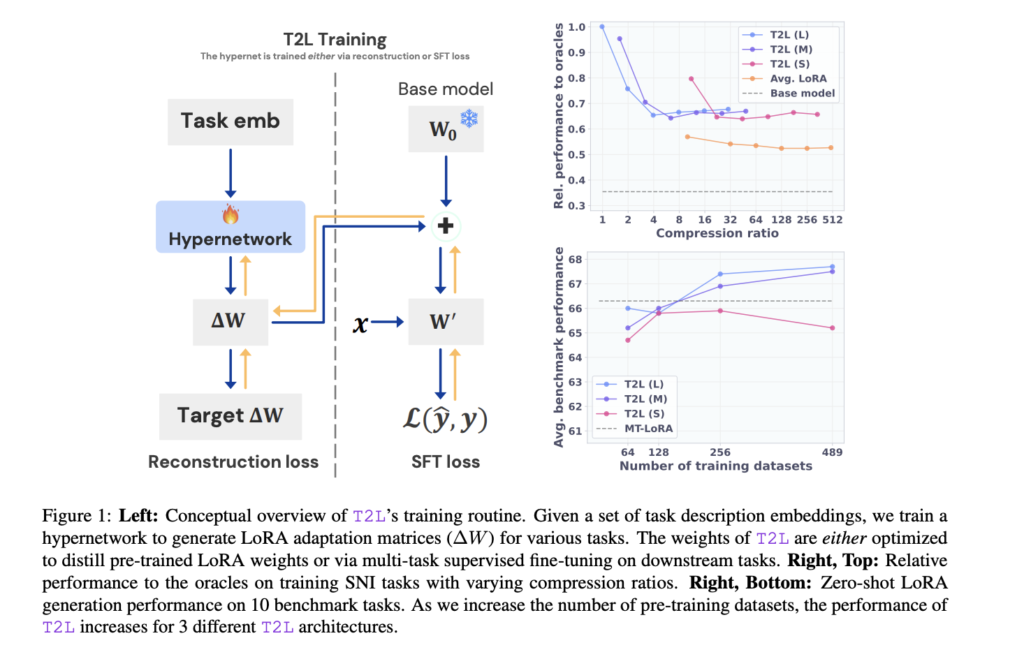
Sakana AI Introduces Text-to-LoRA (T2L): A Hypernetwork that Generates Task-Specific LLM Adapters (LoRAs) based on a Text Description of the Task
Source: MarkTechPost Transformer models have significantly influenced how AI systems approach tasks in natural language understanding, translation, and...
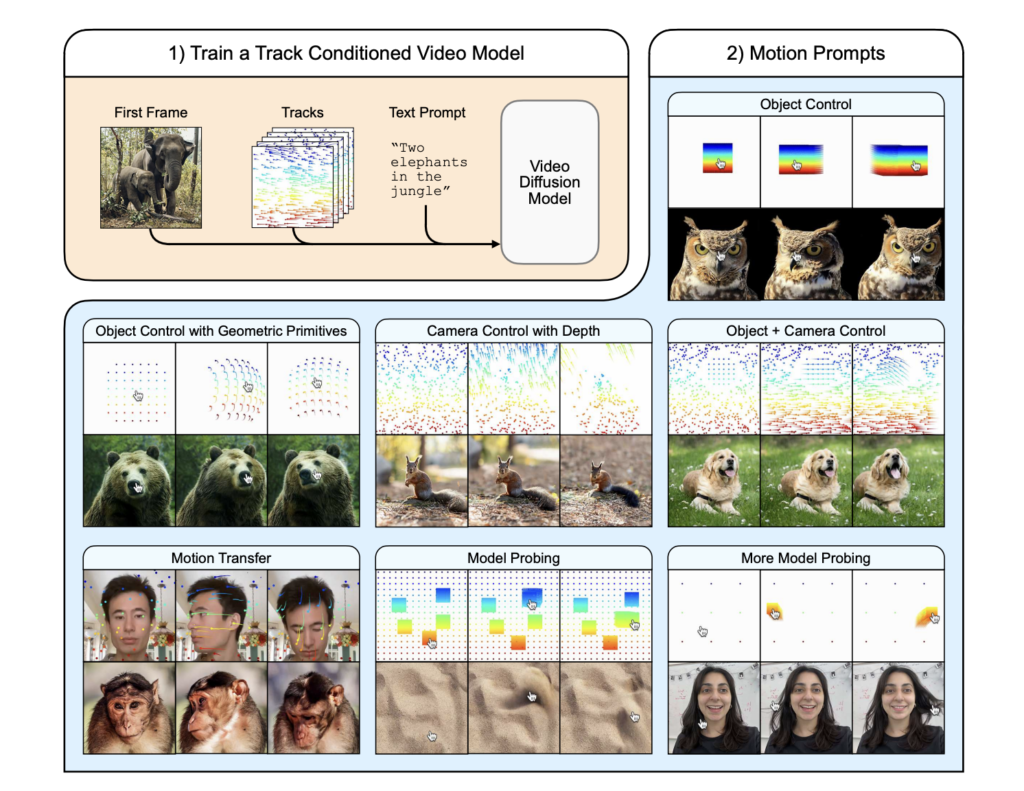
Highlighted at CVPR 2025: Google DeepMind’s ‘Motion Prompting’ Paper Unlocks Granular Video Control
Source: MarkTechPost Key Takeaways: Researchers from Google DeepMind, the University of Michigan & Brown university have developed “Motion...
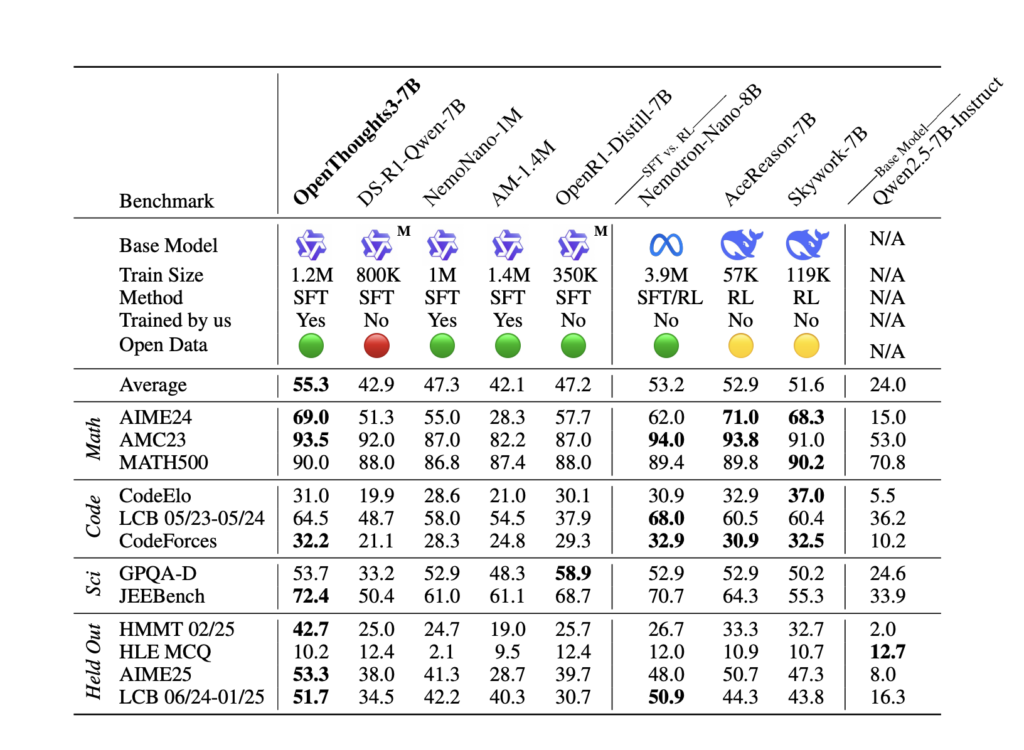
OpenThoughts: A Scalable Supervised Fine-Tuning SFT Data Curation Pipeline for Reasoning Models
Source: MarkTechPost The Growing Complexity of Reasoning Data Curation Recent reasoning models, such as DeepSeek-R1 and o3, have...
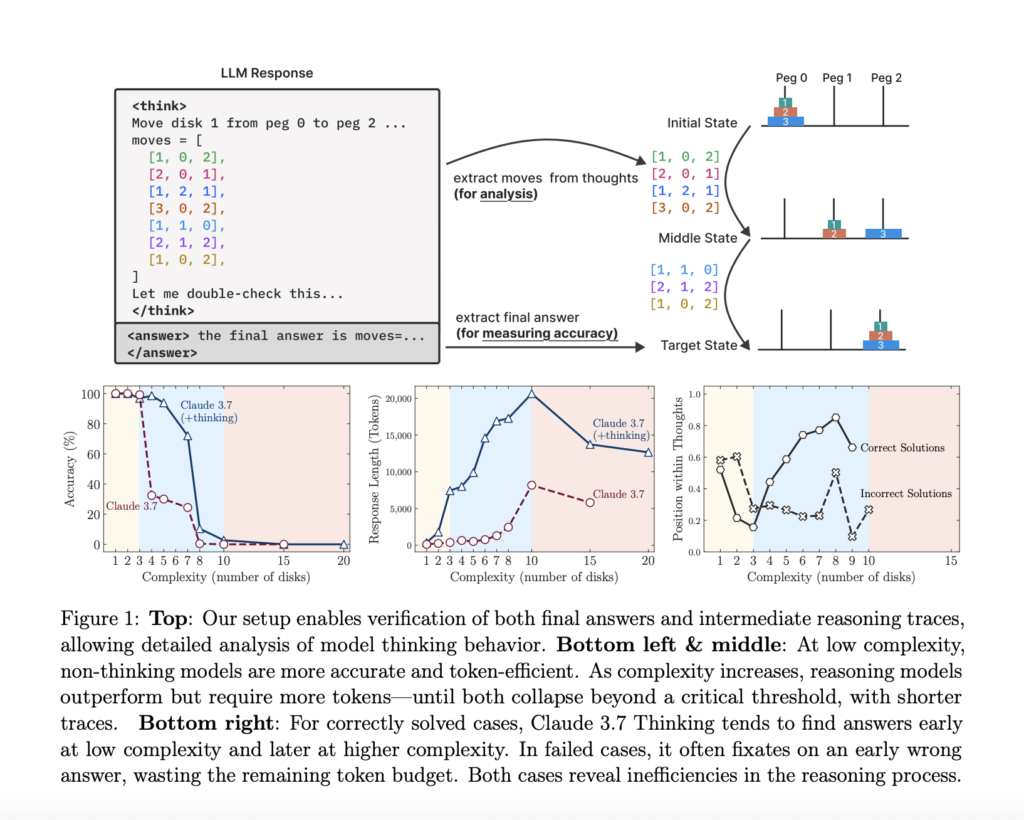
Apple Researchers Reveal Structural Failures in Large Reasoning Models Using Puzzle-Based Evaluation
Source: MarkTechPost Artificial intelligence has undergone a significant transition from basic language models to advanced models that focus...
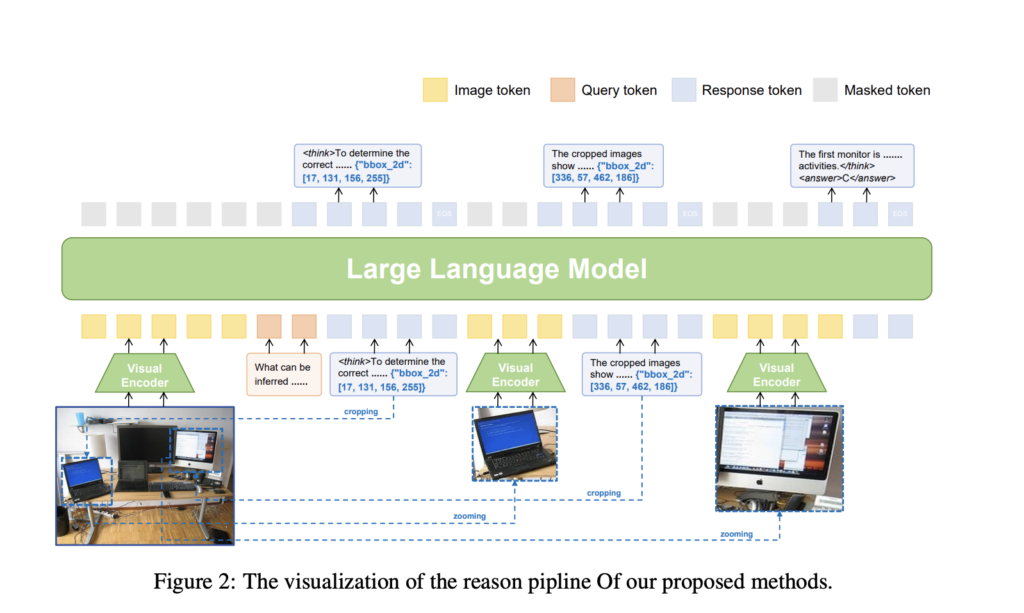
This AI Paper Introduces VLM-R³: A Multimodal Framework for Region Recognition, Reasoning, and Refinement in Visual-Linguistic Tasks
Source: MarkTechPost Multimodal reasoning ability helps machines perform tasks such as solving math problems embedded in diagrams, reading...
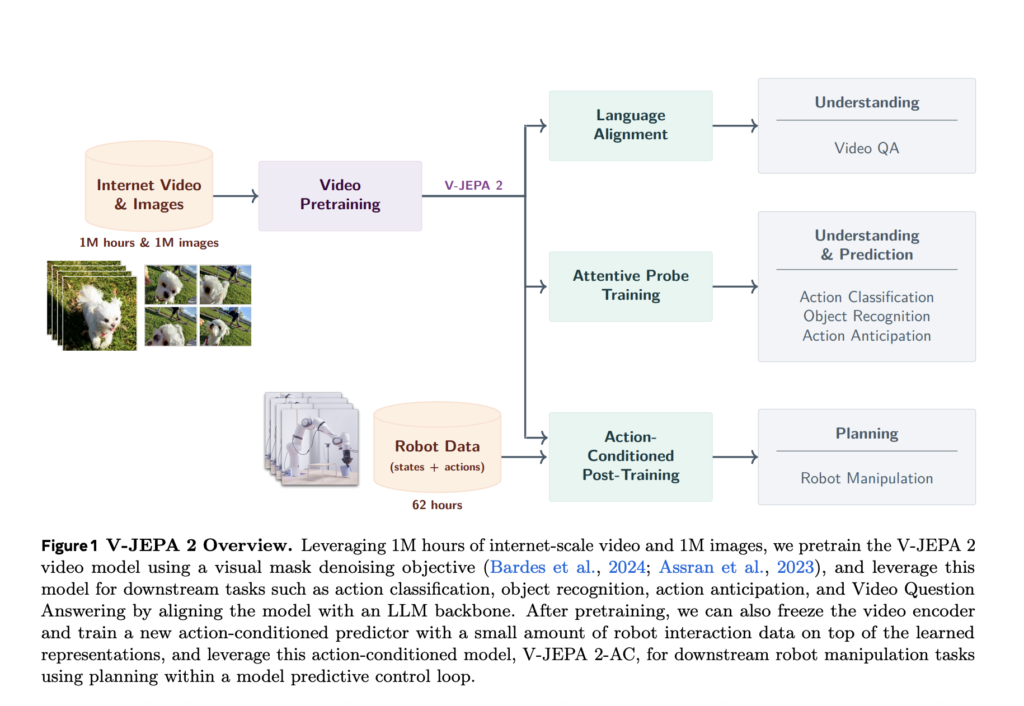
Meta AI Releases V-JEPA 2: Open-Source Self-Supervised World Models for Understanding, Prediction, and Planning
Source: MarkTechPost Meta AI has introduced V-JEPA 2, a scalable open-source world model designed to learn from video...
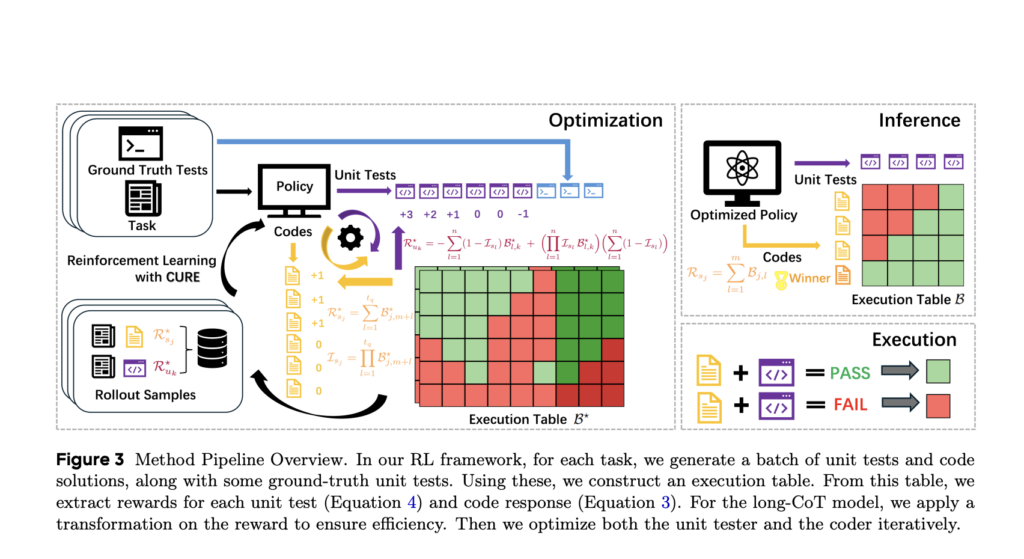
CURE: A Reinforcement Learning Framework for Co-Evolving Code and Unit Test Generation in LLMs
Source: MarkTechPost Introduction Large Language Models (LLMs) have shown substantial improvements in reasoning and precision through reinforcement learning...
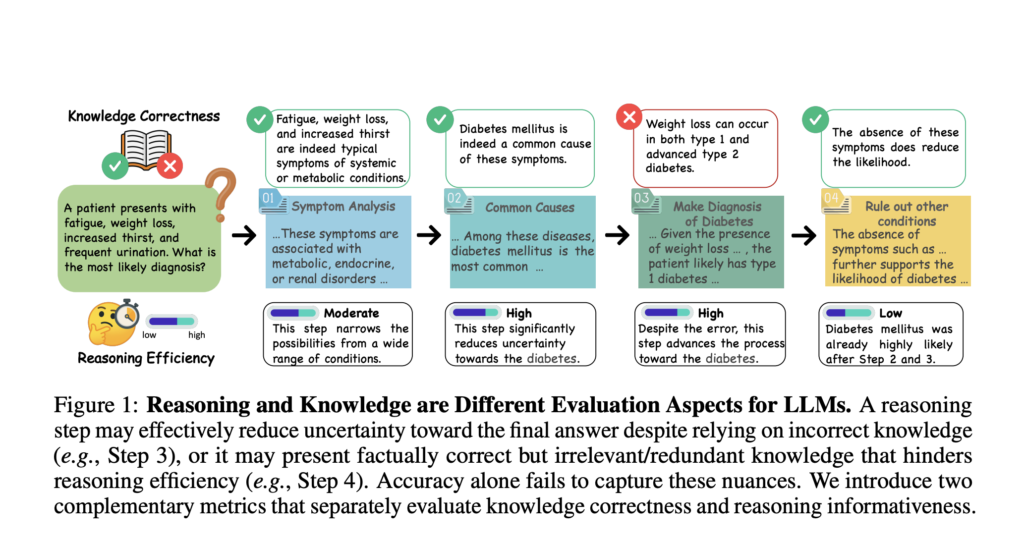
How Do LLMs Really Reason? A Framework to Separate Logic from Knowledge
Source: MarkTechPost Unpacking Reasoning in Modern LLMs: Why Final Answers Aren’t Enough Recent advancements in reasoning-focused LLMs like...

Mistral AI Releases Magistral Series: Advanced Chain-of-Thought LLMs for Enterprise and Open-Source Applications
Source: MarkTechPost Mistral AI has officially introduced Magistral, its latest series of reasoning-optimized large language models (LLMs). This...
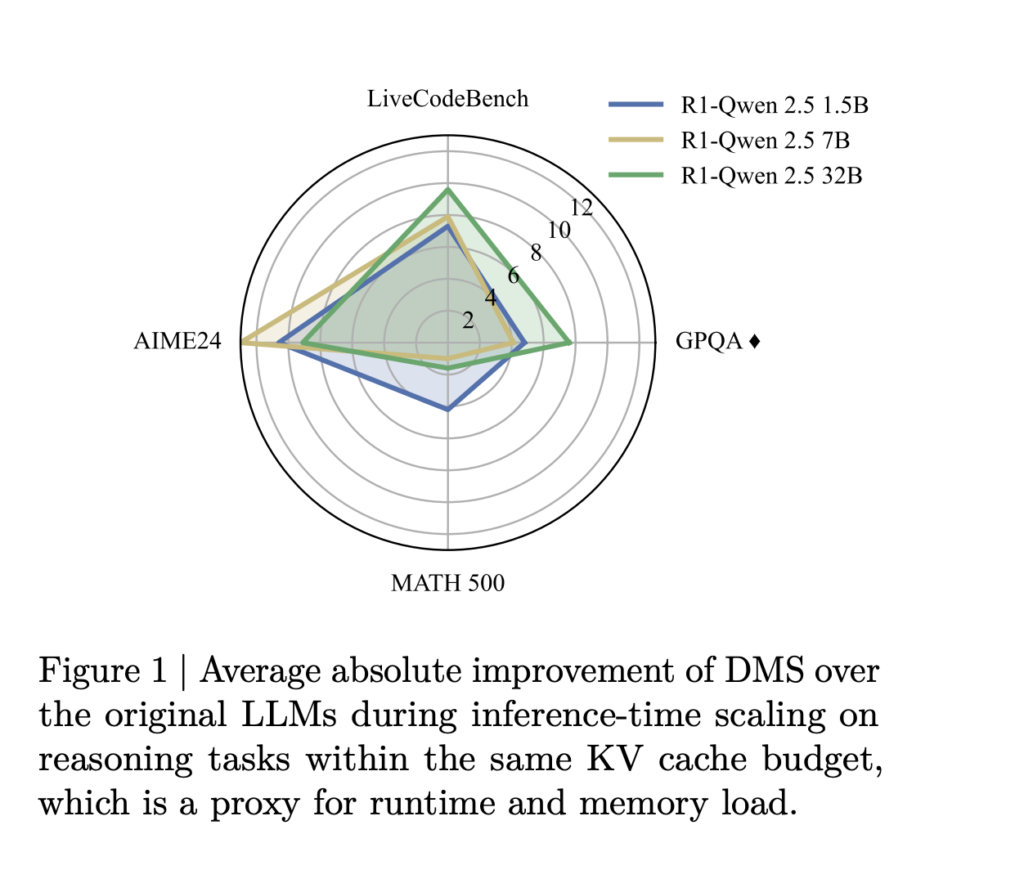
NVIDIA Researchers Introduce Dynamic Memory Sparsification (DMS) for 8× KV Cache Compression in Transformer LLMs
Source: MarkTechPost As the demand for reasoning-heavy tasks grows, large language models (LLMs) are increasingly expected to generate...