
Google Research Introduces SensorFM: A Wearable Health Foundation Model Pretrained on One Trillion Minutes of Sensor Data
Source: MarkTechPost Most wearable health models are built one outcome at a time. That approach breaks down at...
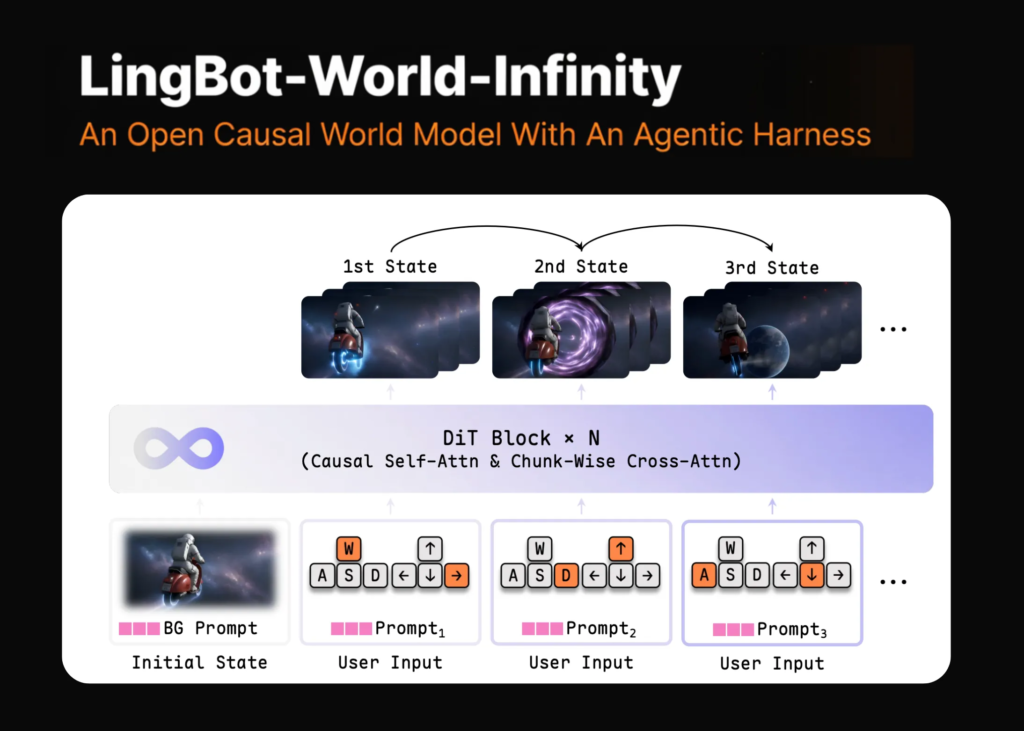
Meet LingBot-World-Infinity: An Open Causal World Model With An Agentic Harness
Source: MarkTechPost Robbyant, Ant Group’s embodied-intelligence unit, has released LingBot-World-Infinity (LingBot-World 2.0). It is a causal video generation...

Meta Superintelligence Labs Releases Muse Spark 1.1: A Multimodal Reasoning Model for Agentic Tasks on Meta Model API
Source: MarkTechPost Today, Meta Superintelligence Labs released Muse Spark 1.1. Alongside it, Meta opened a public preview of...

OpenAI Releases GPT-5.6 (Sol, Terra, Luna): A Three-Tier Model Family With Programmatic Tool Calling in the Responses API
Source: MarkTechPost OpenAI just moved the GPT-5.6 family to general availability, following a limited preview. The release ships...
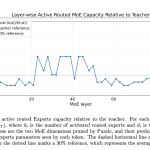
Meet Nemotron Labs 3 Puzzle 75B A9B: A Compressed Hybrid MoE LLM Delivering 2.03x Server Throughput
Source: MarkTechPost Large hybrid MoE models like Nemotron-3-Super are accurate but expensive to serve. Their active parameters, KV...

Tiny robot boats build floating structures
Source: MIT News – Artificial intelligence Most people think of the waterfront as the edge of the city....
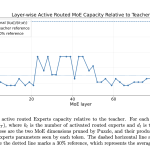
NVIDIA Releases Nemotron-Labs-3-Puzzle-75B-A9B: A Compressed Hybrid MoE LLM Delivering 2.03x Server Throughput at Matched User Throughput
Source: MarkTechPost Large hybrid MoE models like Nemotron-3-Super are accurate but expensive to serve. Their active parameters, KV...

Datalab Lift vs the Field: How a 9B Schema-First Extractor Compares with NuExtract3, LlamaExtract, Marker, and Docling
Source: MarkTechPost Datalab’s Lift is a focused document extraction tool with a specific promise: give it a PDF...

Robbyant Releases LingBot-VLA 2.0: An Open-Source 6B Vision-Language-Action (VLA) Model for Cross-Embodiment Robot Manipulation
Source: MarkTechPost Ant Group’s Robbyant has released LingBot-VLA 2.0, a Vision-Language-Action (VLA) foundation model for robots. The release...

SpaceXAI Releases Grok 4.5, a Cursor-Trained Model for Coding, Agentic Tasks, and Knowledge Work at $2/M Input
Source: MarkTechPost SpaceXAI just released Grok 4.5. The company calls it its smartest model to date. It targets...