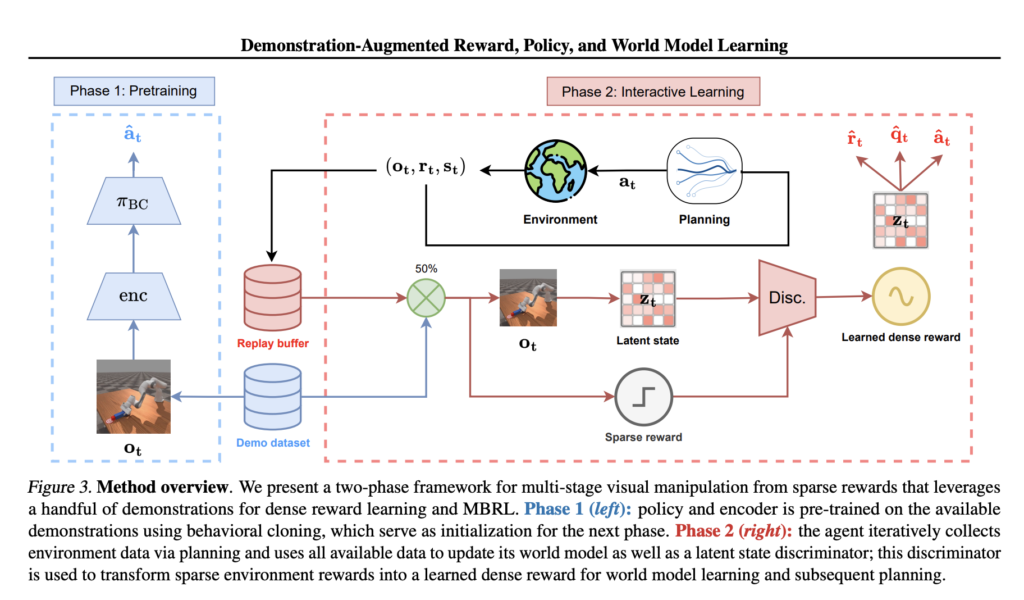
From Sparse Rewards to Precise Mastery: How DEMO3 is Revolutionizing Robotic Manipulation
Source: MarkTechPost Long-horizon robotic manipulation tasks are a serious challenge for reinforcement learning, caused mainly by sparse rewards,...

Building an Interactive Bilingual (Arabic and English) Chat Interface with Open Source Meraj-Mini by Arcee AI: Leveraging GPU Acceleration, PyTorch, Transformers, Accelerate, BitsAndBytes, and Gradio
Source: MarkTechPost In this tutorial, we implement a Bilingual Chat Assistant powered by Arcee’s Meraj-Mini model, which is...

This AI Paper Introduces R1-Searcher: A Reinforcement Learning-Based Framework for Enhancing LLM Search Capabilities
Source: MarkTechPost Large language models (LLMs) models primarily depend on their internal knowledge, which can be inadequate when...

HybridNorm: A Hybrid Normalization Strategy Combining Pre-Norm and Post-Norm Strengths in Transformer Architectures
Source: MarkTechPost Transformers have revolutionized natural language processing as the foundation of large language models (LLMs), excelling in...
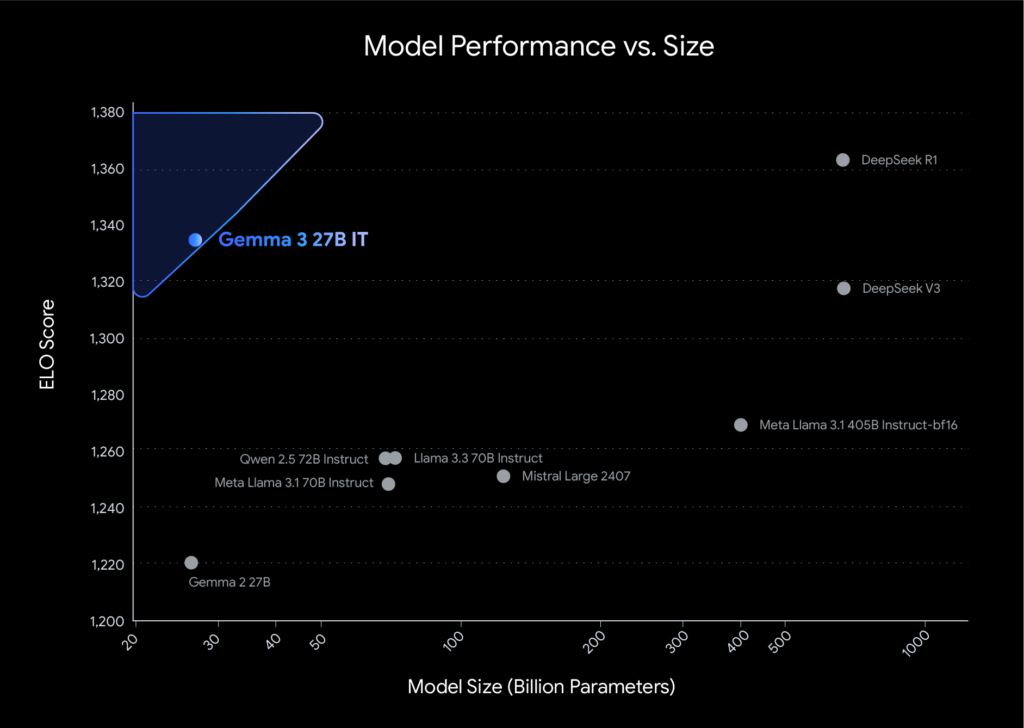
Google AI Releases Gemma 3: Lightweight Multimodal Open Models for Efficient and On‑Device AI
Source: MarkTechPost In the field of artificial intelligence, two persistent challenges remain. Many advanced language models require significant...

Hugging Face Releases OlympicCoder: A Series of Open Reasoning AI Models that can Solve Olympiad-Level Programming Problems
Source: MarkTechPost In the realm of competitive programming, both human participants and artificial intelligence systems encounter a set...
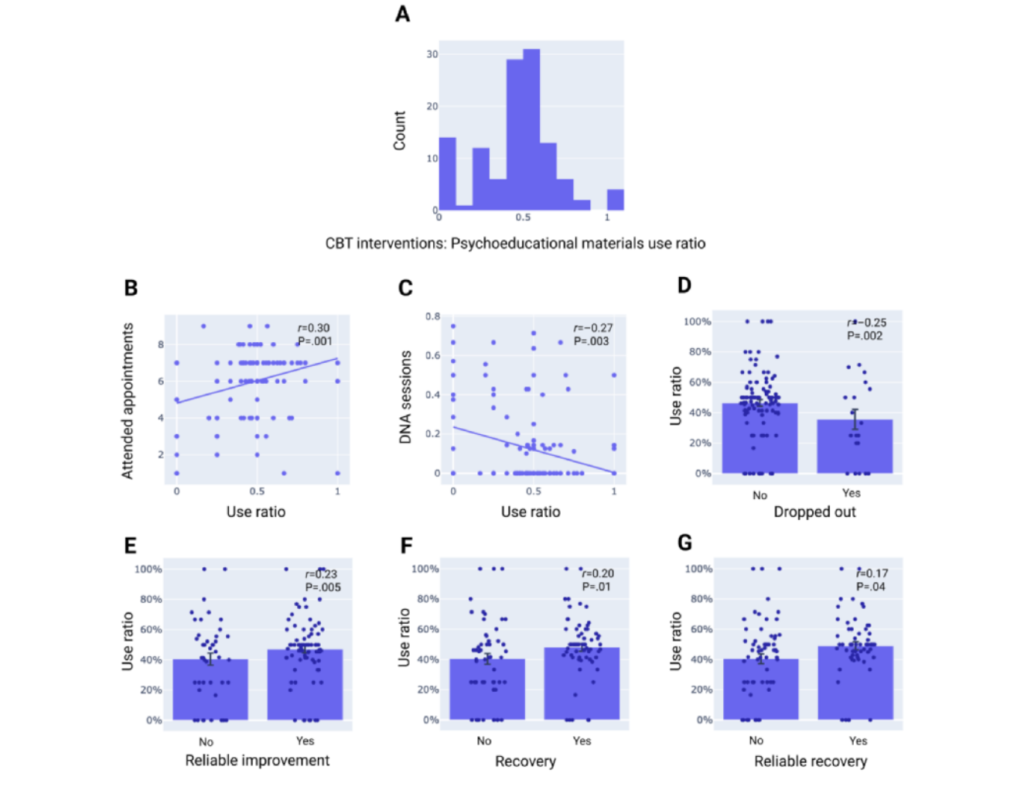
Limbic AI’s Generative AI–Enabled Therapy Support Tool Improves Cognitive Behavioral Therapy Outcomes
Source: MarkTechPost Recent advancements in generative AI are creating exciting new possibilities in healthcare, especially within mental health...
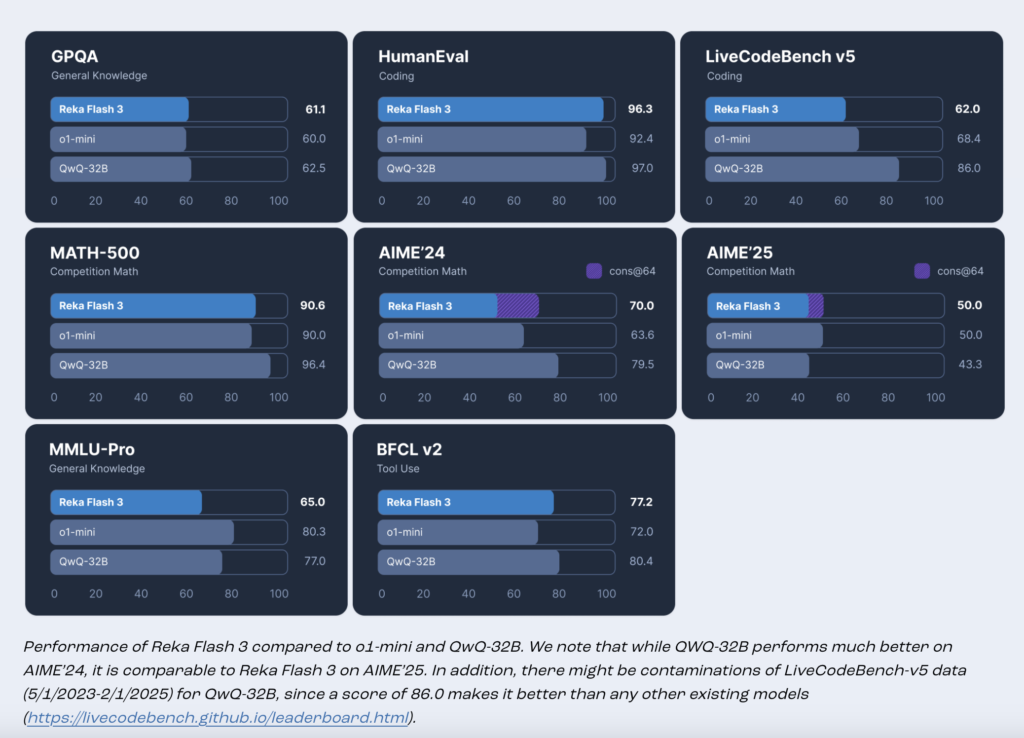
Reka AI Open Sourced Reka Flash 3: A 21B General-Purpose Reasoning Model that was Trained from Scratch
Source: MarkTechPost In today’s dynamic AI landscape, developers and organizations face several practical challenges. High computational demands, latency...
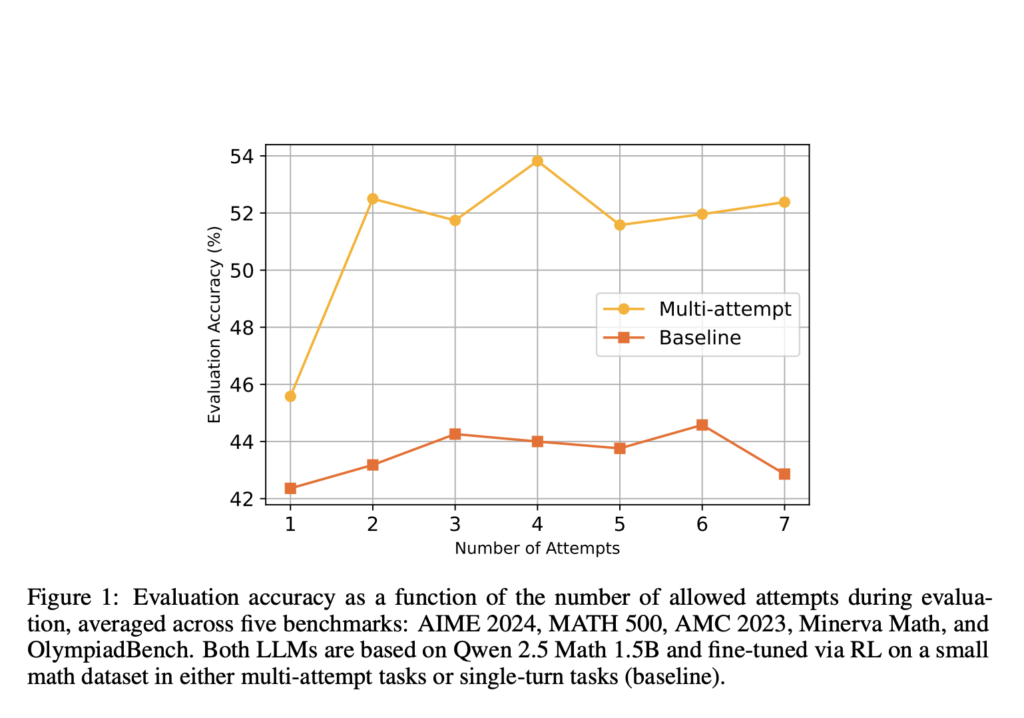
Enhancing LLM Reasoning with Multi-Attempt Reinforcement Learning
Source: MarkTechPost Recent advancements in RL for LLMs, such as DeepSeek R1, have demonstrated that even simple question-answering...

What if You Could Control How Long a Reasoning Model “Thinks”? CMU Researchers Introduce L1-1.5B: Reinforcement Learning Optimizes AI Thought Process
Source: MarkTechPost Reasoning language models have demonstrated the ability to enhance performance by generating longer chain-of-thought sequences during...