
Improving the speed and energy-efficiency of AI agents
Source: MIT News – Artificial intelligence Agentic workflows are artificial intelligence-powered software systems that chain together multiple models...

16 Best Generative AI Coding Tools in 2026 Compared: Features, and Best Fit
Source: MarkTechPost Generative AI has reshaped how software gets built. What began as line-by-line autocomplete now spans full...
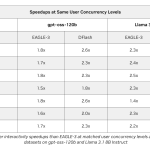
DFlash Speculative Decoding Drafts Whole Token Blocks in Parallel for Up to 15x Higher Throughput on NVIDIA Blackwell
Source: MarkTechPost Autoregressive large language models generate text one token at a time. Each token waits for the...

Datalab Releases lift: A 9B Open-Weights Vision Model That Extracts Structured JSON From PDFs Using Schemas
Source: MarkTechPost Datalab has released lift, a 9B open-weights vision model for structured extraction. You pass it a...

Prime Intellect Releases prime-rl 0.6.0 to Train Trillion-Parameter MoE Models on Agentic RL Workloads
Source: MarkTechPost Prime Intellect has released prime-rl version 0.6.0. The framework targets reinforcement learning on trillion-parameter Mixture-of-Experts (MoE)...

GLM-5.2 OpenAI-Compatible API: A Hands-On Guide to Reasoning Effort, Function Calling, and Long-Context Retrieval
Source: MarkTechPost In this tutorial, we work with GLM-5.2 and use its hosted, OpenAI-compatible API instead of running...

New chip could help tiny robots traverse complex environments
Source: MIT News – Artificial intelligence A new chip developed by MIT researchers could help tiny, low-power UAVs...

Yandex Open-Sources YaFF: A Zero-Copy Wire Format for Protobuf With Near-Struct Read Speed
Source: MarkTechPost TLDR YaFF is Yandex’s open-source zero-copy wire format for Protobuf — Apache 2.0, currently C++, v0.1.0....
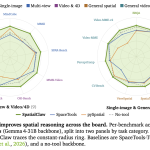
NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning
Source: MarkTechPost NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness...
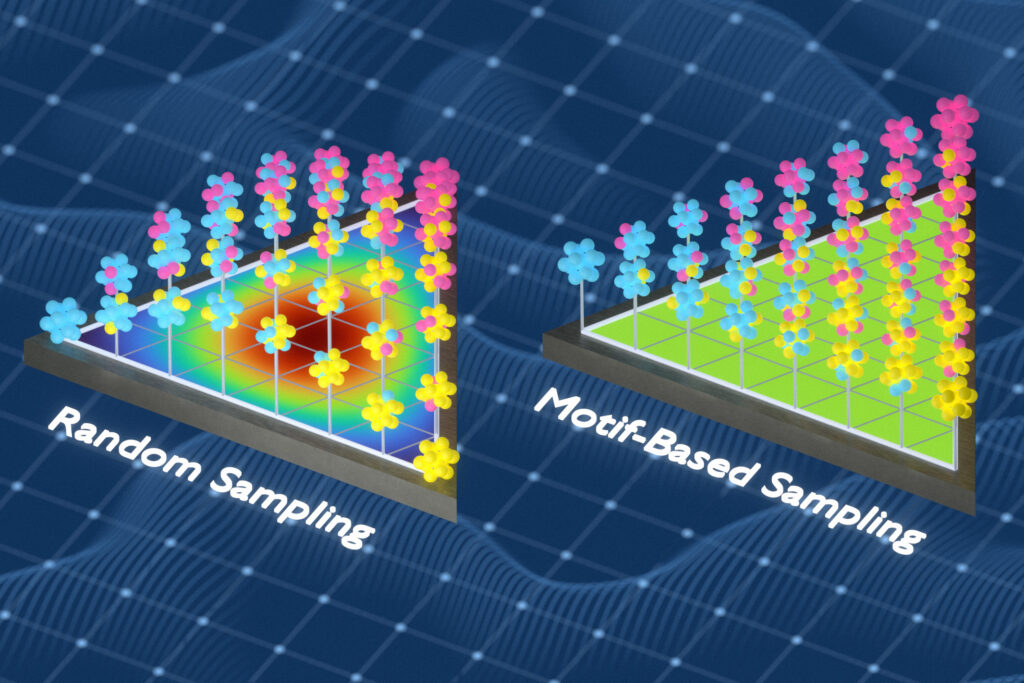
A better way to model the behavior of metal alloys
Source: MIT News – Artificial intelligence Companies working at the frontier of aerospace, energy, and computing are constantly...