Source: MarkTechPost
Autoregressive large language models generate text one token at a time. Each token waits for the one before it. This serial loop leaves modern GPUs underused and keeps inference slow. The cost grows worse with long Chain-of-Thought reasoning models. Their lengthy outputs make latency the dominant part of generation.
Speculative decoding is the standard fix. A small draft model proposes future tokens. The large target model verifies those tokens in parallel. Accepted tokens are kept, so the output stays lossless. But most methods, including the state-of-the-art EAGLE-3, still draft autoregressively. That serial drafting caps real-world speedups near 2–3×.
DFlash, introduced by research team from UC San Diego team (z-lab), takes a different route. It is a lightweight block diffusion model built for drafting. Instead of drafting tokens one at a time, it proposes a whole block in a single forward pass. The target model then verifies that block in parallel.
The research team reports over 6× lossless acceleration across a range of models and tasks. It reaches up to 2.5× higher speedup than EAGLE-3. On NVIDIA Blackwell, NVIDIA engineering team reports up to 15× higher throughput for gpt-oss-120b. That figure holds at the same user interactivity target.

What block diffusion drafting changes
Block diffusion models denoise a block of masked tokens at once. They blend parallel generation with autoregressive block structure. DFlash applies this idea only to the drafting stage. Verification stays with the trusted autoregressive target model.
This split matters for quality. Standalone diffusion LLMs often trail autoregressive models on accuracy. They also need many denoising steps, which slows their raw inference speed. DFlash sidesteps both problems. The draft only needs to be good enough to be accepted. The target’s parallel verification guarantees the final output distribution.
A second benefit is drafting cost. An autoregressive drafter’s cost grows linearly with the number of speculative tokens. A diffusion drafter generates all tokens in one parallel pass. So drafting latency stays largely flat as the block grows. This frees DFlash to use deeper, more expressive draft models without adding latency.
This separates DFlash from earlier diffusion-drafter work. Methods like DiffuSpec and SpecDiff-2 used massive 7B drafters, capping speedups near 3–4×. DFlash instead uses a small five-layer drafter (eight layers for Qwen3-Coder).
The “target knows best” insight
DFlash’s core idea is simple: the target knows best. Large autoregressive models’ hidden features encode information about multiple future tokens. DFlash extracts hidden states from several target layers. It fuses them into one compact target context feature. This feature then conditions the draft model.
DFlash injects this feature differently than EAGLE-3. EAGLE-3 fuses target features into the draft’s input embeddings only. As draft depth grows, that signal gets diluted. DFlash instead injects the feature into the Key and Value projections of every draft layer. The projected features sit in the draft’s KV cache and persist across drafting iterations.
This KV injection lets acceptance length scale with draft depth. A five-layer DFlash drafter generating 16 tokens beats EAGLE-3 generating 8 tokens. It is both lower-latency and higher-acceptance in the paper’s tests. The draft model effectively becomes a diffusion adapter on top of the target.
Two speedup numbers, measured differently
The DFlash research’s 6× is single-stream lossless acceleration. On Qwen3-8B with greedy decoding (Transformers backend), DFlash averages a 4.86× speedup. EAGLE-3 averages 1.76× at tree size 16 and 2.02× at tree size 60. DFlash peaks at 6.08× on MATH-500 (τ = 7.87) and averages τ = 6.49 across tasks.
NVIDIA’s 15× is throughput at a fixed interactivity target. It applies to gpt-oss-120b on eight NVIDIA Blackwell GPUs in a DGX B300 system, using TensorRT-LLM. At the 500–600 tokens/sec per-user range, DFlash serves more than 15× the throughput of autoregressive decoding. That is about 1.5× more than EAGLE-3 at the same point.
The table below shows the paper’s per-task speedups on Qwen3-8B at temperature 0 (Transformers backend).
| Task (Qwen3-8B, temp=0) | Baseline | EAGLE-3 (16) | DFlash (16) | DFlash τ |
|---|---|---|---|---|
| GSM8K | 1.00× | 1.94× | 5.15× | 6.54 |
| MATH-500 | 1.00× | 1.81× | 6.08× | 7.87 |
| AIME25 | 1.00× | 1.79× | 5.62× | 7.08 |
| HumanEval | 1.00× | 1.89× | 5.14× | 6.50 |
| MBPP | 1.00× | 1.69× | 4.65× | 5.95 |
| LiveCodeBench | 1.00× | 1.57× | 5.51× | 7.27 |
| MT-Bench | 1.00× | 1.63× | 2.75× | 4.24 |
| Average | 1.00× | 1.76× | 4.86× | 6.49 |
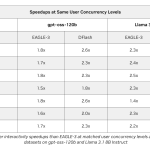
A separate NVIDIA Speed-Bench comparison measures interactivity speedups at matched concurrency. On gpt-oss-120b, DFlash averages 2.3× versus EAGLE-3’s 1.7×. On Llama 3.1 8B Instruct, DFlash averages 2.8× versus EAGLE-3’s 2.2×.
Use cases with examples
DFlash targets latency-sensitive serving where token-by-token generation hurts. Three patterns fit well:
- Coding agents: Code generation needs fast, interactive responses. On Gemma 4 31B with vLLM, NVIDIA reports up to 5.8× on Math500 at concurrency 1. HumanEval reaches 5.6×. Faster drafts mean shorter wait times inside agent loops.
- Reasoning models: Long Chain-of-Thought traces dominate generation time. With thinking mode enabled, DFlash holds roughly 4.5× under greedy decoding on Qwen3-4B and Qwen3-8B. Under sampling, it holds about 3.9×. This cuts the cost of long reasoning outputs.
- Serving and throughput: DFlash also raises serving throughput. On SGLang with a B200 GPU, it reaches up to 5.1× on Qwen3-8B (Math500, concurrency 1). Gains taper as concurrency rises but stay positive, so serving cost still drops.
Running DFlash
DFlash ships with checkpoints and framework support, so adoption needs little code. On vLLM, you swap an EAGLE-3 config for a DFlash one. No application refactoring is required.
vllm serve Qwen/Qwen3.5-27B --speculative-config '{"method": "dflash", "model": "z-lab/Qwen3.5-27B-DFlash", "num_speculative_tokens": 15}' --attention-backend flash_attn --max-num-batched-tokens 32768The Transformers backend supports Qwen3 and LLaMA-3.1 models. It exposes a spec_generate call that pairs a draft model with a target model.
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer draft = AutoModel.from_pretrained( "z-lab/Qwen3-8B-DFlash-b16", trust_remote_code=True, dtype="auto", device_map="cuda:0").eval() target = AutoModelForCausalLM.from_pretrained( "Qwen/Qwen3-8B", dtype="auto", device_map="cuda:0").eval() tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B") messages = [{"role": "user", "content": "How many positive whole-number divisors does 196 have?"}] input_ids = tokenizer.apply_chat_template( messages, return_tensors="pt", add_generation_prompt=True, enable_thinking=False).to(draft.device) output = draft.spec_generate( input_ids=input_ids, max_new_tokens=2048, temperature=0.0, target=target, stop_token_ids=[tokenizer.eos_token_id]) print(tokenizer.decode(output[0], skip_special_tokens=False))Key Takeaways
- DFlash drafts an entire token block in one forward pass, not one token at a time.
- It injects target hidden features into every draft layer’s KV cache, scaling acceptance length with depth.
- Research Paper’s metrics: up to 6.08× lossless speedup on Qwen3-8B; NVIDIA test: up to 15× throughput on Blackwell at fixed interactivity.
- A lightweight five-layer drafter replaces the 7B drafters that capped earlier diffusion methods near 3–4×.
Interactive Explainer
Check out the Project page, Paper (arXiv 2602.06036), GitHub, Hugging Face checkpoints and NVIDIA blog. Also, feel free to follow us on Twitter and don’t forget to join our 150k+ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Need to partner with us for promoting your GitHub Repo OR Hugging Face Page OR Product Release OR Webinar etc.? Connect with us