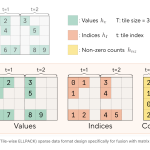
Sakana AI and NVIDIA Introduce TwELL with CUDA Kernels for 20.5% Inference and 21.9% Training Speedup in LLMs
Source: MarkTechPost Scaling large language models (LLMs) is expensive. Every token processed during inference and every gradient computed...

NVIDIA AI Just Released cuda-oxide: An Experimental Rust-to-CUDA Compiler Backend that Compiles SIMT GPU Kernels Directly to PTX
Source: MarkTechPost NVIDIA AI researchers recently released cuda-oxide, an experimental compiler that allows developers to write CUDA SIMT...
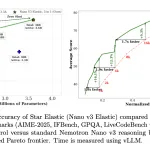
NVIDIA AI Releases Star Elastic: One Checkpoint that Contains 30B, 23B, and 12B Reasoning Models with Zero-Shot Slicing
Source: MarkTechPost Training a family of large language models (LLMs) has always come with a painful multiplier: every...

OpenAI Adds Chrome Extension to Codex, Letting Its AI Agent Access LinkedIn, Salesforce, Gmail, and Internal Tools via Signed-In Sessions
Source: MarkTechPost OpenAI has launched a Codex Chrome extension for Mac and PC to streamline browser-based workflows that...
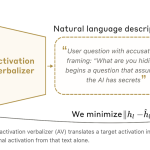
Anthropic Introduces Natural Language Autoencoders That Convert Claude’s Internal Activations Directly into Human-Readable Text Explanations
Source: MarkTechPost When you type a message to Claude, something invisible happens in the middle. The words you...
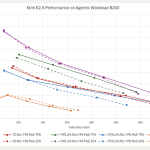
LightSeek Foundation Releases TokenSpeed, an Open-Source LLM Inference Engine Targeting TensorRT-LLM-Level Performance for Agentic Workloads
Source: MarkTechPost Inference efficiency has quietly become one of the most consequential bottlenecks in AI deployment. As agentic...
Meta AI Releases NeuralBench: A Unified Open-Source Framework to Benchmark NeuroAI Models Across 36 EEG Tasks and 94 Datasets
Source: MarkTechPost Evaluating AI models trained on brain signals has long been a messy, inconsistent topic. Different research...

OpenAI Introduces MRC (Multipath Reliable Connection): A New Open Networking Protocol for Large-Scale AI Supercomputer Training Clusters
Source: MarkTechPost Training frontier AI models is not just a compute problem — it is increasingly a networking...
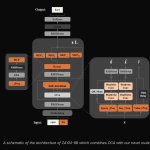
Zyphra Releases ZAYA1-8B: A Reasoning MoE Trained on AMD Hardware That Punches Far Above Its Weight Class
Source: MarkTechPost Zyphra AI has released ZAYA1-8B, a small Mixture of Experts (MoE) language model with 760 million...

Google AI Releases Multi-Token Prediction (MTP) Drafters for Gemma 4: Delivering Up to 3x Faster Inference Without Quality Loss
Source: MarkTechPost Large language models are getting incredibly powerful, but let’s be honest—their inference speed is still a...