
Nous Research Releases ‘Hermes Agent’ to Fix AI Forgetfulness with Multi-Level Memory and Dedicated Remote Terminal Access Support
Source: MarkTechPost In the current AI landscape, we’ve become accustomed to the ‘ephemeral agent’—a brilliant but forgetful assistant...
Tailscale and LM Studio Introduce ‘LM Link’ to Provide Encrypted Point-to-Point Access to Your Private GPU Hardware Assets
Source: MarkTechPost For the modern AI developer productivity is often tied to a physical location. You likely have...

How to Build an Elastic Vector Database with Consistent Hashing, Sharding, and Live Ring Visualization for RAG Systems
Source: MarkTechPost In this tutorial, we build an elastic vector database simulator that mirrors how modern RAG systems...
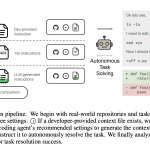
New ETH Zurich Study Proves Your AI Coding Agents are Failing Because Your AGENTS.md Files are too Detailed
Source: MarkTechPost In the high-stakes world of AI, ‘Context Engineering’ has emerged as the latest frontier for squeezing...
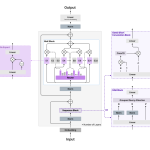
Liquid AI’s New LFM2-24B-A2B Hybrid Architecture Blends Attention with Convolutions to Solve the Scaling Bottlenecks of Modern LLMs
Source: MarkTechPost The generative AI race has long been a game of ‘bigger is better.’ But as the...
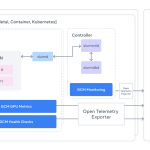
Meta AI Open Sources GCM for Better GPU Cluster Monitoring to Ensure High Performance AI Training and Hardware Reliability
Source: MarkTechPost While the tech folks obsesses over the latest Llama checkpoints, a much grittier battle is being...
A Coding Implementation to Simulate Practical Byzantine Fault Tolerance with Asyncio, Malicious Nodes, and Latency Analysis
Source: MarkTechPost In this tutorial, we implement an end-to-end Practical Byzantine Fault Tolerance (PBFT) simulator using asyncio. We...

Alibaba Qwen Team Releases Qwen 3.5 Medium Model Series: A Production Powerhouse Proving that Smaller AI Models are Smarter
Source: MarkTechPost The development of large language models (LLMs) has been defined by the pursuit of raw scale....
Google DeepMind Researchers Apply Semantic Evolution to Create Non Intuitive VAD-CFR and SHOR-PSRO Variants for Superior Algorithmic Convergence
Source: MarkTechPost In the competitive arena of Multi-Agent Reinforcement Learning (MARL), progress has long been bottlenecked by human...

RAG vs. Context Stuffing: Why selective retrieval is more efficient and reliable than dumping all data into the prompt
Source: MarkTechPost Large context windows have dramatically increased how much information modern language models can process in a...