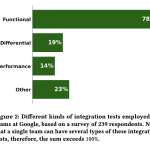
Google AI Releases Auto-Diagnose: An Large Language Model LLM-Based System to Diagnose Integration Test Failures at Scale
Source: MarkTechPost If you have ever stared at thousands of lines of integration test logs wondering which of...

A End-to-End Coding Guide to Running OpenAI GPT-OSS Open-Weight Models with Advanced Inference Workflows
Source: MarkTechPost In this tutorial, we explore how to run OpenAI’s open-weight GPT-OSS models in Google Colab with...

Top 19 AI Red Teaming Tools (2026): Secure Your ML Models
Source: MarkTechPost Table of contents What Is AI Red Teaming? Top 19 AI Red Teaming Tools (2026) Conclusion...
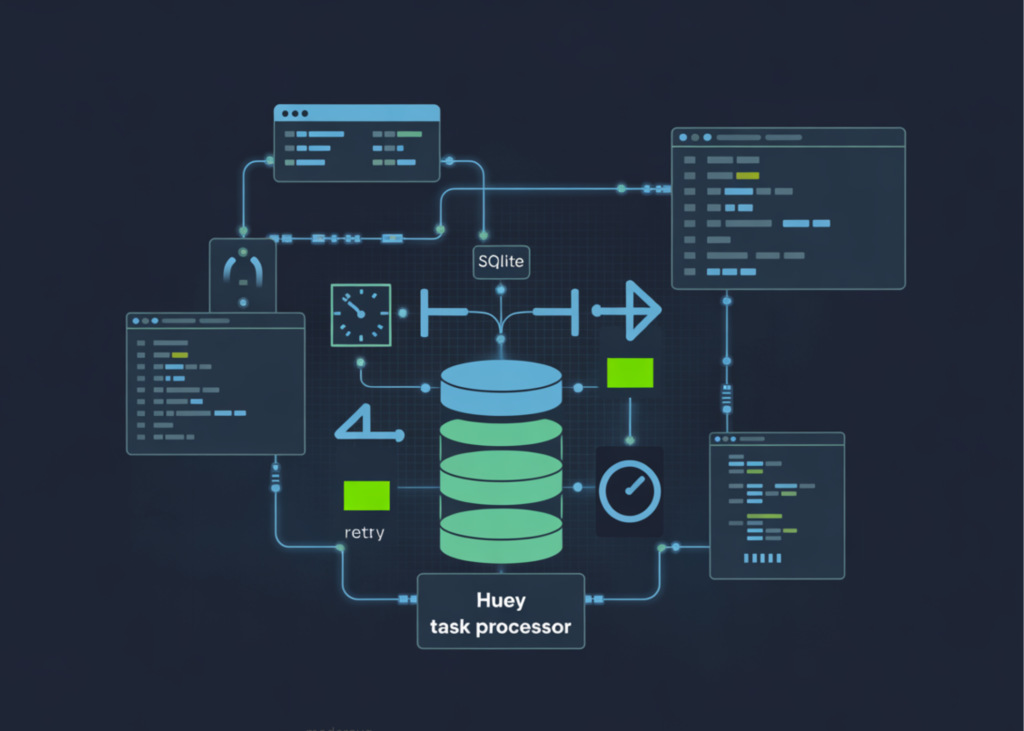
A Coding Guide to Build a Production-Grade Background Task Processing System Using Huey with SQLite, Scheduling, Retries, Pipelines, and Concurrency Control
Source: MarkTechPost In this tutorial, we explore how to build a fully functional background task processing system using...

Qwen Team Open-Sources Qwen3.6-35B-A3B: A Sparse MoE Vision-Language Model with 3B Active Parameters and Agentic Coding Capabilities
Source: MarkTechPost The open-source AI landscape has a new entry worth paying attention to. The Qwen team at...

OpenAI Launches GPT-Rosalind: Its First Life Sciences AI Model Built to Accelerate Drug Discovery and Genomics Research
Source: MarkTechPost Drug discovery is one of the most expensive and time-consuming endeavors in human history. It takes...
Building Transformer-Based NQS for Frustrated Spin Systems with NetKet
Source: MarkTechPost The intersection of many-body physics and deep learning has opened a new frontier: Neural Quantum States...
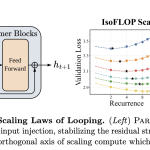
UCSD and Together AI Research Introduces Parcae: A Stable Architecture for Looped Language Models That Achieves the Quality of a Transformer Twice the Size
Source: MarkTechPost The dominant recipe for building better language models has not changed much since the Chinchilla era:...

How to Build a Universal Long-Term Memory Layer for AI Agents Using Mem0 and OpenAI
Source: MarkTechPost In this tutorial, we build a universal long-term memory layer for AI agents using Mem0, OpenAI...
A Coding Implementation to Build Multi-Agent AI Systems with SmolAgents Using Code Execution, Tool Calling, and Dynamic Orchestration
Source: MarkTechPost In this tutorial, we build an advanced, production-ready agentic system using SmolAgents and demonstrate how modern,...