
Better Code Merging with Less Compute: Meet Osmosis-Apply-1.7B from Osmosis AI
Source: MarkTechPost Osmosis AI has open-sourced Osmosis-Apply-1.7B, a fine-tuned variant of Qwen3-1.7B, designed to perform highly accurate and...

ByteDance Just Released Trae Agent: An LLM-based Agent for General Purpose Software Engineering Tasks
Source: MarkTechPost ByteDance, the Chinese tech giant behind TikTok and other global platforms, has officially released Trae Agent,...
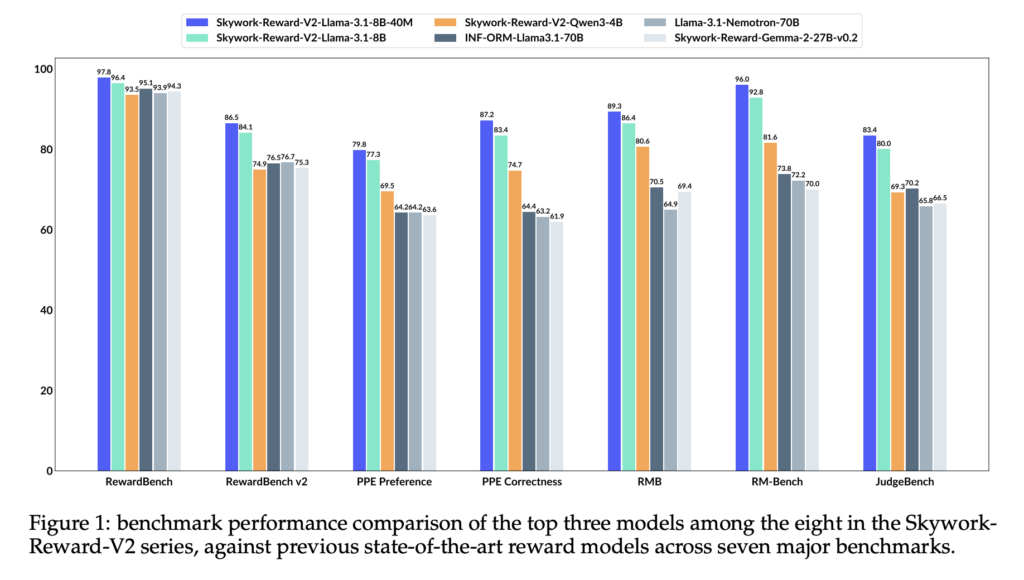
SynPref-40M and Skywork-Reward-V2: Scalable Human-AI Alignment for State-of-the-Art Reward Models
Source: MarkTechPost Understanding Limitations of Current Reward Models Although reward models play a crucial role in Reinforcement Learning...

New AI Method From Meta and NYU Boosts LLM Alignment Using Semi-Online Reinforcement Learning
Source: MarkTechPost Optimizing LLMs for Human Alignment Using Reinforcement Learning Large language models often require a further alignment...
What Is Context Engineering in AI? Techniques, Use Cases, and Why It Matters
Source: MarkTechPost Introduction: What is Context Engineering? Context engineering refers to the discipline of designing, organizing, and manipulating...

Chai Discovery Team Releases Chai-2: AI Model Achieves 16% Hit Rate in De Novo Antibody Design
Source: MarkTechPost TLDR: Chai Discovery Team introduces Chai-2, a multimodal AI model that enables zero-shot de novo antibody...

AbstRaL: Teaching LLMs Abstract Reasoning via Reinforcement to Boost Robustness on GSM Benchmarks
Source: MarkTechPost Recent research indicates that LLMs, particularly smaller ones, frequently struggle with robust reasoning. They tend to...
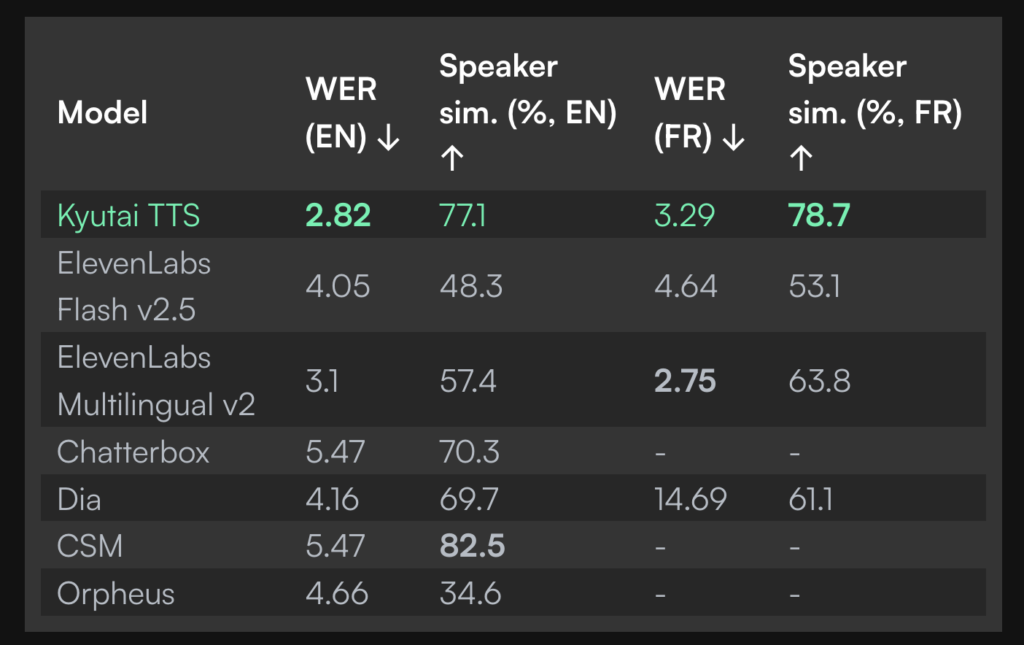
Kyutai Releases 2B Parameter Streaming Text-to-Speech TTS with 220ms Latency and 2.5M Hours of Training
Source: MarkTechPost Kyutai, an open AI research lab, has released a groundbreaking streaming Text-to-Speech (TTS) model with ~2...

Can We Improve Llama 3’s Reasoning Through Post-Training Alone? ASTRO Shows +16% to +20% Benchmark Gains
Source: MarkTechPost Improving the reasoning capabilities of large language models (LLMs) without architectural changes is a core challenge...

Crome: Google DeepMind’s Causal Framework for Robust Reward Modeling in LLM Alignment
Source: MarkTechPost Reward models are fundamental components for aligning LLMs with human feedback, yet they face the challenge...